同样一个 AI 模型,为什么有的公司用出复利,有的公司用了个寂寞
- 一个销售在电话响前几秒拿到完整客户简报,背后是 AI 被接进了公司的真实数据流。这几秒钟,是整本书想讲的事的缩影
- Anthropic 电子书给「用 AI」和「用出复利」之间的差距起了名字:智能体思考的分水岭(agentic thinking divide)。渗透率两年翻倍后,谁在用已不构成区分度
- 点状方案必然平庸:通用 AI 给通用产出,员工拿到手「还得改」,差距不在模型,在喂进去多少组织上下文
- 三根支柱各有实证:L'Oréal 对话式分析准确率 99.9%、Lyft 客服解决时间降 87%、Rakuten 重大发布从每季度一次变每两周一次
- 这种优势会复利:专家反馈喂回知识库,能力曲线向上爬;晚开始一年,差的不是一年,是一年的复利
- 文末把四条落地原则和六个月三阶段时间表全文照录,可以直接抄走照做
电话响起前的那几秒,发生了什么
一个销售坐在工位上,电话还有几秒就要响。屏幕另一头是他追了半年的客户。
换作三个月前,他此刻应该是焦头烂额的:开着五六个标签页,CRM 里翻这家公司过去的往来记录,会议录音里找上次谁说了什么,再切到调研工具看对方最近有没有融资、竞品在不在他们的供应商名单里。这一套手工活做完常常要好几个小时,而他往往只来得及扫一眼,电话就响了。
这一次,他在通话前敲了一条命令。几秒钟,一份简报推到眼前:这家公司的最新数据、他和对方所有的互动历史、那笔还没结的交易卡在哪一步、竞品最近在向他们推什么。他端起水杯,从容地接起了电话。
企业早就过了「要不要用 AI」这一关
Anthropic 出了一本面向企业的电子书《Building AI agents for the enterprise》(企业级 AI Agent 实战),副标题是「来自行业领先者的最佳实践」。它把一件正在悄悄发生、却很少有人说清的事摆上了台面。
当一项技术的渗透率两年翻倍、还在加速,谁在用、用了多少,已经不构成区分度了。真正把公司和公司拉开档次的,是另一个问题:你是把 AI 当成一个摆在桌上的工具,还是当成重新组织你整个公司的底层能力。
这本书把那个变量拎了出来,给它起了个名字:智能体思考的分水岭(agentic thinking divide)。下面顺着它最硬的两个命题,为什么 scope(范围)决定一切、为什么这种优势会复利,把它一层层拆开。看完不用记结论,自己就能推出来。
采用,还是转型:两条路的区别一目了然
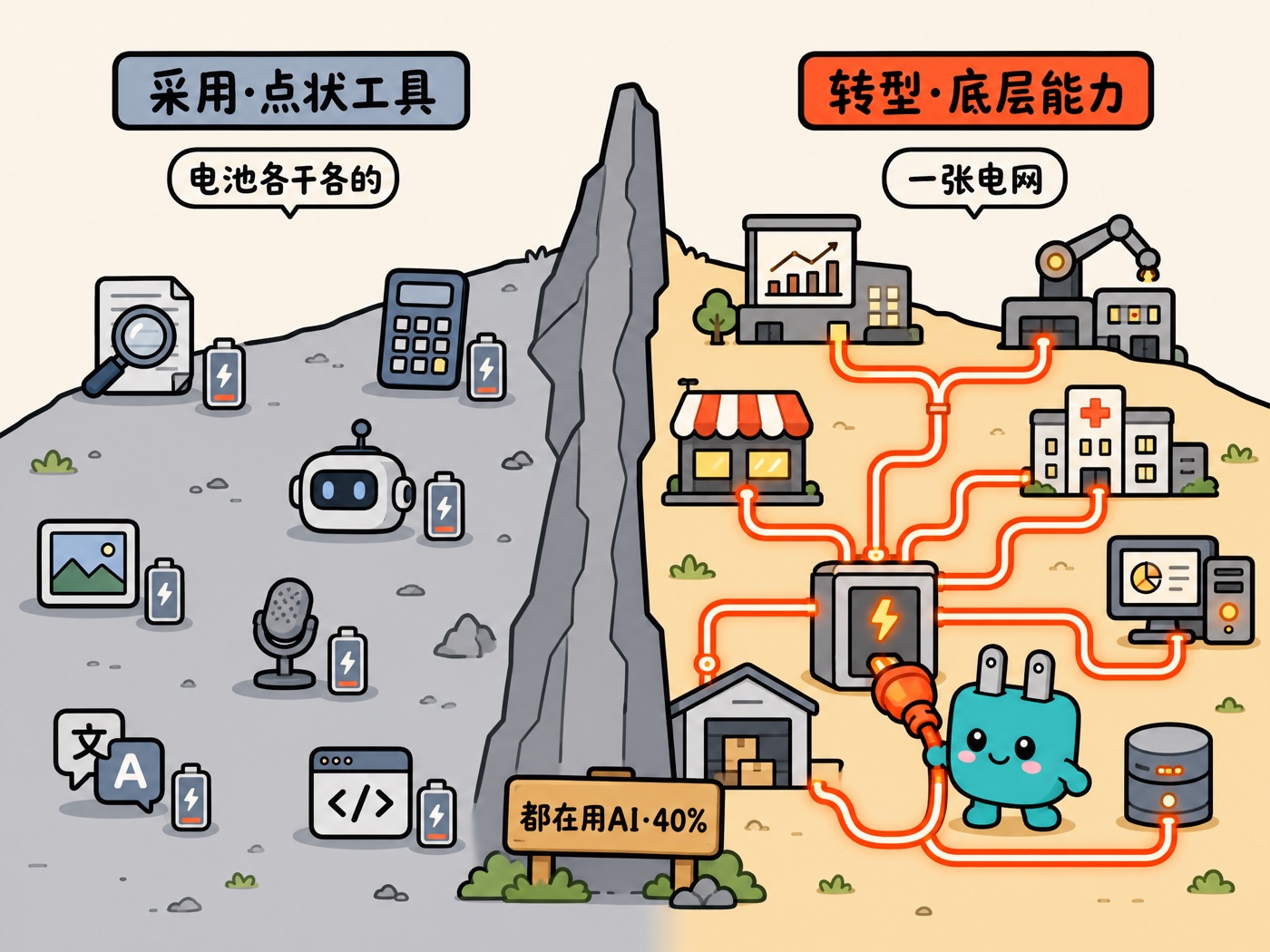
一句话:点状方案只会给你点状结果。每一个单独看都没毛病,demo 演示甚至很惊艳,但它们有个共同命运:永远停在试点阶段,对公司怎么运转一点没改。
