Same AI model, so why does one company compound its gains while another gets basically nothing
- A salesperson gets a complete client briefing seconds before the phone rings — behind it, AI has been wired into the company's real data flows. Those few seconds are a microcosm of everything this book is about
- Anthropic's ebook names the gap between "using AI" and "compounding with AI": the agentic thinking divide. With adoption doubling every two years, who's using it no longer differentiates anyone
- Point solutions are inevitably mediocre: generic AI produces generic output, employees get something they "still have to fix" — the gap isn't the model, it's how much organizational context gets fed in
- Each of the three pillars has real evidence: L'Oréal's conversational analytics accuracy hit 99.9%, Lyft's support resolution time dropped 87%, Rakuten went from quarterly to biweekly major releases
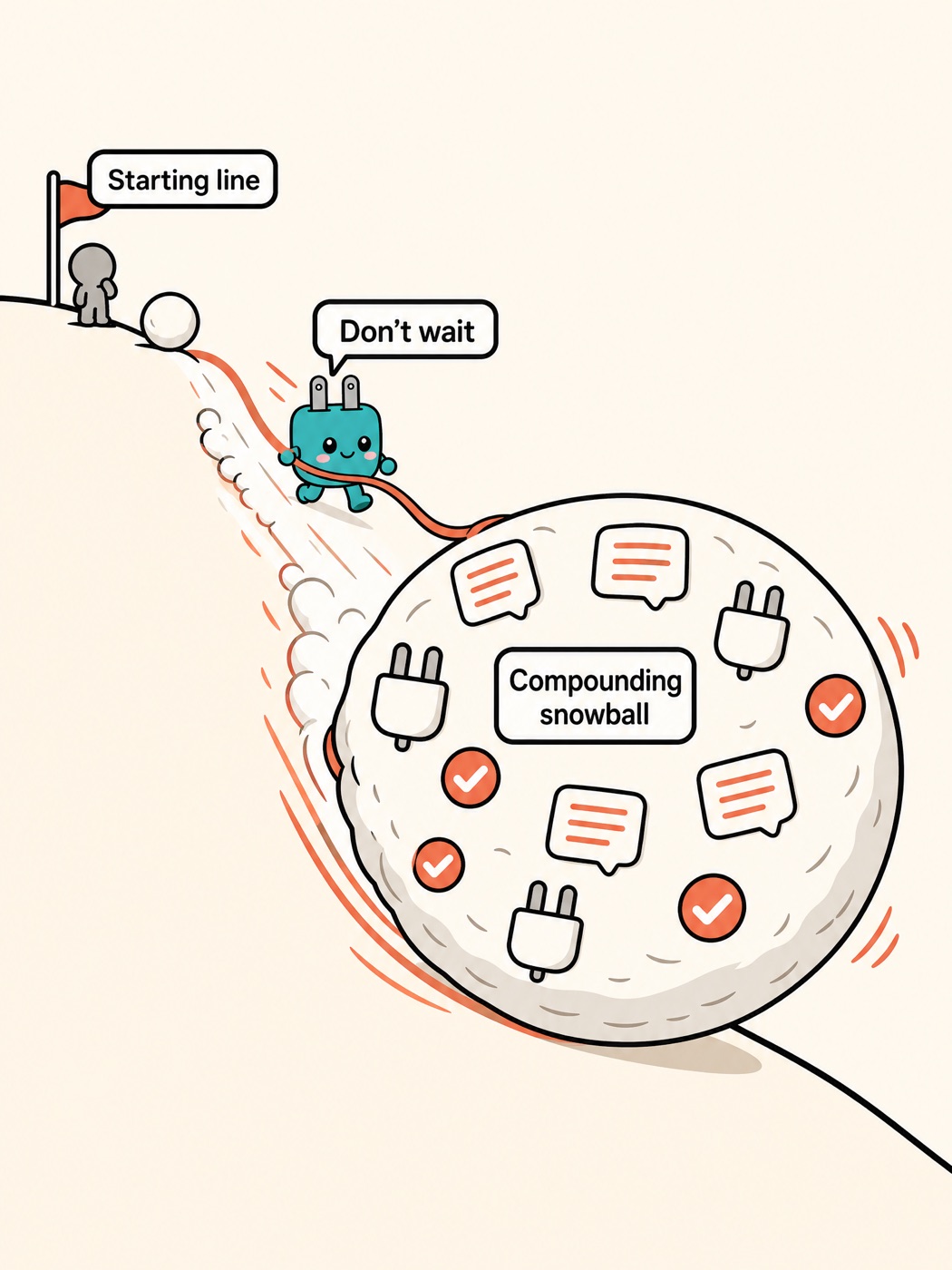
- This advantage compounds: expert feedback flows back into the knowledge base, pushing the capability curve upward; starting a year late doesn't cost you a year — it costs you a year of compounding
- The four action principles and the six-month, three-phase timeline are reproduced in full at the end — copy them directly
What happens in the seconds before the phone rings
A salesperson sits at his desk. The phone is a few seconds from ringing. On the other end is a client he's been chasing for six months.
Three months ago, this moment would have been chaos: five or six tabs open, digging through the CRM for this account's history, scrubbing meeting recordings for what was said last time, then switching to a research tool to check whether the client had raised funding recently or whether a competitor had slipped onto their vendor list. That whole manual routine used to take hours, and often he'd only manage a quick glance before the phone rang.
This time, he typed one command before the call. A few seconds later, a briefing appeared: the company's latest numbers, his full interaction history with this contact, exactly where the still-open deal was stuck, what a competitor had recently been pitching them. He picked up his water glass, unhurried, and answered the call.
Enterprises are long past "should we use AI"
Anthropic published an enterprise ebook called Building AI agents for the enterprise, subtitled "Best practices from industry leaders." It puts into words something that's been quietly happening but rarely gets said out loud.
When a technology's adoption rate doubles in two years and keeps accelerating, who's using it and how much no longer differentiates anyone. What actually separates companies now is a different question: are you treating AI as a tool sitting on a desk, or as the underlying capability that reorganizes your entire company?
The book pulls that variable out and gives it a name: the agentic thinking divide. Below, we follow its two sharpest claims — why scope decides everything, and why this advantage compounds — and unpack them layer by layer. You won't need to memorize the conclusions; you'll be able to derive them yourself.
