Anthropic Ships Claude Sonnet 5: 40% Cheaper, Matching Opus 4.8 on Some Tasks
- Anthropic has released Claude Sonnet 5, calling it the most capable Sonnet model yet at running tasks autonomously (agentic).
- Promo pricing is $2 input / $10 output per million tokens (through August 31, 2026), then rising to $3 / $15; for comparison, the flagship Opus 4.8 is priced at $5 / $25.
- Live today across the Free, Pro, Max, Team, and Enterprise plans, plus Claude Code and the Claude Developer Platform — and it's the default model on the Free and Pro plans.
- Safety testing shows a lower overall misbehavior rate than the previous Sonnet 4.6, but its cyberattack ability (e.g. developing software exploits) is markedly weaker than Opus 4.8, and Anthropic turned on real-time cybersecurity protections by default.
- It uses a new tokenizer, so the same text may be cut into more tokens (about 1.0 to 1.35×); the promo pricing already factors this in, making the upgrade roughly cost-neutral once you do the math.
With this launch, the cheap one catches up to the expensive one
Anthropic has released Claude Sonnet 5, calling it the most capable Sonnet model to date and the best at running tasks autonomously (agentic — meaning the model can break a task down on its own, call tools like a browser and a terminal, run through several steps in a row, and proactively check its own work along the way).
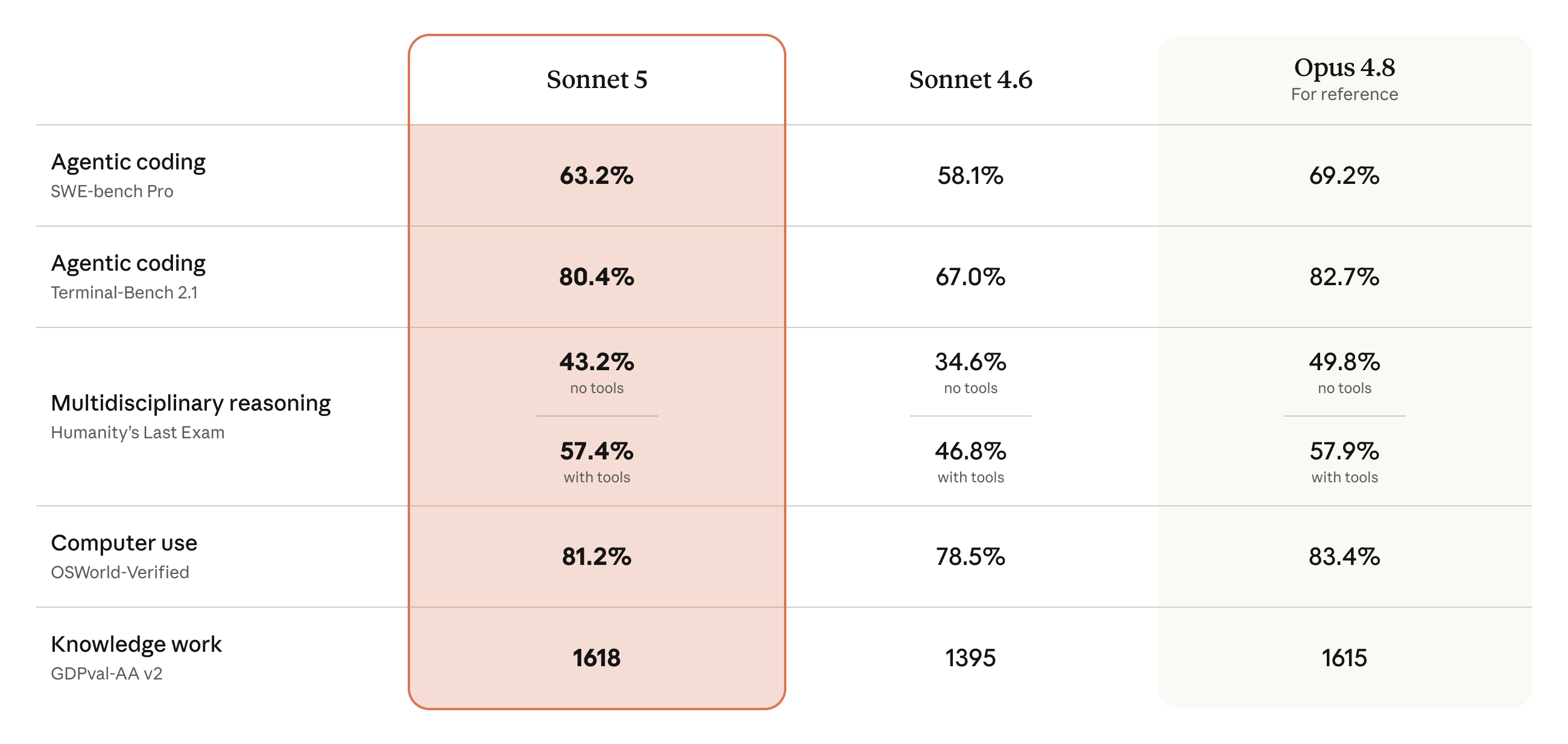
Why it matters: per million output tokens, Sonnet 5's standard price is $15 and Opus 4.8 is $25 — exactly 60%; the promo price drops even lower, to $2/$10 input/output. And on BrowseComp (agentic search) and OSWorld-Verified (computer use), turning the effort up lets Sonnet 5 tie with Opus 4.8. 'Cheaper' and 'reaches the flagship' land on the same Sonnet for the first time.