chatbot 是问答机,agent 是会干活的同事。chatbot 你问一句它答一句,答完就忘;agent 是你交代一个目标,它自己拆解、决策、一步步执行到完成,边干边根据结果调整。很多所谓的「AI 转型」,其实只是把问答机摆了一排。你用问答机搭不出转型,这是第一性的限制。
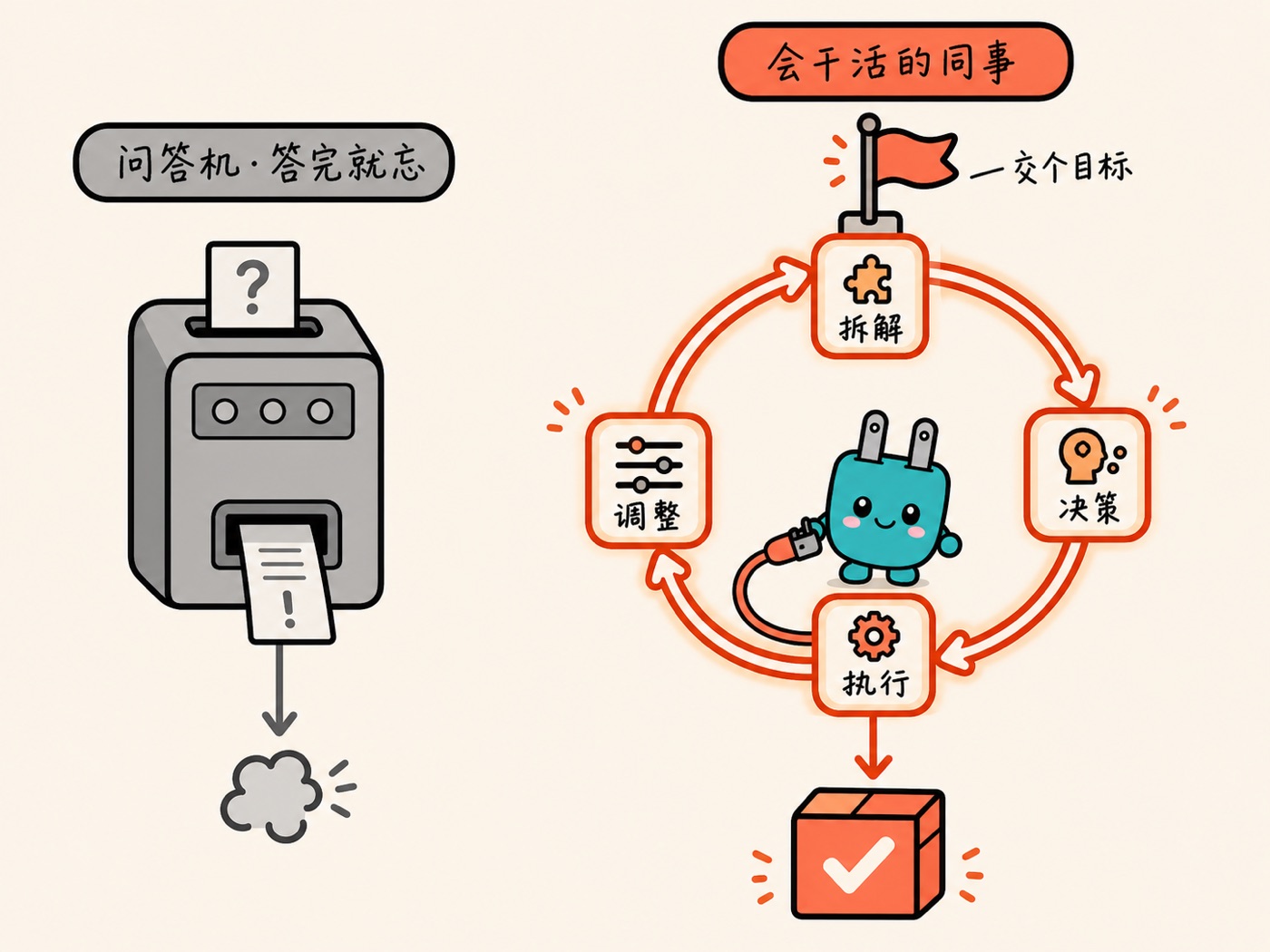
点状方案,为什么必然平庸
先把主张抛出来:把 AI 当孤立工具用的公司,结果注定平庸。这不是态度问题,是结构决定的。
这些工具吃的是「通用 AI」,而通用 AI 给的是通用产出:一份语法正确、结构完整、但谁看了都觉得「还得改」的东西。问题就出在这个「还得改」上。员工拿到 AI 起草的文档,发现它不懂公司的标准,不会用公司的术语,不知道那些写在老员工脑子里、从没落到任何文档上的机构知识(institutional knowledge)。于是员工还得花时间深加工,改到能用为止。
这是「AI 起草一份文档」和「AI 起草一份你团队能直接交付的文档」之间的区别。听起来只差几个字,中间隔的是一整个公司的上下文。前者是玩具,后者是生产力,而两者的差距不在模型,在你喂给它多少上下文。
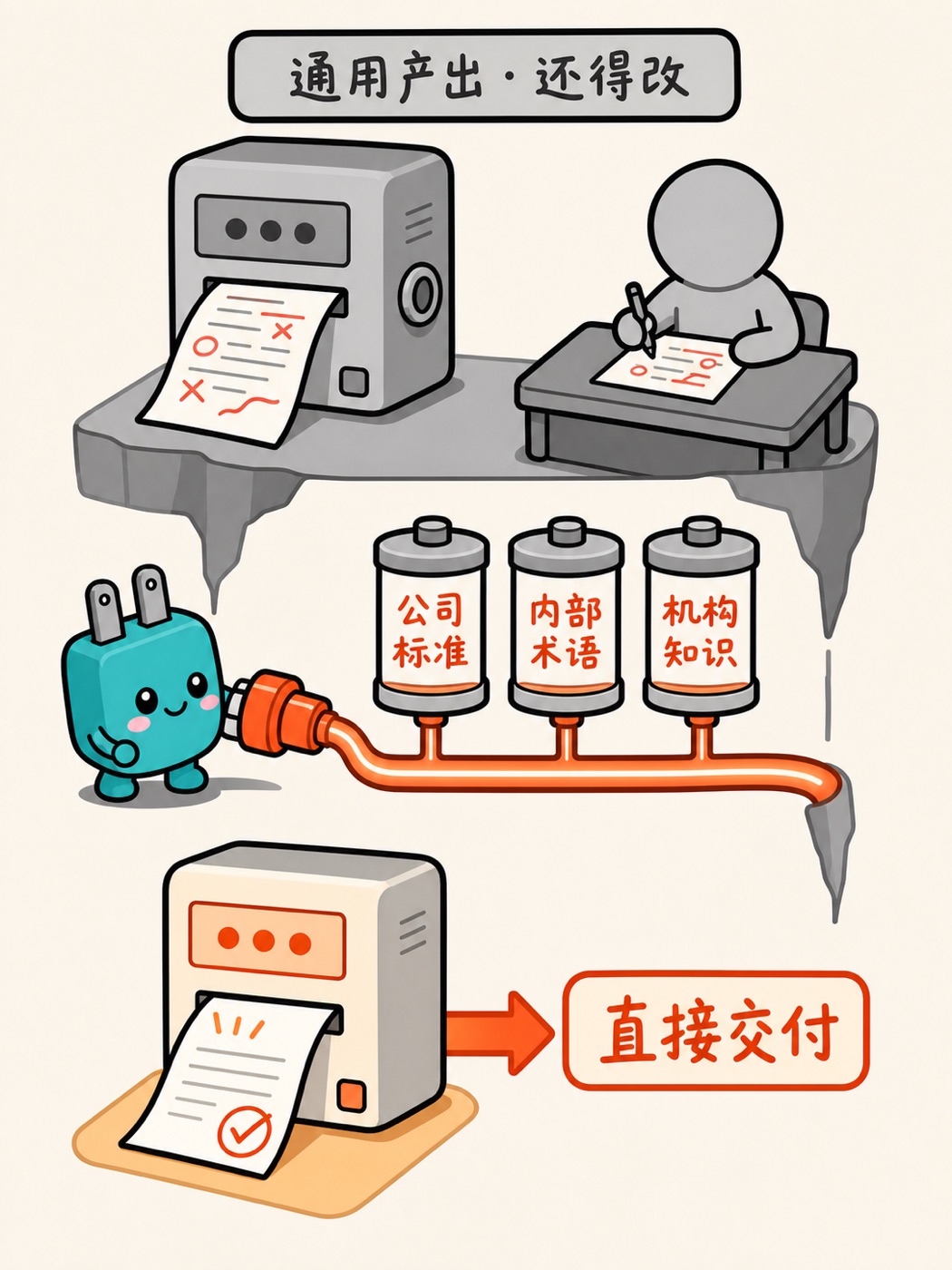
证据是什么?书里反复出现一个现象:两家公司用同一个模型,结果天差地别,差的就是喂进去多少组织上下文。这一句话其实已经把「模型决定论」判了死刑:如果同一个模型能产出截然不同的结果,那模型显然不是决定变量。决定变量是 scope。把 AI 当点状工具,你只能得到点状结果;把它当转型来做,你重构的是三样东西同时发生:员工怎么工作、流程怎么跑、能做出什么产品。
这三样,就是这本书的主框架:三根支柱。一根一根来看,每一根背后都站着一家真实的公司。
L'Oréal:把每个人的起跑线往前挪
回到开头那个销售。让那几秒钟成立的,不是模型变聪明了,是模型被接进了这家公司的真实数据流:CRM、会议录音、潜客调研。换个公司、换套数据,同一个模型干不出这份简报。
这事也不只发生在销售身上。财务接上数据仓库出对账报告;法务按公司自己的风险框架审合同、标出偏离条款;市场按品牌指南起草活动方案初稿。规律是一致的:价值的大小,等于你编码进去的组织知识的多少。
L'Oréal(欧莱雅)把这条规律量化了。想象它的处境:产品卖到 150 多个国家,数据散落在各处的管线里。一个员工想知道某个市场某条产品线最近卖得怎么样,得提一个需求,等数据专家给他建一个定制查询,然后祈祷专家理解对了他真正想问的问题。整个公司的数据能力就卡死在这个瓶颈上。
它的解法是基于 Claude 搭了一个内部 AI 平台:一个多智能体系统,把员工用大白话问的问题,自动路由到正确的数据源和 15 个以上的专业 agent,再综合成带图的答案。