Adoption vs. transformation: the difference is obvious at a glance
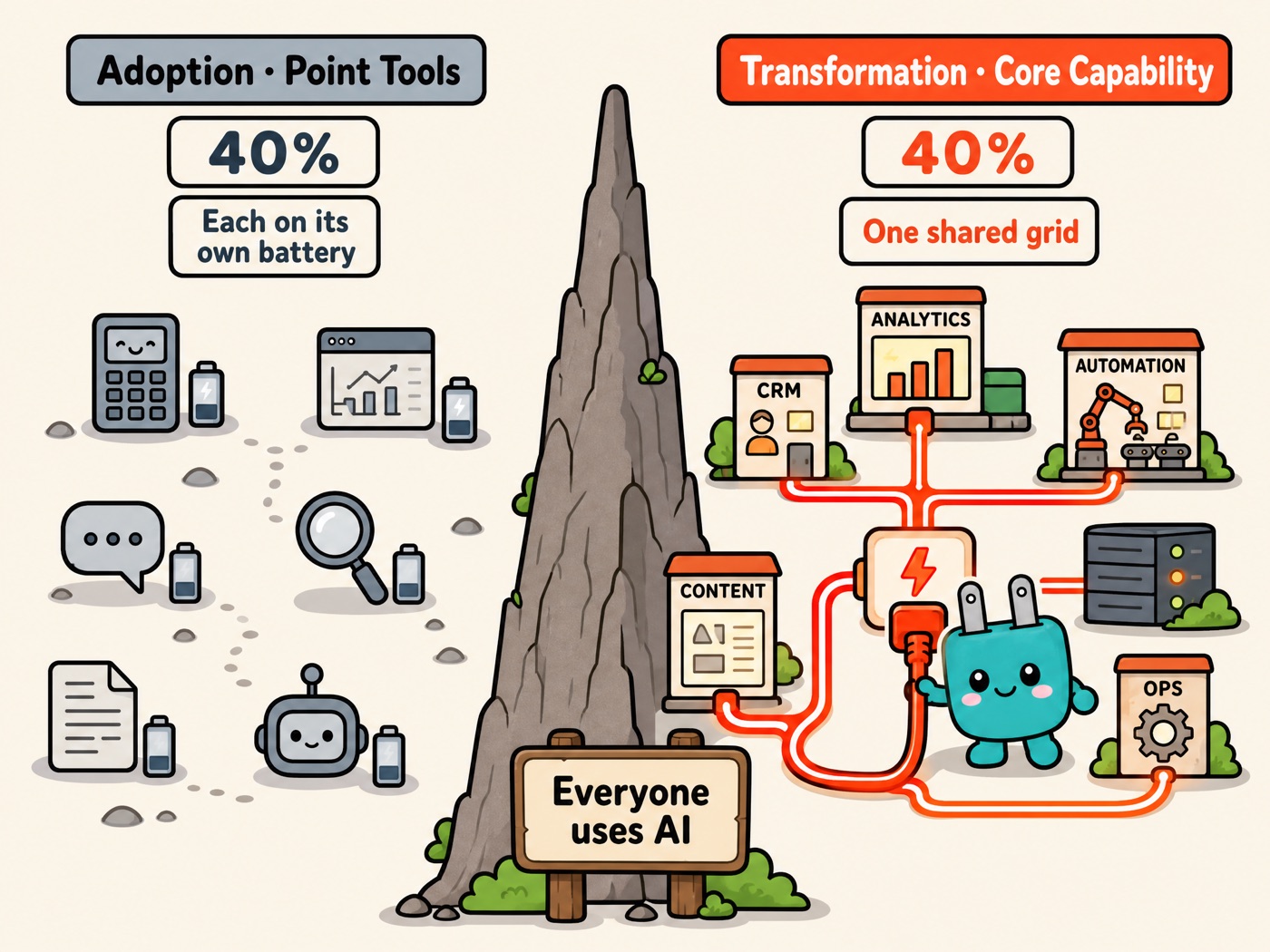
In short: point solutions only ever produce point results. Each one looks fine on its own — the demo can even be dazzling — but they share a common fate: stuck permanently at the pilot stage, changing nothing about how the company actually operates.
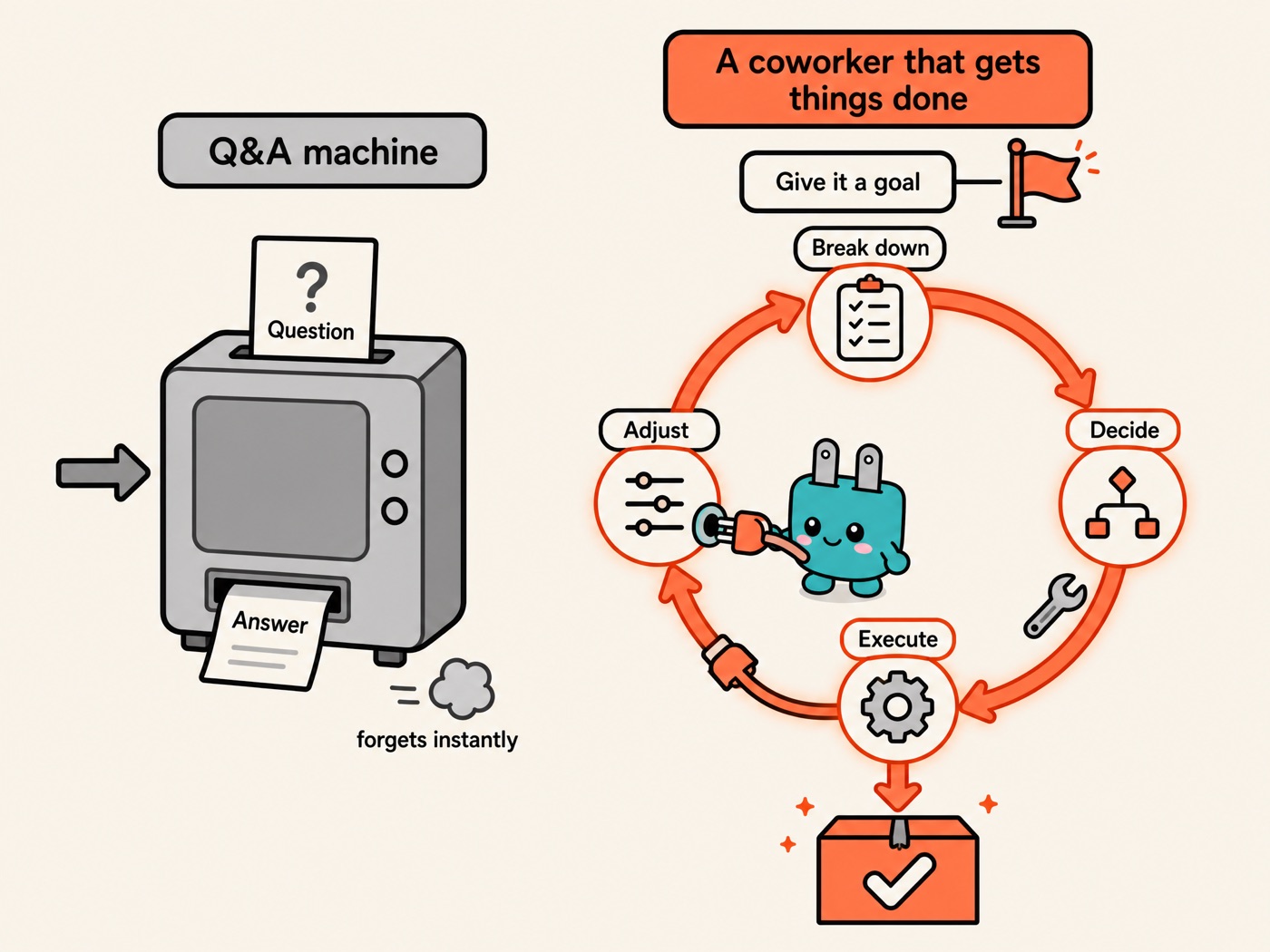
A chatbot is a Q&A machine; an agent is a coworker who actually gets things done. Ask a chatbot something, it answers, then forgets. Give an agent a goal, and it breaks the goal down, makes decisions, and executes step by step to completion — adjusting as it goes based on results. A lot of so-called "AI transformation" is really just a row of Q&A machines. You cannot build transformation out of chatbots — that's a first-principles limitation, not a matter of degree.