The models that get work done have always come from the Sonnet line first
For many developers, the whole 'AI that gets work done on its own' trend started with Sonnet: Claude Sonnet 3.5, 3.6, and 3.7 were among the first models to turn heads at writing code and calling tools. But lately the sharpest gains have come from the pricier Opus line, and the Sonnet track fell behind. What Sonnet 5 sets out to do is close that gap.
agentic ability
ahead
the gap
Compared with the previous Sonnet 4.6, Anthropic says Sonnet 5 shows clear gains across the key areas tied to agentic performance: reasoning, tool calling, coding, and knowledge work.
How much intelligence a dollar buys now
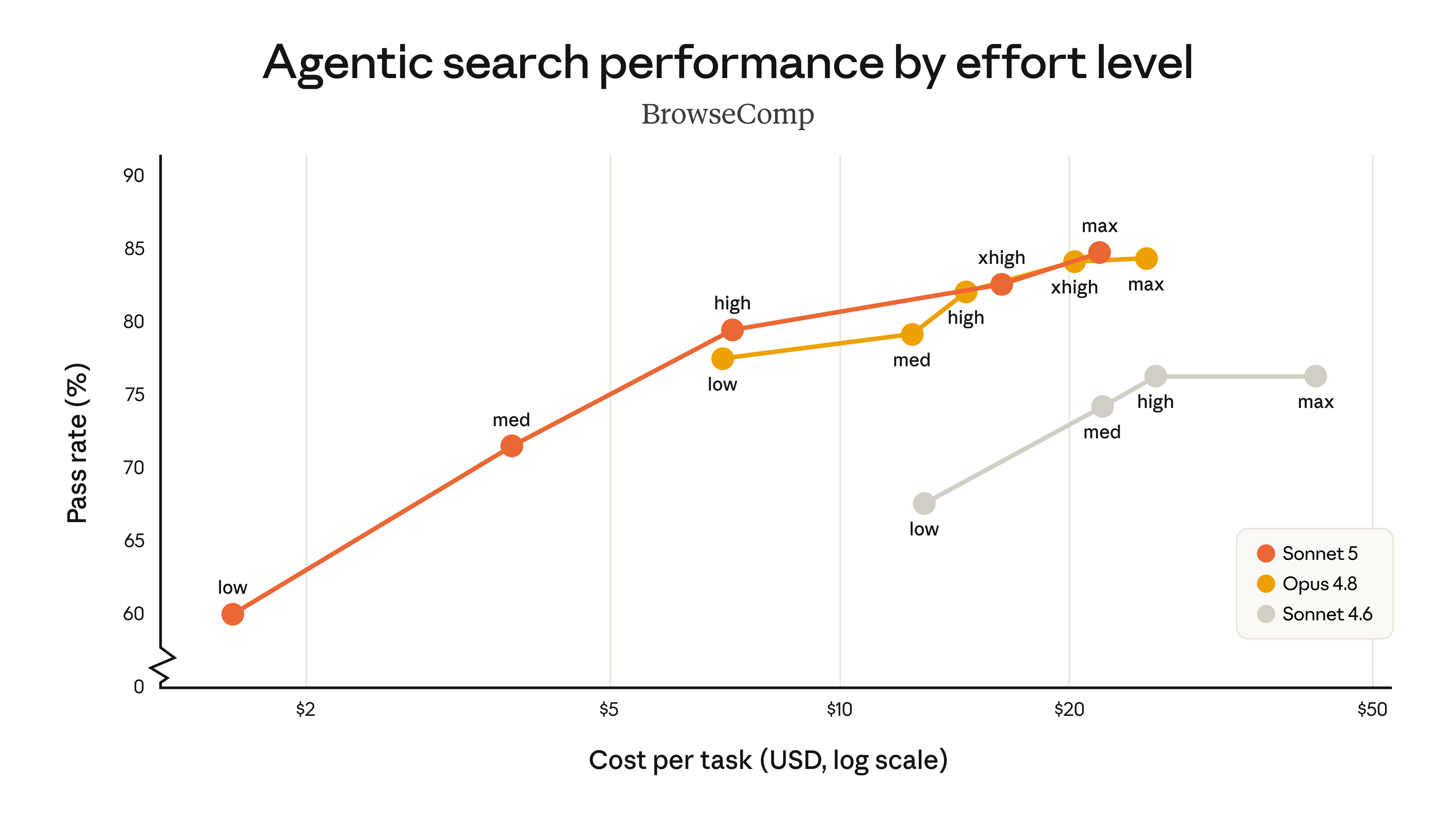
Anthropic released two cost-performance curves comparing Sonnet 5, Sonnet 4.6, and Opus 4.8 across effort levels — the x-axis is cost per task, the y-axis is benchmark score. The takeaway: Sonnet 5 (orange line) beats Sonnet 4.6 (gray line) across the board, covers a far wider cost range than Opus 4.8 (yellow line), delivers a clear value jump at mid effort, and matches Opus 4.8 on some tasks at the top level.
Two benchmark-methodology updates (June 30 correction)
Anthropic revised this launch post on June 30: the original BrowseComp chart used a simpler method that underestimated Sonnet 5, and it has now been redrawn with the standard method from the system card (10M token budget + compaction + programmatic tool calls). Two older scores were also corrected because the scoring method changed: Sonnet 4.6's Humanity's Last Exam score is updated to 34.6% (no tools) / 46.8% (with tools); Sonnet 4.6's OSWorld-Verified score is updated to 78.5%. These differ from the numbers in the Sonnet 4.6 launch blog precisely because the benchmarking method changed.