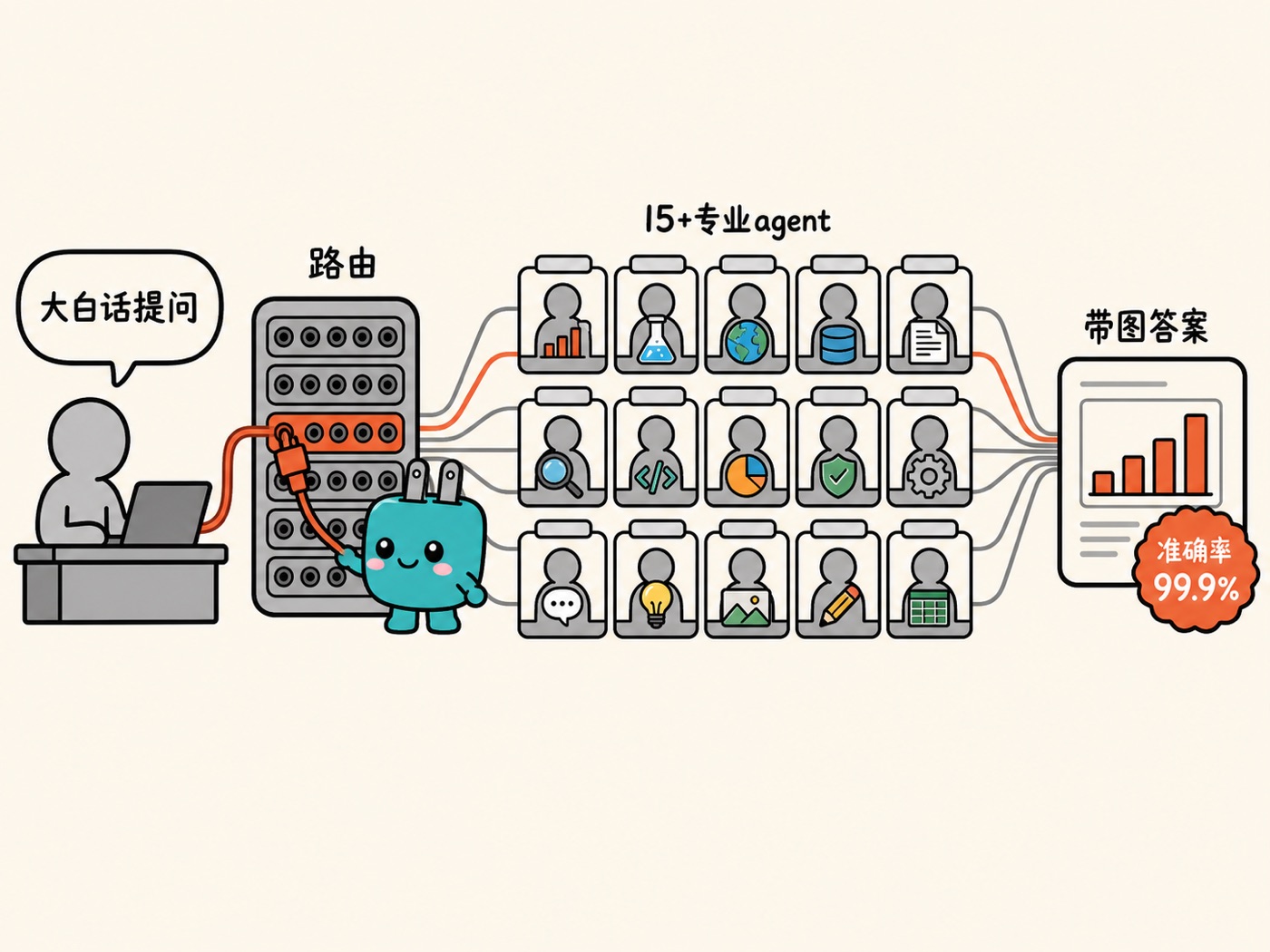
请注意这里的关键不是「换了个更强的模型」,而是 90 种方案对一个 99.9%:大量方案试过、都不行,行的那一个,是把 15 个专业 agent 和正确数据源编排到位的那一个。编排和上下文,才是从 90% 到 99.9% 那道鸿沟的填料。负责这个平台的 Thomas Menard(L'Oréal 智能体平台与 LAB 负责人)说:「我们的自动评估能力,比如 LLM-as-a-judge,已经多次证明了 Claude 模型的优越性。」
Lyft:把「几个月」压成「几分钟」
这根支柱讲的是另一种画面:不是某个人变快了,是整条流水线变快了。而且有个反直觉的规律:流程越复杂、信息越密集,收益越大。
原因还是那句:流程自动化的价值,只取决于背后的上下文。把标准、合规要求、机构知识建进系统,处理时间能从几个月降到几分钟,质量还不掉。成功长什么样:临床撰稿人从花几周拼一份报告,变成大部分工时花在审阅精修;合规官从花几天产出监管申报,变成几分钟生成初稿;整个团队从 80% 时间在产文档,变成 80% 时间在做判断。
容量转移:AI 不是替掉人,而是把人从「生产」挪到「判断」。机器接走体力活,人腾出手去干只有人能干的事。

Lyft 是这根支柱的硬证据。如果你深更半夜用出行平台遇上过麻烦,大概体会过那种烦躁:行程出了问题,打客服等三四十分钟才接通,对面那个客服还在同时应付三四个人,回复全是复制粘贴的模板。这正是 Lyft 曾经的处境:横跨六大洲、几千座城市,客服系统被推到临界点,客服自己的倦怠感也在往上飙。
Lyft 选 Claude 是认真比过的:一测性能本身,二测和品牌声音对不对得上。从司机支持做起,扩展到乘客支持、计费纠纷。现在的场景是:Claude 用客户的名字打招呼,针对具体情况去调查,几秒钟解决;只有真正需要人判断时,才把工单连同一份自己生成的对话摘要,一起路由给人工客服。
请留意这个因果链:解决时间降 87% 不是因为 Claude 比客服打字快,而是因为它被嵌进了 Lyft 的完整工单流程,能调查、能判断、能在该交给人的时候带着摘要交给人。这是嵌入深度的回报,不是模型速度的回报。
省下来的钱以百万美元计,Lyft 没揣进兜里,而是重新投回客服团队和新项目,其中一个叫 Lyft Silver,专为年长乘客做的一对一专属支持。AI 把人从机械劳动里解放出来,省下的成本变成了一个原来根本做不出来的、更有温度的新服务。
Rakuten:让客户做到他以前做不到的事
前两根支柱是对内的,这一根对外:AI 不只能帮你省钱,还能让你做出原来根本做不出来的产品。