Why point solutions are inevitably mediocre
The claim up front: companies that treat AI as an isolated tool get mediocre results. This isn't an attitude problem — it's structural.
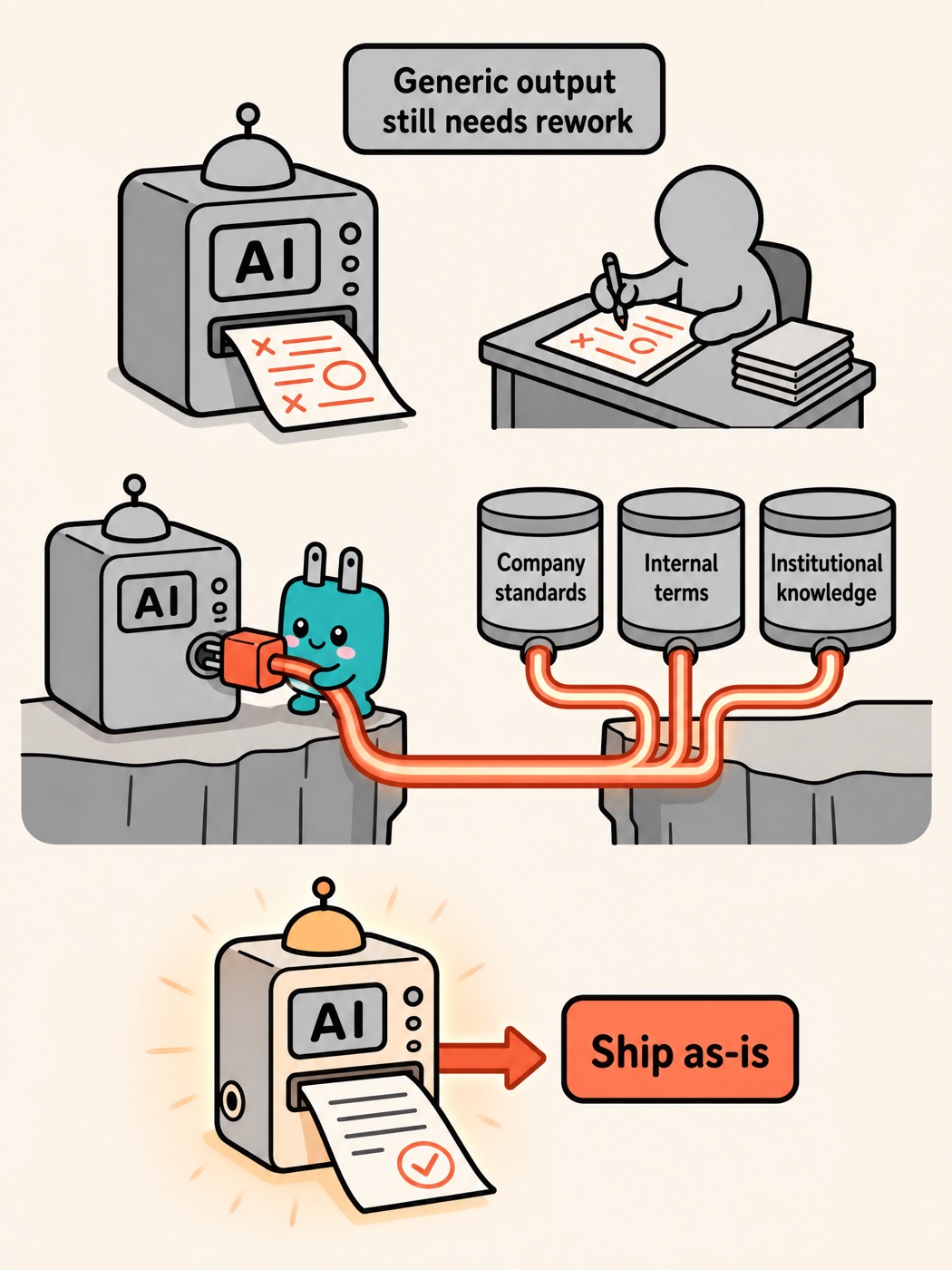
These tools run on "generic AI," and generic AI produces generic output: grammatically correct, structurally complete, but something everyone who reads it thinks, "this still needs work." That's exactly the problem. An employee gets an AI-drafted document and finds it doesn't know the company's standards, doesn't use the company's terminology, doesn't know the institutional knowledge that lives only in veteran employees' heads and was never written down anywhere. So the employee still has to do the heavy lifting themselves, refining it until it's usable.
This is the difference between "AI drafts a document" and "AI drafts a document your team can ship as-is." It sounds like a few words apart, but between them sits an entire company's worth of context. The former is a toy; the latter is productivity — and the gap between them isn't the model, it's how much context you feed it.