Spend more compute, think one step further: how one model is both cheap and top-tier
Sonnet 5 can span such a wide price range thanks to a mechanism called effort (a compute/reasoning-intensity level): with the same model, you choose 'how hard it thinks.' Lower levels are cheaper and faster but may be less careful; higher levels spend more compute reasoning over and over and double-checking itself, giving more accurate answers but at greater cost and slower speed.
It's like ordering the same dish at the same restaurant: you can have the chef cook it as usual, or pay extra to have him take more care and taste it himself before serving to make sure it's right. It's the same dish; what changes is how much care he puts in and how many times he checks. The effort level dials exactly that 'level of care.'
may miss details
strong cost efficiency
more accurate, steadier
matches Opus 4.8 on some tasks
In the past, more capability meant switching to a bigger, pricier model. Now you don't switch models — you just turn a knob: low levels are the cheap, fast entry tier; the high level (xhigh) spends more compute reasoning and self-checking, matching the flagship Opus 4.8 on some tasks. A single Sonnet 5 fills the entire price band from entry-level to near-flagship in one go, instead of topping out early like Sonnet 4.6. Where to strike the balance between cost and performance is left for you to decide per project.
Early users say: no nudging needed — it checks its own homework
Anthropic says feedback from early-access partners was fairly consistent: Sonnet 5 is noticeably better at 'getting work done on its own' than earlier generations. Here are a few of the testers' observations, plainly stated.