书里点出一个共同模式:前沿 AI 模型 + 专有数据 + 既有信任关系 + 深厚领域专长。AI 只是那个使能者,真正的护城河来自它周围的这一切。所以产品层的机会绝不止「降本」,而是用新的产品能力创造净新增收入和会复利的竞争优势:先动的人建起集成、数据飞轮、客户习惯,让后来者难以追上。
trust boundary(信任边界):客户愿意把哪些数据交给你处理,这个范围就是信任边界。在金融、医疗这类受监管行业,数据安全和合规不是加分项,是入场券。任何在信任边界之外运行的 AI 产品,等于一个上不了线的产品。
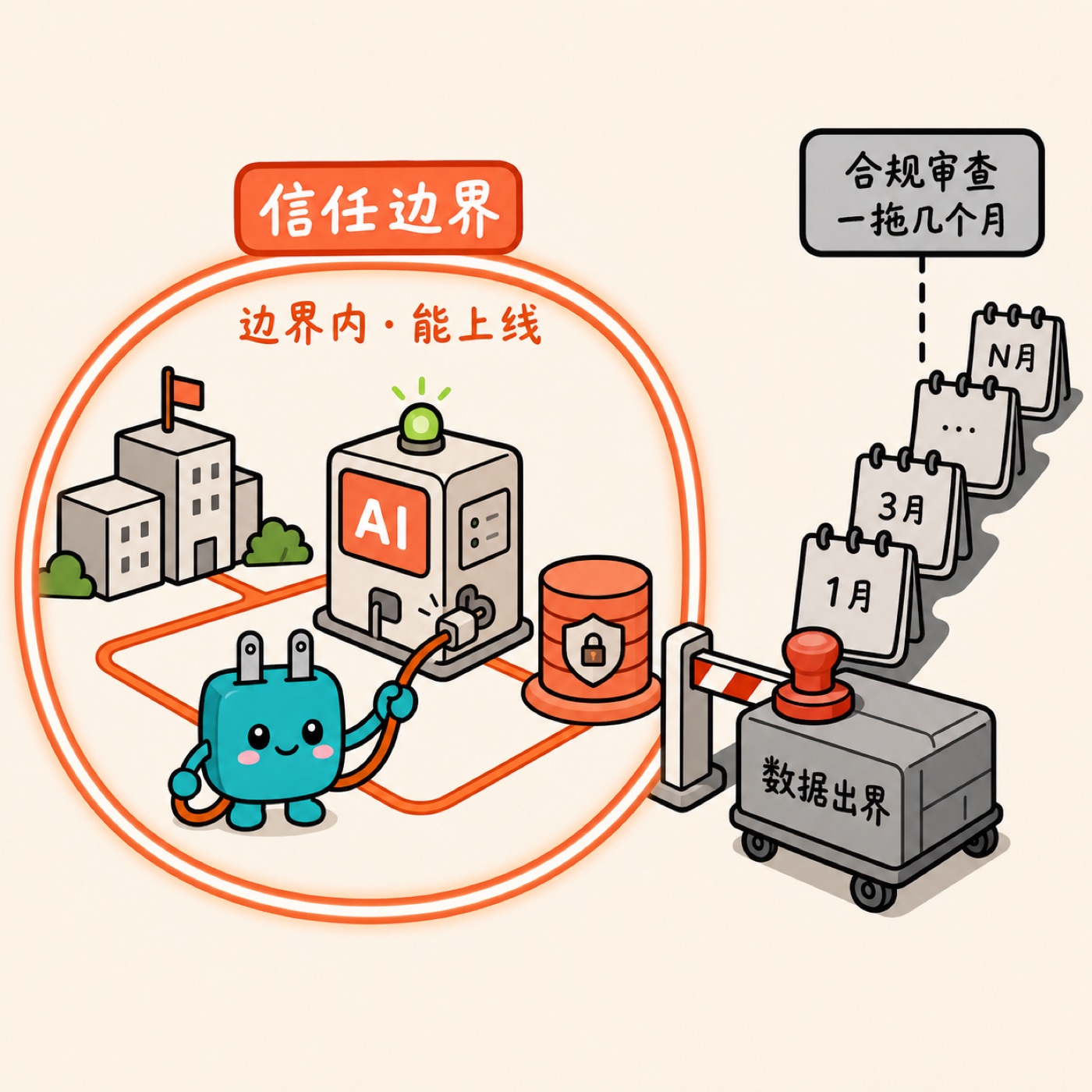
把这根支柱立得最完整的,是 Rakuten(日本乐天)。它运营着七十多项业务,全公司推一个「AI 化(AI-nization)」战略。它很早就看明白:agent 要真正干活,需要持久的计算、记忆、存储。于是工程师一开始是从零搭基础设施的。这个判断当时是对的,但代价是:本可以投到差异化创新上的顶尖人才,全耗在了搭地基上。
转折点是它采用了 Claude Managed Agents(Claude 平台提供的一套预先构建好、可配置的 agent 运行框架),把「执行层」这件脏活累活整个外包出去,让自己的工程人才回去专心打磨真正的 agentic 体验。效果像开了闸:一周之内,覆盖工程、产品、销售、市场、财务的专业 agent 就部署起来了,直连 Slack、Microsoft Teams 和自家看板系统,长时运行的任务一干就是几个小时。而且 agent 的记忆会复利:它记得过去犯过的错,于是不再重蹈覆辙。
但 Rakuten 最让人记住的不是数字,是一个画面。他们内部把那些跨领域贡献的超级用户叫「Galileo」(伽利略)。其中一个是产品经理,不是工程师。他独自一个人,在好几个公有云上搭起了一条 FinOps(财务运营)流水线,还自己设了一个在后台静默运行的监控 agent。过去这种事一个产品经理想都不敢想,得排着队去求工程团队。这就是 Rakuten 给出的那句结构性判断:agent 不是你未来的同事,也不是来抢饭碗的竞争者,它是公司用来加速建造一切的基础设施。
这种优势会复利,而不是线性增长
到这里前两个论点已经立住:点状方案平庸,转型靠组织上下文。但这还不够。如果优势只是一次性的「我比你强一截」,早晚会被追平。这本书最锋利的命题在第三层:这种优势会滚雪球,先动的人甩开后来者的距离,会越来越大。
复利从哪来?书里给了个很具体的机制,叫「准确率如何复利」。常规做法是:每次让专家从同一个基线去 review AI 的产出,专家累死累活,AI 永远停在原地。正确做法是:建一个系统,把人类专长的反馈喂回 AI 的知识库,每一次专家 review,都让未来每一个流程变得更好。这意味着 AI 的能力曲线是向上爬的,不是平的。