What's the evidence? A pattern shows up again and again in the book: two companies use the same model and get wildly different results — the difference is how much organizational context they fed in. That single sentence already kills the "model determinism" theory: if the same model can produce wildly different outcomes, the model clearly isn't the deciding variable. Scope is. Treat AI as a point tool and you get point results. Treat it as transformation and you're rebuilding three things at once: how employees work, how processes run, what products become possible.
Those three things are the book's core framework: the three pillars. Let's take them one at a time — each one backed by a real company.
L'Oréal: moving everyone's starting line forward
Back to the salesperson at the start. What made those few seconds possible wasn't a smarter model — it was the model being wired into that company's real data flows: the CRM, meeting recordings, prospect research. Swap in a different company, a different dataset, and the same model can't produce that briefing.
This isn't limited to salespeople. Finance connects to the data warehouse to produce reconciliation reports; legal reviews contracts against the company's own risk framework and flags deviating clauses; marketing drafts campaign proposals against brand guidelines. The pattern holds: the value scales with how much organizational knowledge gets encoded in.
L'Oréal put a number on this pattern. Picture its situation: products sold in more than 150 countries, data scattered across countless pipelines. An employee wanting to know how a particular product line was selling in a particular market had to file a request, wait for a data specialist to build a custom query, then hope the specialist understood what they were actually asking. The company's entire data capability was bottlenecked right there.
Its solution was an internal AI platform built on Claude: a multi-agent system that routes plain-language employee questions to the right data sources and more than 15 specialized agents, then synthesizes the answers with charts.
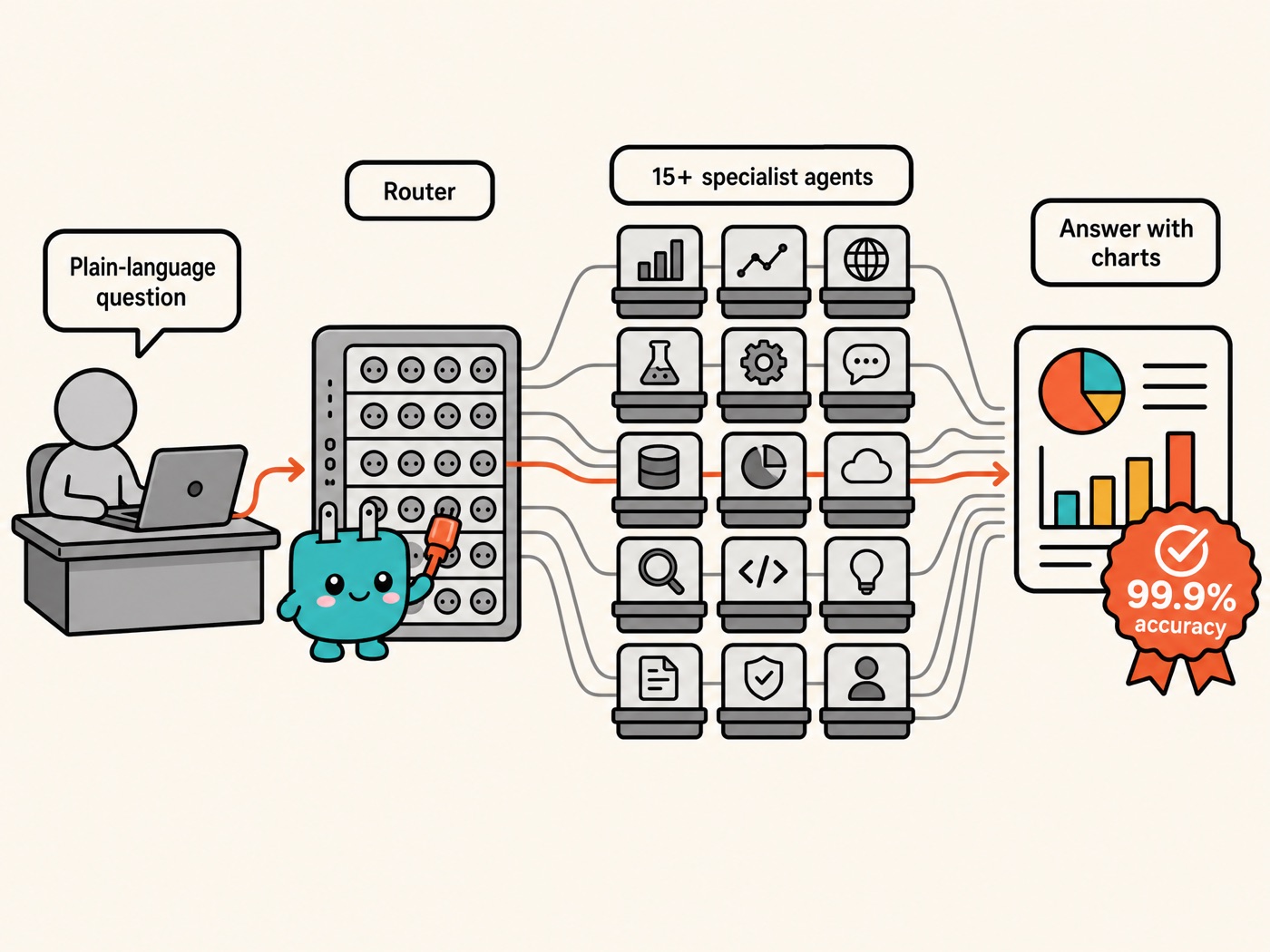
Note what matters here isn't "swapping in a more powerful model" — it's 90 approaches versus one at 99.9%. Plenty of approaches were tried and failed; the one that worked was the one that got the 15 specialized agents and the correct data sources properly orchestrated. Orchestration and context are what fills the gap between 90% and 99.9%. Thomas Menard, who leads L'Oréal's agentic platform and LAB, put it this way: "Our automated evaluation capabilities, like LLM-as-a-judge, have repeatedly demonstrated the superiority of Claude models."
Lyft: compressing "months" into "minutes"
This pillar is a different picture: it's not one person getting faster, it's the entire pipeline getting faster. And there's a counterintuitive rule here: the more complex and information-dense the process, the bigger the payoff.
The reason is the same one from before: the value of process automation depends entirely on the context behind it. Build standards, compliance requirements, and institutional knowledge into the system, and processing time can drop from months to minutes without quality slipping. What success looks like: a clinical writer goes from spending weeks assembling a report to spending most of their time reviewing and refining; a compliance officer goes from days producing a regulatory filing to minutes generating a first draft; a whole team goes from spending 80% of its time producing documents to spending 80% of its time making judgment calls.