- On complex tasks, it keeps going until they're done, whereas earlier Sonnets often stopped halfway.
- Even when no one explicitly asks, it proactively checks whether its own output is correct.
- And the price for doing this kind of autonomous work is quite attractive.
Safer overall — but its cyberattack ability was deliberately held down
Pre-deployment safety testing shows Sonnet 5 is safer overall than Sonnet 4.6: better at refusing malicious requests, more resistant to prompt injection (where an attacker secretly plants malicious instructions into the web pages or emails the model processes, trying to hijack it into serving the attacker rather than the user), and less prone to hallucination and sycophancy. In an automated behavioral audit spanning many types of misbehavior, it scores lower overall (i.e., safer) — but still higher than the stronger Opus 4.8 and Claude Mythos Preview.
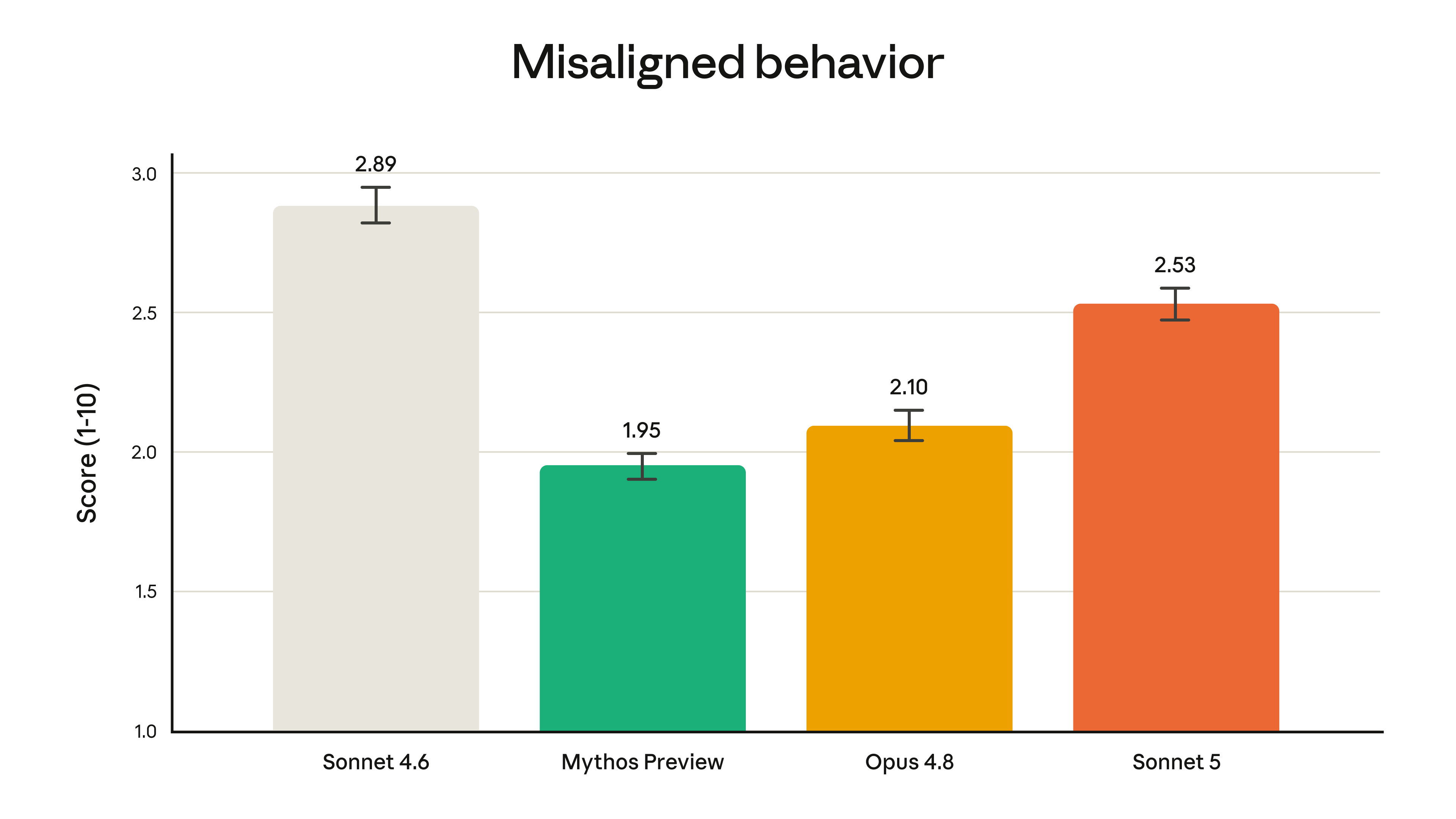
Cybersecurity is the one area held down on its own. Anthropic says it did not specifically train Sonnet 5 on cybersecurity tasks: it can handle routine, harmless network tasks, but on potentially harmful benchmarks like developing software exploits, it performs markedly worse than Opus 4.8 and Mythos 5.