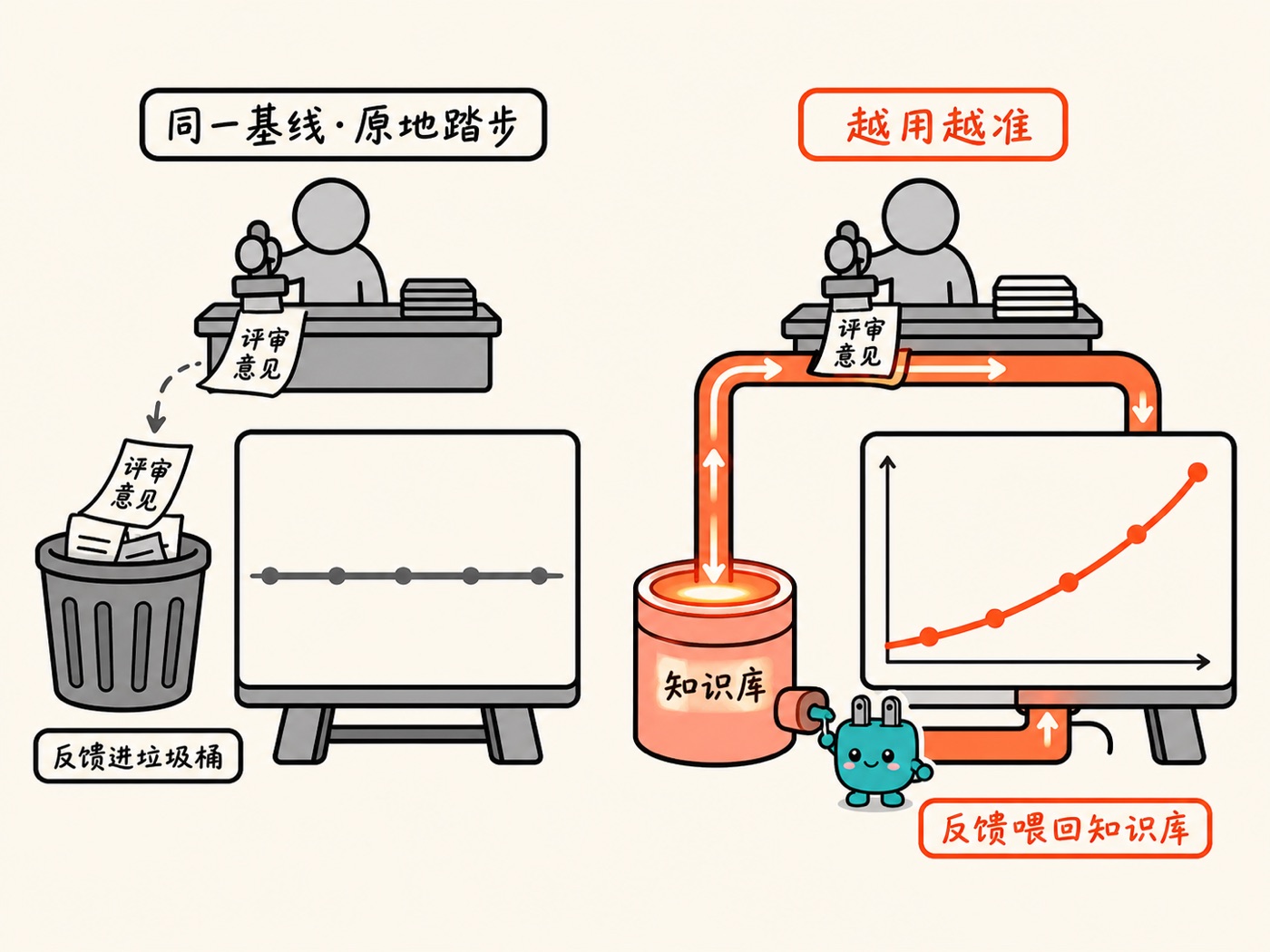
像老员工带新人。带过一次的经验会沉淀成流程手册,第二个新人就不用再从头教一遍,个人的学习瞬间变成整个组织的学习。前面 Rakuten 那句「agent 的记忆会复利」,就是这个机制的字面实现:一个 agent 踩过的坑,所有 agent 都不再踩。
把「工具」和「基础设施」区分开,是理解复利的钥匙:工具是你用完放回去的东西,价值固定;基础设施是你在上面继续盖楼的东西,价值随你盖的楼越来越多而上升。点状方案是工具,转型是在铺基础设施。这就是为什么前者线性、后者复利。
顺着这个机制推下去,结论很直接:最早开始的组织,积累的优势最大。因为每个月积累的审批记录、专家反馈、修正案例,都会让下个月的产出更快、更准。你晚开始一年,不是落后一年的差距,是落后「一年的复利」的差距:对手那一年里每个月都在变强,而你从零起步。
插件把机构知识变成了组织基础设施
逻辑链到这里已经闭合:点状平庸 → 转型靠上下文 → 上下文会复利 → 所以先动者赢。但这条链有个隐含前提:回头看前面所有案例,L'Oréal 的 15 agent 编排层、Lyft 的客服系统、Rakuten 的 Managed Agents,还有书里提到的 Novo Nordisk(NovoScribe 把一份临床研究文档从 10 多周压到 10 分钟)、RBC(智能体方案服务 2200 名顾问、管理 6890 亿美元资产),每一家都自己搭了一个定制平台,专门用来给 Claude 喂上下文。
回报可观,门槛也硬:都需要工程资源、时间、技术专长。这场游戏的起跑线,被设在了「你得有工程团队能自建平台」这里。绝大多数知识工作者被挡在门外。
Claude Cowork 改变了这个等式。它让非技术人员拿到企业在 API 上自建的同样的 agent 能力,却不用做任何定制开发。你交给它一个任务,它还给你的不是一段建议、一份大纲,而是真正做完的东西:一份 Word、一张 Excel 模型、一套幻灯片、一份分析报告。
它背后的机制是 plugins(插件):把 skills(技能)、上下文、连接器打包成一个插件,给 Claude 一种角色专属的专长。机构知识本来锁在老员工脑子里、随人走人散,现在被打包成插件,可复制、可共享、可积累,等于把「个体学习变组织学习」这件事工程化了。Anthropic 已经开源了 11 个插件,覆盖生产力、销售、财务、数据、法务、市场、客服、产品管理、企业搜索、生物学研究,以及插件管理本身。
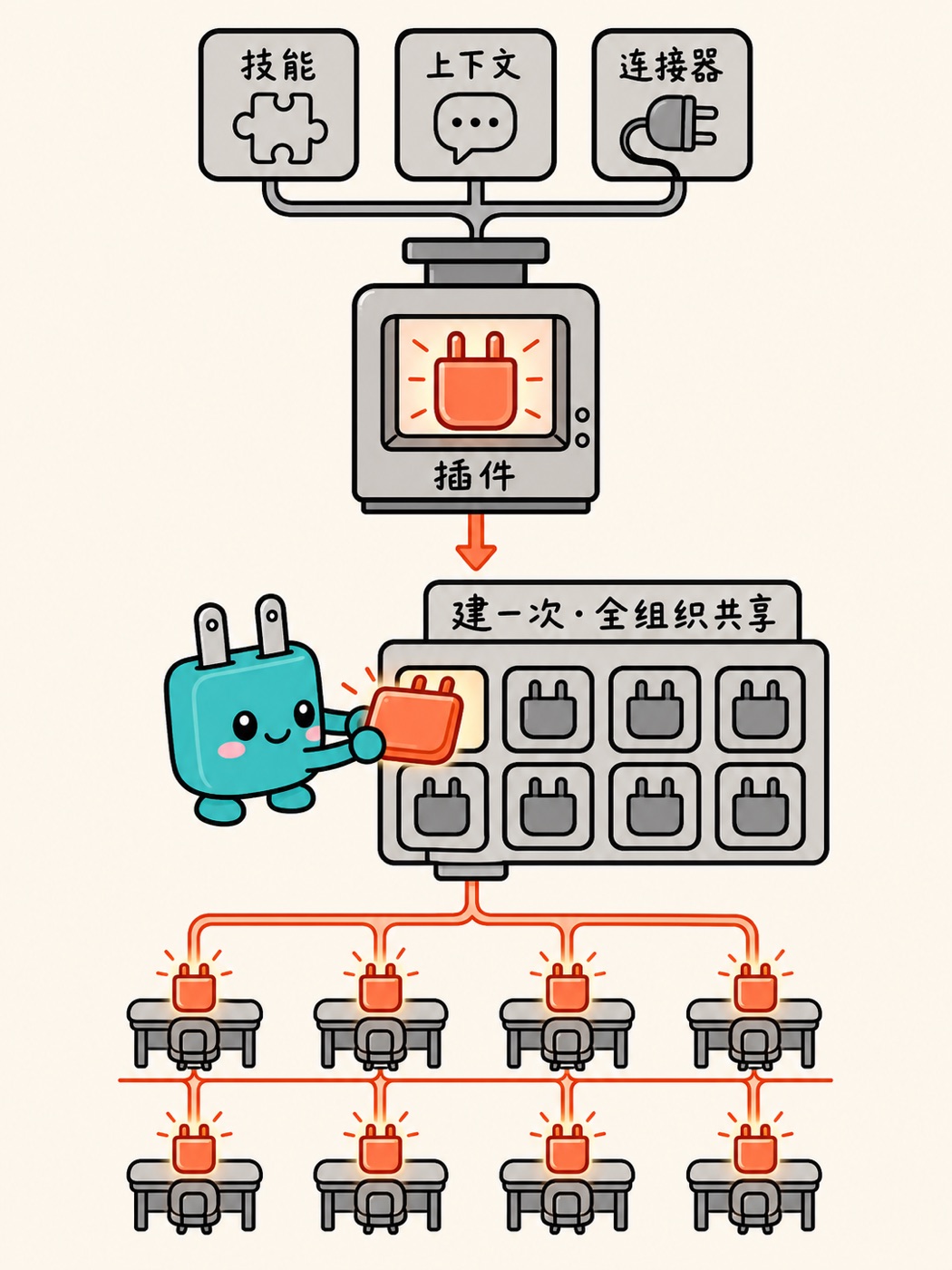