Capacity shift: AI doesn't replace people — it moves them from "production" to "judgment." The machine takes over the manual labor; people get their hands free for the work only people can do.

Lyft is the hard evidence for this pillar. If you've ever run into trouble on a ride-hailing app late at night, you probably know the frustration: something goes wrong with your trip, you wait thirty or forty minutes for support to pick up, and the agent on the other end is juggling three or four people at once, replying with copy-pasted templates. That was Lyft's situation: spanning six continents and thousands of cities, its support system pushed to a breaking point, agent burnout climbing right along with it.
Lyft's choice of Claude was deliberate: tested on raw performance, and tested on whether it matched the brand's voice. It started with driver support, then expanded to rider support and billing disputes. Today's setup: Claude greets the customer by name, investigates the specific situation, resolves it in seconds — and only routes to a human agent, along with a self-generated conversation summary, when the case genuinely needs human judgment.
Notice the causal chain: resolution time didn't drop 87% because Claude types faster than a human agent — it dropped because Claude was embedded into Lyft's complete ticketing workflow, able to investigate, judge, and hand off to a human with a summary attached exactly when needed. That's a return on depth of integration, not a return on model speed.
The savings run into the millions of dollars, and Lyft didn't pocket them — it reinvested them back into the support team and new initiatives, including one called Lyft Silver, dedicated one-on-one support built specifically for older riders. AI freed people from mechanical labor, and the savings turned into a warmer new service that simply didn't exist before.
Rakuten: letting customers do what they couldn't do before
The first two pillars looked inward. This one looks outward: AI doesn't just save you money — it lets you build products that couldn't have existed before.
The book points to a shared pattern: frontier AI model + proprietary data + existing trust relationships + deep domain expertise. AI is just the enabler; the real moat comes from everything around it. So the opportunity at the product layer is never just "cut costs" — it's using new product capabilities to create net-new revenue and a compounding competitive edge: whoever moves first builds the integrations, the data flywheel, and the customer habits that make it hard for latecomers to catch up.
Trust boundary: the scope of data a customer is willing to hand you for processing. In regulated industries like finance and healthcare, data security and compliance aren't a nice-to-have — they're the price of entry. Any AI product that runs outside the trust boundary is, functionally, a product that never ships.
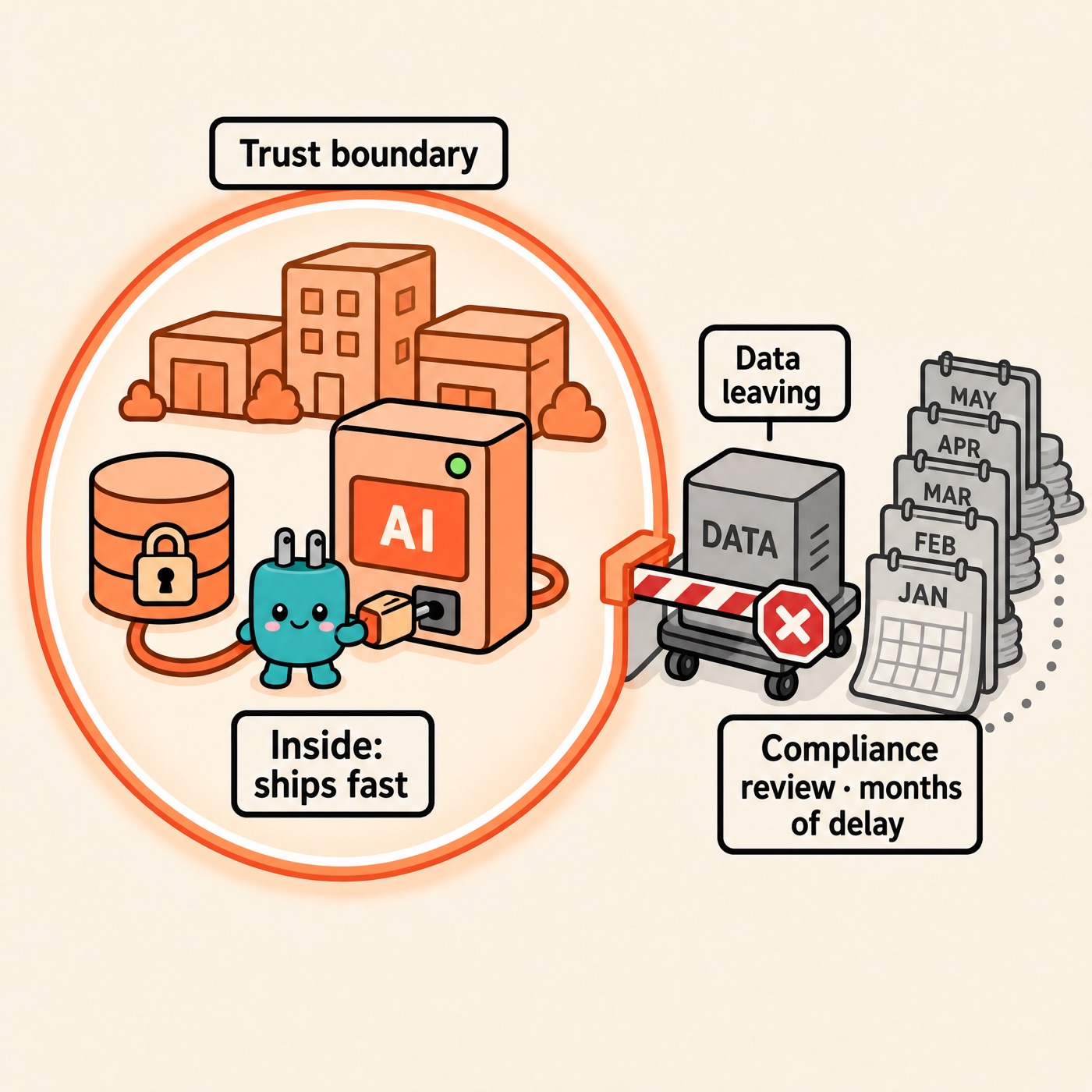
The company that builds this pillar out most fully is Rakuten. It runs more than seventy businesses under a company-wide "AI-nization" strategy. It saw early on that agents doing real work need persistent compute, memory, and storage — so its engineers started by building the infrastructure from scratch. That call was right at the time, but it came at a cost: top talent that could have gone toward differentiated innovation was instead spent laying groundwork.