A concrete test: can it break into Firefox
'Weak cyberattack ability' sounds abstract, so Anthropic gave concrete numbers: have each model develop an exploit for vulnerabilities in the Firefox browser. This benchmark was built jointly by Anthropic and Mozilla, and all the vulnerabilities involved have already been fixed in Firefox 148.
Neither Sonnet can build a single complete, working exploit (both at 0.0%). Sonnet 5 is only slightly higher than Sonnet 4.6 on partial success rate, which Anthropic reckons mostly spills over from stronger general intelligence rather than dedicated training. For comparison, both Opus 4.8 and Mythos 5 have far stronger cyberattack ability than either Sonnet.
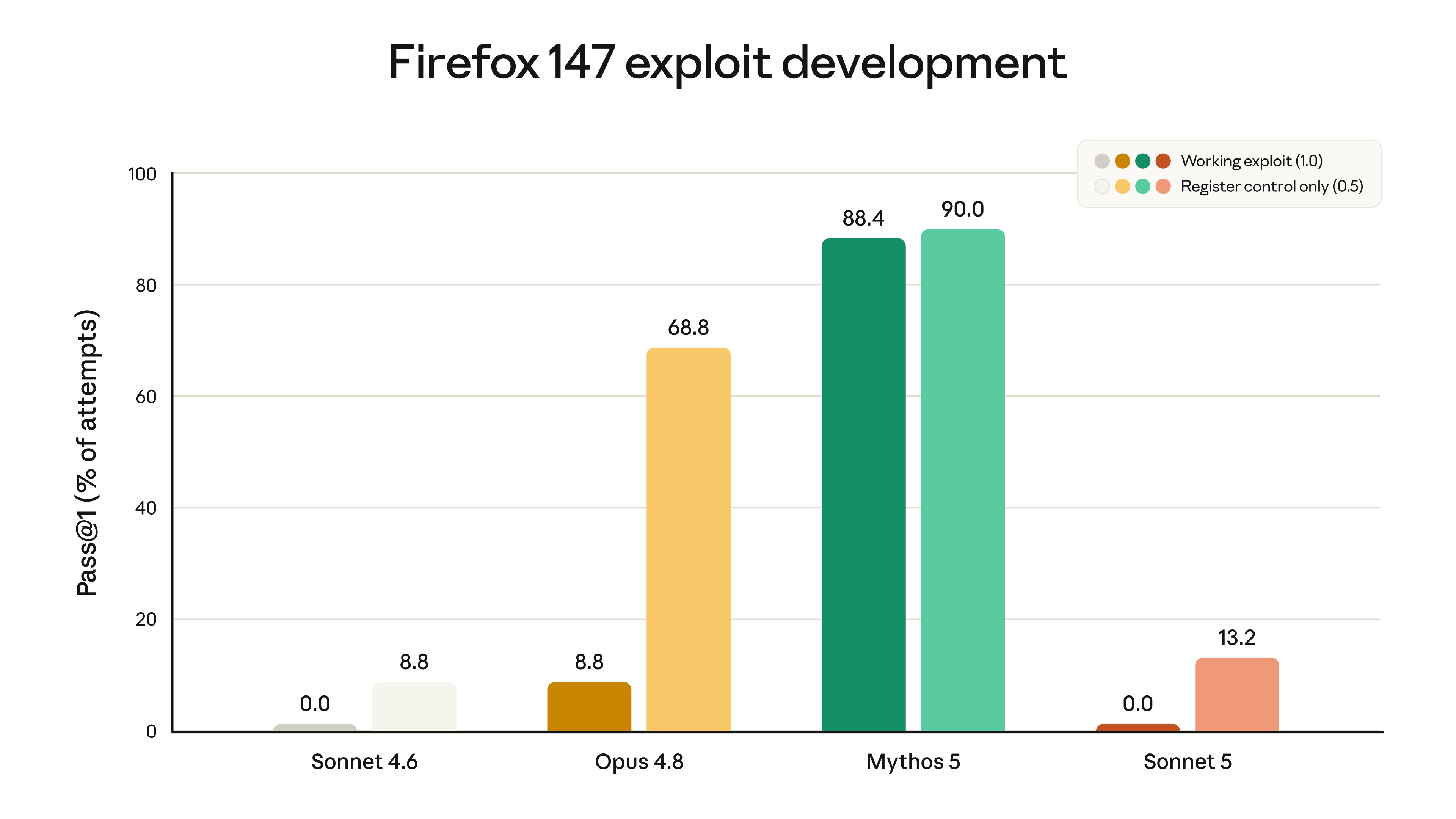
Because Sonnet 5 is slightly stronger than its predecessor on these tasks, Anthropic turned on real-time cybersecurity protections by default — detecting and blocking dangerous network uses in real time, at the same tier as Claude Opus 4.7 and 4.8. Anthropic judges Sonnet 5's overall cybersecurity risk to be low, so these protections are more lenient than Fable 5's (which block a far wider range of cybersecurity tasks).
Looks like a price cut — really it's a new measuring stick
Sonnet 5 switched to a new tokenizer. Before processing text, the model first cuts it into tokens for billing and computation. With the new tokenizer, the same text may be cut into more tokens — about 1.0 to 1.35× (depending on content type). In other words, the per-token price dropped, but the same passage now burns more tokens, so the real unit cost didn't fall as much as it looks.
Per million tokens, it drops from Sonnet 4.6's price to the promo $2/$10.
The promo pricing was set precisely to offset the tokenizer change, making the move from Sonnet 4.6 to Sonnet 5 roughly cost-neutral.