要让这套东西在企业里真正跑得住,书里列了企业级四要素:治理控制(组织专属插件市场,把治理从被动关停变成主动策展分发,杜绝 shadow AI 野蛮蔓延);安全设计(任务在本地跑,什么都不上传云端处理,在「企业 AI 最常见的反对意见」被提出之前就解决它);可审计(兼容 OpenTelemetry,能精确看到 AI 在何时、代表谁、做了什么);集成与连续性(在已有的 CRM、文档系统里工作,在 Cowork 和 Excel、PowerPoint 之间切换不丢上下文)。
四条原则 + 三阶段时间表,全文照录
讲了这么多别人的故事,最后落到自己身上。书里给的落地方法就两块:四条原则,每一条都在反一个常见的冲动;一条六个月的时间轴,把原则落到日历上。这两块是全书最值钱的可执行部分,中文全译照录如下,可直接抄走照做。
① 从具体性起步,不是从规模起步
一开始就把你的标准、你的工具、你的机构背景喂给 Claude。第一次交互就拿到通用产出的员工,很少会给这个工具第二次机会。本指南里的组织之所以成功,是因为它们给了 Claude 足够的上下文,让产出读起来像出自一个真正懂这家公司业务的人。
② 选有可衡量终点线的试点
三根支柱各有各的成功指标:员工提效看采用率和省时;流程加速看周期压缩和质量分;产品变革看收入影响和上市速度。在试点开始前就把成功标准定义清楚,结果才不含糊。
③ 从第一天起就为复用而建插件
诱惑总是先给一个团队搭个快速方案,复用的事以后再说。抵住这个诱惑:为一个团队建的插件应该让整个组织受益。把部落知识编码一次,之后每个安装该插件的团队都立刻获益。共享一个插件的边际成本为零,边际价值却巨大。
④ 永远别低估治理层
管理控制、可审计性、组织专属市场是大规模推广的前提条件,不是等采用起飞后再补的功能。早期跳过治理的组织,事后清理越权使用花掉的时间,比抢跑省下的还多。
英文原文对照
• Start with specificity, not scale. Give Claude your standards, your tools, your institutional context from the beginning. Employees who receive generic output from a first interaction rarely give the tool a second chance. The organizations in this guide succeeded because they gave Claude enough context to produce output that felt like it came from someone who understood the business. • Choose pilots with a measurable finish line. Each of the three pillars has different success metrics. Smarter employees might be measured by adoption rates and time savings. Faster processes might be measured by cycle time compression and quality scores. Transformative products might be measured by revenue impact and speed to market. Define your success criteria upfront, before the pilot starts, so the results are unambiguous. • Build plugins for reuse from the beginning. The temptation is to build a quick solution for one team and worry about reuse later. Resist that temptation. Plugins built for one team should benefit the entire organization. When you encode tribal knowledge once, every team that installs the plugin gets the benefit immediately. The marginal cost of sharing a plugin is zero, while the marginal value is enormous. • Never underestimate the governance layer. Admin controls, auditability, and organization-specific marketplaces are prerequisites for broad rollout, not features you add after adoption takes off. The organizations that skip governance early spend more time cleaning up unsanctioned usage than they saved by moving fast.