The turning point was adopting Claude Managed Agents (a pre-built, configurable agent runtime framework on the Claude platform), outsourcing the entire "execution layer" grunt work so its own engineers could go back to focusing on the agentic experience itself. The effect was like flipping a switch: within a week, specialized agents covering engineering, product, sales, marketing, and finance were deployed, wired directly into Slack, Microsoft Teams, and Rakuten's own kanban system, running long tasks for hours at a stretch. And an agent's memory compounds — it remembers mistakes made in the past, so it doesn't repeat them.
But what really sticks with people about Rakuten isn't the numbers — it's one image. Internally, they call cross-domain superusers "Galileo." One of them is a product manager, not an engineer. Working alone, he built a FinOps (financial operations) pipeline spanning several public clouds, and set up his own monitoring agent that runs silently in the background. This is something a product manager, in the past, wouldn't have dared to attempt — he would have had to get in line and ask the engineering team. That's the structural point Rakuten delivers: an agent isn't your future coworker, and it isn't a competitor coming for your job — it's infrastructure the company uses to accelerate building everything.
This advantage compounds — it doesn't just add up
By this point the first two claims already hold: point solutions are mediocre, transformation runs on organizational context. But that's not enough on its own. If the advantage were only a one-time "I'm a bit better than you," it would eventually get matched. The book's sharpest claim sits at this third layer: this advantage snowballs — the gap between whoever moves first and whoever comes later keeps growing.
Where does the compounding come from? The book offers a very specific mechanism it calls "how accuracy compounds." The common approach: have an expert review AI output against the same baseline every single time — the expert burns out, and the AI never improves. The right approach: build a system that feeds human expert feedback back into the AI's knowledge base, so every expert review makes every future process a little better. That means the AI's capability curve climbs upward — it doesn't stay flat.
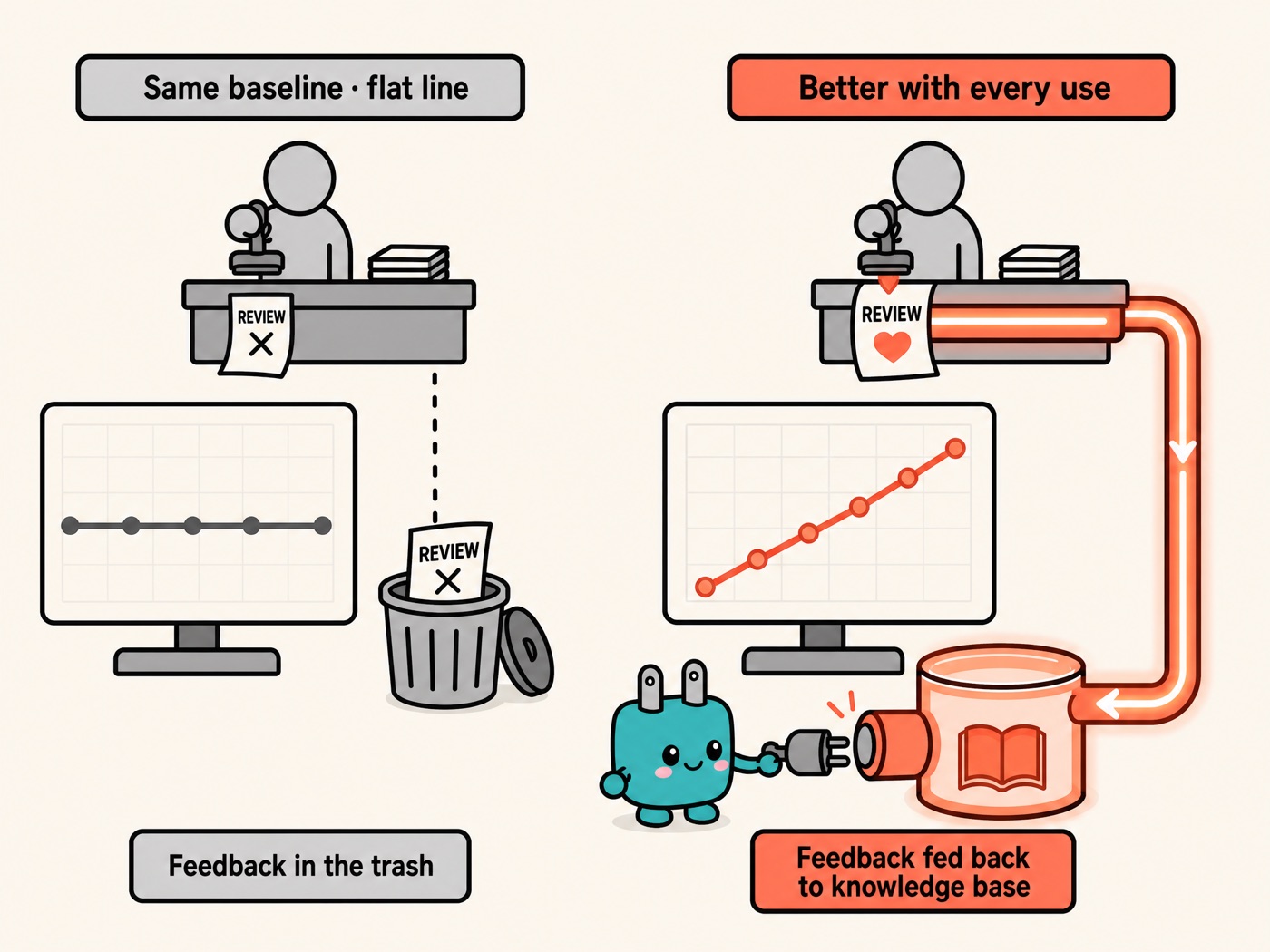
Think of a veteran employee mentoring a new hire. Experience from mentoring one person once settles into a process handbook, so the second new hire doesn't need to be taught from scratch — individual learning instantly becomes organizational learning. Rakuten's line earlier — "an agent's memory compounds" — is the literal implementation of this same mechanism: a mistake one agent makes is a mistake no agent makes again.
Separating "tool" from "infrastructure" is the key to understanding compounding: a tool is something you use and put back, its value fixed; infrastructure is something you keep building on top of, its value rising the more you build. A point solution is a tool; transformation is laying infrastructure. That's why one is linear and the other compounds.
Follow that mechanism through and the conclusion is direct: the organization that starts earliest accumulates the biggest advantage. Because every month of accumulated approval records, expert feedback, and correction cases makes next month's output faster and more accurate. Starting a year late isn't a one-year gap — it's a gap of "a year's worth of compounding": your competitor got stronger every single month of that year, while you're starting from zero.