Anthropic says outright: the promo pricing is set so that this upgrade works out to be roughly cost-neutral. That's why 'price cut' belongs in quotes — you have to do the math with the token count included. This tokenizer change is the same kind of move as the one with Claude Opus 4.7.
Available now: where it's live, the price table, and how to choose
Sonnet 5 goes live across all plans today: it's the default model on the Free and Pro plans, and available to Max, Team, and Enterprise users too; it also launches on Claude Code and the Claude Developer Platform, and developers can call claude-sonnet-5 via the Claude API.
| Model | Input / Output (per million tokens) |
|---|---|
| Sonnet 5 (promo, through 2026-08-31) | $2 / $10 |
| Sonnet 5 (standard price after) | $3 / $15 |
| Opus 4.8 (for comparison) | $5 / $25 |
$2 / $10
promo
$3 / $15
standard
To accommodate the higher token consumption that comes with higher effort levels, Anthropic has raised the rate limits across Chat, Cowork, Claude Code, and the Claude Developer Platform, so you can pick the right level per project.
How to choose
| Who you are | Recommendation |
|---|---|
| Developers | Want stronger agentic coding and tool calling on the same budget: use a high level. Want to save money: dial effort down to get near-flagship results at lower cost, and find your own balance between cost and performance. |
| Enterprise / Teams | Rate limits on Chat, Cowork, Claude Code, and the Developer Platform have been raised to match the higher token consumption at high levels. |
| Security work | Default cybersecurity protections match Opus 4.7/4.8; if you need less-restricted cybersecurity research or offense/defense work, Anthropic recommends using Opus 4.8 rather than Sonnet 5. |
Sonnet 5 narrows the gap: its performance is close to Opus 4.8, but at a lower price. Anthropic, "Introducing Claude Sonnet 5"