设定评估与成功标准
最初几周只专注一件事:评估与成功标准。找出 2 到 3 个痛点明确、工作流可衡量的团队;从开源仓库安装相关插件,或构建编码了你们团队标准与流程的自定义插件;在任何人开始使用之前,先定义「成功长什么样」。
举例:销售团队可以是「通话准备时间减少 50%」;法务团队可以是「合同审查周转从 5 天压到 1 天」;文档团队可以是「初稿质量达到最终批准版的 80%」。成功标准的具体程度很关键:「提升生产力」这种模糊目标,只会产出容易被否定的模糊结果。
启动冠军试点
第二、三个月是冠军试点:2 到 3 个团队在真实生产工作流(不是沙箱实验)里使用配置好插件的 Claude Cowork。每周衡量采用率;定量指标之外同步收集定性反馈,因为员工发现意外价值的时刻,往往比省时计算更有信息量。
这个阶段的目标不是完美,而是价值证明,以及搞清楚大规模推广前还需要改什么。
规模化影响
拿到成功的概念验证后,第四到六个月转向规模化和治理:部署管理员市场控制,建立插件审核与批准流程,用试点期打磨好的插件和配置向更多团队铺开。
每个新上线的团队都能吃到已经编码好的机构知识,所以第二波推广比第一波快,第三波更快。这就是复利动态的实际运转:每一次在上下文、配置、治理上的投入,都让下一次部署更便宜、更有效。
英文原文对照
Phase 1: Setting evaluation and success criteria For the first several weeks, focus exclusively on your evaluation and success criteria. Identify two to three teams with clear pain points and measurable workflows. Install the relevant plugins from the open-source repository or build custom plugins that encode your team's specific standards and processes. Define what success looks like before anyone starts using the tool. For a sales team, for example, that might be call prep time reduced by 50 percent. For a legal team, it might be a contract review turnaround cut from five days to one. For a documentation team, it might be first-draft quality reaching 80 percent of the final approved version. The specificity of the success criteria matters: vague goals like "improve productivity" produce vague results that are easy to dismiss. Phase 2: Launching a champion pilot The second and third months of the initiative are the champion pilot. Two to three teams use Claude Cowork with their configured plugins in production workflows, not sandboxed experiments. Measure adoption weekly. Collect qualitative feedback alongside quantitative metrics, because the moments when employees discover unexpected value are often more informative than time-saved calculations. The goal of this pilot phase is not perfection but proof of value and a clear understanding of what needs to change before broader rollout. Getting started with Claude Cowork in the help center provides practical guidance for configuring access and managing this initial deployment. Phase 3: Scaling impact Successful proof of concept in hand, months four through six shift to scaling and governance. It's time to deploy the admin marketplace controls, establish plugin review and approval workflows, and begin the rollout to additional teams using the plugins and configurations refined during the pilot. Each team that comes online benefits from the institutional knowledge already encoded, which means the second wave of adoption moves faster than the first. The third wave moves faster still. This is the compounding dynamic in action: every investment in context, configuration, and governance makes the next deployment cheaper and more effective.
其中「第二波比第一波快,第三波更快」那句,就是前面复利机制落到日历上的样子:不是因为模型变好了,是因为前面攒下的上下文、配置、专家反馈,全都在替你加速。
你不需要完美计划,你需要一个具体的起点
我们从一个销售在电话响起前的几秒钟开始。现在你大概看清了,那几秒钟里藏着的,不只是省下来的几小时。
把整条逻辑链收一下:模型不是决定性变量,证据是同一个模型在不同公司结果天差地别;决定性变量是 scope,你把 AI 当点状工具,还是当转型底座。点状方案必然平庸,因为它吃通用产出,而通用产出永远「还得改」。转型靠的是把组织上下文编码进系统,三根支柱的案例数字(L'Oréal 的 99.9%、Lyft 解决时间降 87%、Rakuten 关键错误降 97%)反复证明:拉开差距的是嵌入深度和上下文厚度,不是模型本身。而这种优势会复利:专家反馈喂回知识库、agent 记忆累积、插件把机构知识变成可共享的基础设施,所以先动者甩开后来者的距离会越来越大。
书里点出了那个最常见、也最致命的错误:等到战略完整了才迈第一步。成功的组织恰恰相反,它们从一个很窄的口子切进去,快速学习,然后带着信念扩张。你不需要一个完美的计划,你需要的只有三样:一个具体的起点,一套可量化的成功标准,以及从接下来真实发生的事里继续学习的意愿。