Plugins turn institutional knowledge into organizational infrastructure
The logical chain closes here: point solutions are mediocre → transformation runs on context → context compounds → so whoever moves first wins. But that chain has an implicit precondition. Look back at every case above: L'Oréal's 15-agent orchestration layer, Lyft's support system, Rakuten's Managed Agents, plus Novo Nordisk (NovoScribe compressed a clinical study document from 10-plus weeks to 10 minutes) and RBC (an agentic solution serving 2,200 advisors managing $689 billion in assets) mentioned in the book — every one of them built its own custom platform specifically to feed context to Claude.
The return is substantial, but so is the barrier: all of it requires engineering resources, time, technical expertise. The starting line for this game got set at "you need an engineering team that can build its own platform." Most knowledge workers are locked out.
Claude Cowork changes that equation. It gives non-technical people the same agentic capability enterprises build for themselves on the API, without any custom development. You hand it a task, and what comes back isn't a suggestion or an outline — it's the actual finished thing: a Word document, an Excel model, a slide deck, an analysis report.
The mechanism behind it is plugins: packaging skills, context, and connectors into a single plugin that gives Claude a role-specific expertise. Institutional knowledge that used to be locked in a veteran employee's head — gone when they left — now gets packaged into a plugin: reusable, shareable, cumulative. It's essentially engineering the process of turning individual learning into organizational learning. Anthropic has already open-sourced 11 plugins, covering productivity, sales, finance, data, legal, marketing, customer support, product management, enterprise search, biology research, and plugin management itself.
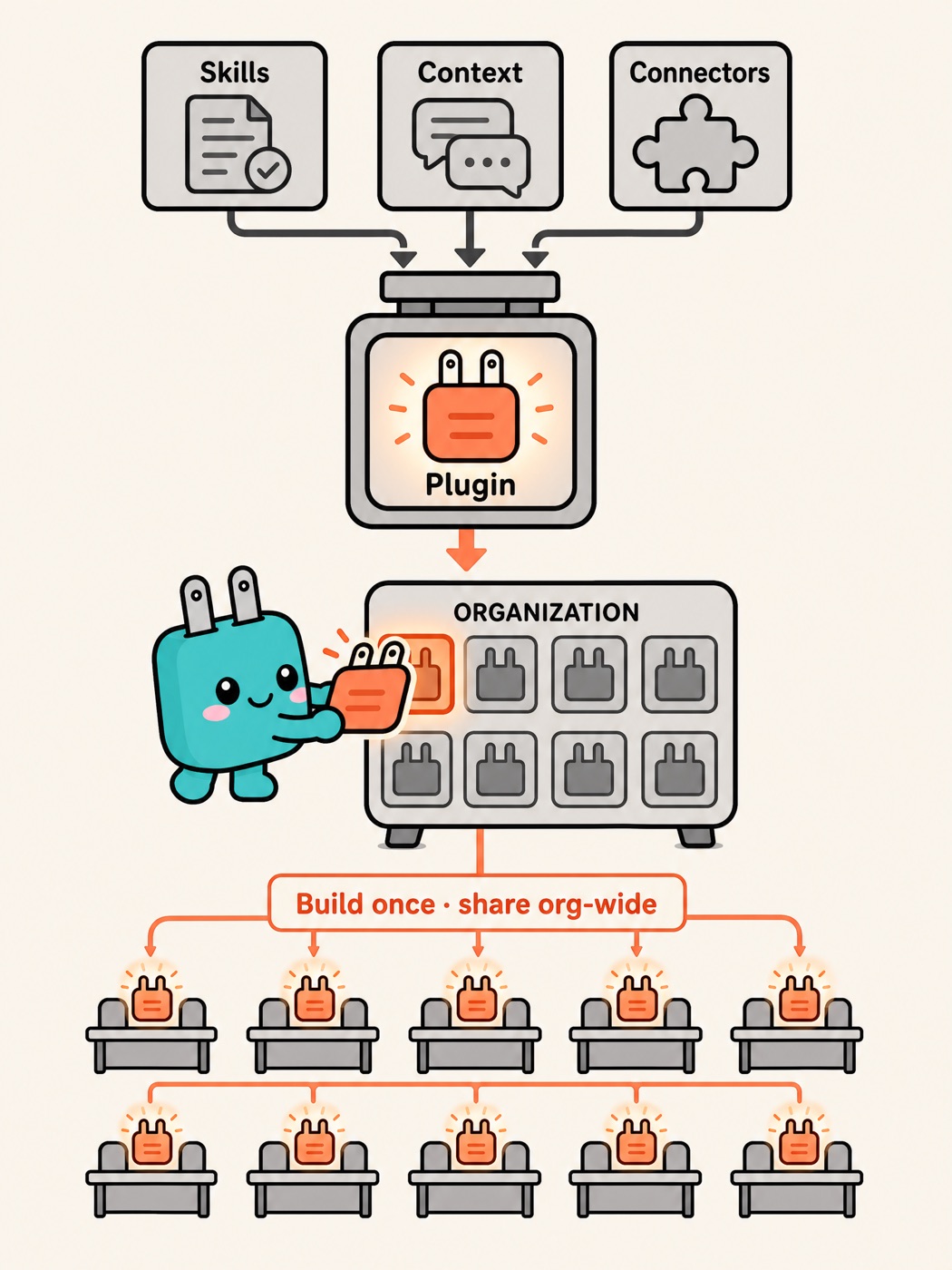
To make this actually hold up in an enterprise, the book lists four enterprise-grade requirements: governance controls (an organization-specific plugin marketplace that turns governance from reactive shutdowns into proactive curation and distribution, stopping shadow AI from spreading unchecked); security by design (tasks run locally, nothing gets processed in the cloud — solving "the most common objection to enterprise AI" before it's even raised); auditability (compatible with OpenTelemetry, so you can see exactly when AI acted, on whose behalf, and what it did); and integration and continuity (works inside existing CRM and document systems, no context lost switching between Cowork and Excel or PowerPoint).
Four principles + a three-phase timeline, reproduced in full
After all these other companies' stories, it comes down to you. The book's actual playbook is just two pieces: four principles, each one pushing back against a common impulse; and a six-month timeline that puts the principles on a calendar. These two pieces are the most actionable part of the whole book — reproduced in full translation below, ready to copy.
① Start with specificity, not scale
Give Claude your standards, your tools, your institutional context from the very beginning. An employee who gets generic output on the first interaction rarely gives the tool a second chance. The organizations in this guide succeeded because they gave Claude enough context that the output read like it came from someone who genuinely understood the business.
② Choose pilots with a measurable finish line
Each of the three pillars has its own success metrics: for smarter employees, look at adoption rate and time saved; for faster processes, look at cycle-time compression and quality scores; for transformative products, look at revenue impact and speed to market. Define your success criteria before the pilot starts, so the results aren't ambiguous.
③ Build plugins for reuse from day one
The temptation is always to build a quick fix for one team and worry about reuse later. Resist it: a plugin built for one team should benefit the whole organization. Encode tribal knowledge once, and every team that installs that plugin gets the benefit immediately. The marginal cost of sharing a plugin is zero; the marginal value is enormous.
④ Never underestimate the governance layer
Admin controls, auditability, and an organization-specific marketplace are prerequisites for broad rollout — not features you bolt on after adoption takes off. Organizations that skip governance early end up spending more time cleaning up unsanctioned usage than they saved by moving fast.
English original
• Start with specificity, not scale. Give Claude your standards, your tools, your institutional context from the beginning. Employees who receive generic output from a first interaction rarely give the tool a second chance. The organizations in this guide succeeded because they gave Claude enough context to produce output that felt like it came from someone who understood the business. • Choose pilots with a measurable finish line. Each of the three pillars has different success metrics. Smarter employees might be measured by adoption rates and time savings. Faster processes might be measured by cycle time compression and quality scores. Transformative products might be measured by revenue impact and speed to market. Define your success criteria upfront, before the pilot starts, so the results are unambiguous. • Build plugins for reuse from the beginning. The temptation is to build a quick solution for one team and worry about reuse later. Resist that temptation. Plugins built for one team should benefit the entire organization. When you encode tribal knowledge once, every team that installs the plugin gets the benefit immediately. The marginal cost of sharing a plugin is zero, while the marginal value is enormous. • Never underestimate the governance layer. Admin controls, auditability, and organization-specific marketplaces are prerequisites for broad rollout, not features you add after adoption takes off. The organizations that skip governance early spend more time cleaning up unsanctioned usage than they saved by moving fast.
Set evaluation and success criteria
Focus on exactly one thing for the first several weeks: evaluation and success criteria. Identify 2 to 3 teams with clear pain points and measurable workflows; install relevant plugins from the open-source repository, or build custom plugins that encode your teams' standards and processes; define what success looks like before anyone starts using the tool.
For example: for a sales team, that might be "cut call-prep time by 50%"; for a legal team, "contract review turnaround from 5 days to 1 day"; for a documentation team, "first-draft quality reaching 80% of the final approved version." How specific the success criteria are matters a lot — a vague goal like "improve productivity" only produces vague results that are easy to dismiss.
Launch a champion pilot
Months two and three are the champion pilot: 2 to 3 teams use Claude Cowork with configured plugins in real production workflows, not sandbox experiments. Measure adoption weekly; alongside the quantitative metrics, collect qualitative feedback too, since the moments employees discover unexpected value are often more informative than a time-saved calculation.
The goal at this stage isn't perfection — it's proof of value, and clarity on what still needs to change before a broader rollout.
Scale the impact
With a proven concept in hand, months four through six shift to scaling and governance: deploy admin marketplace controls, establish a plugin review and approval process, and roll out to more teams using the plugins and configurations refined during the pilot.
Every newly onboarded team benefits from institutional knowledge that's already been encoded, so the second wave of rollout moves faster than the first, and the third wave faster still. That's the compounding dynamic actually running: every investment in context, configuration, and governance makes the next deployment cheaper and more effective.
English original
Phase 1: Setting evaluation and success criteria For the first several weeks, focus exclusively on your evaluation and success criteria. Identify two to three teams with clear pain points and measurable workflows. Install the relevant plugins from the open-source repository or build custom plugins that encode your team's specific standards and processes. Define what success looks like before anyone starts using the tool. For a sales team, for example, that might be call prep time reduced by 50 percent. For a legal team, it might be a contract review turnaround cut from five days to one. For a documentation team, it might be first-draft quality reaching 80 percent of the final approved version. The specificity of the success criteria matters: vague goals like "improve productivity" produce vague results that are easy to dismiss. Phase 2: Launching a champion pilot The second and third months of the initiative are the champion pilot. Two to three teams use Claude Cowork with their configured plugins in production workflows, not sandboxed experiments. Measure adoption weekly. Collect qualitative feedback alongside quantitative metrics, because the moments when employees discover unexpected value are often more informative than time-saved calculations. The goal of this pilot phase is not perfection but proof of value and a clear understanding of what needs to change before broader rollout. Getting started with Claude Cowork in the help center provides practical guidance for configuring access and managing this initial deployment. Phase 3: Scaling impact Successful proof of concept in hand, months four through six shift to scaling and governance. It's time to deploy the admin marketplace controls, establish plugin review and approval workflows, and begin the rollout to additional teams using the plugins and configurations refined during the pilot. Each team that comes online benefits from the institutional knowledge already encoded, which means the second wave of adoption moves faster than the first. The third wave moves faster still. This is the compounding dynamic in action: every investment in context, configuration, and governance makes the next deployment cheaper and more effective.
The line "the second wave moves faster than the first, and the third wave faster still" is exactly the compounding mechanism from earlier, mapped onto a calendar: not because the model got better, but because the context, configuration, and expert feedback accumulated so far are all accelerating things on your behalf.
You don't need a perfect plan — you need a specific starting point
We started with a salesperson's few seconds before the phone rang. By now you can probably see that what's packed into those seconds isn't just a few hours saved.
Pulling the whole chain together: the model isn't the deciding variable — the evidence is that the same model produces wildly different results at different companies. The deciding variable is scope: whether you treat AI as a point tool or as the foundation for transformation. Point solutions are inevitably mediocre, because they run on generic output, and generic output always "still needs work." Transformation runs on encoding organizational context into the system, and the numbers behind the three pillars (L'Oréal's 99.9%, Lyft's 87% drop in resolution time, Rakuten's 97% drop in critical errors) prove it again and again: what widens the gap is depth of integration and thickness of context, not the model itself. And this advantage compounds — expert feedback flows back into the knowledge base, agent memory accumulates, plugins turn institutional knowledge into shareable infrastructure — so the gap between whoever moves first and whoever comes later just keeps growing.
The book calls out the most common, and most fatal, mistake: waiting until the strategy is fully formed before taking the first step. Successful organizations do the opposite — they cut in through a narrow opening, learn fast, then expand with conviction. You don't need a perfect plan. You need exactly three things: a specific starting point, a set of quantifiable success criteria, and the willingness to keep learning from whatever actually happens next.