プロダクト発表 · 小互解読
GPT‑5.6 がリリース、でも実質まだ出ていないも同然
フラッグシップ Sol、バランス型 Terra、低価格 Luna の三段を一挙に投入、サイバーセキュリティが今世代の主力方向。だがまず信頼できるパートナーに限定提供、名簿は米政府に届け出済み、数週間後にようやく広く開放。
概要
- OpenAI は 2026 年 6 月 26 日に GPT‑5.6 シリーズの限定プレビューを開始、フラッグシップ Sol、バランス型 Terra、低価格型 Luna の三モデルを一挙に投入。
- 新しい命名を採用:数字は「第何世代か」、Sol/Terra/Luna は「能力グレード」を表す。Terra は前世代 GPT‑5.5 に近い性能で、価格は半分。
- 能力向上はコーディング、バイオ、サイバーセキュリティの三分野に集中、Terminal‑Bench 2.1 などのベンチマークで記録を更新。ただし全データは OpenAI の自己評価で、完全な評価は広く開放される際に公表予定。
- 史上最強と称する安全スタックを付属:多層防護を重ねて連携させ、70 万 A100 等価 GPU 時間超を投じた自動化レッドチームで汎用ジェイルブレイクを探索。
- 米政府の要請でまず少数の信頼できるパートナーに限定提供(名簿は届け出済み)、数週間後により広く開放。価格は 100 万 token あたり:Sol $5/$30、Terra $2.5/$15、Luna $1/$6。
⚑立場の注記:本記事は OpenAI 公式の発表ブログに基づく、メーカー側のプレスリリースである。文中の能力の飛躍、ベンチマーク成績、安全スタックの強度はいずれも OpenAI 一方の主張で、独立した第三者による検証は経ていない。プレビュー期間中は OpenAI 自身も、安全機構が正当なリクエストを誤って遮断しうると認めている。以下では何を述べ、どう動くかを解読するだけで、読者に代わって採点はしない。
1リリース概観
GPT‑5.6 登場、しかも一挙に三つ
OpenAI は 2026 年 6 月 26 日に GPT‑5.6 シリーズの限定プレビューを開始、フラッグシップ Sol、バランス型 Terra、低価格型 Luna の三モデルを一挙に投入した。
これは普通のバージョン更新ではない。OpenAI は「モデル能力の飛躍」と「政府向けプレビューの手続き」を一つに束ねた。公開前にまず能力とリリース計画を米政府に見せ、政府の要請に従ってまず少数の信頼できるパートナーにのみ開放し、数週間後にようやく広く解放する。
⚡注目に値する理由:OpenAI が初めて、モデル能力の飛躍を政府向けプレビュー手続きと結びつけてリリースした。サイバーセキュリティは今世代の重点強化方向で、パートナー名簿は政府に届け出済み、70 万 A100 等価 GPU 時間超を自動化レッドチームに投じた。OpenAI は同時に、こうした政府承認の手続きが長期的な既定になることは望まないと明言している。
2モデルの選び方
三モデル、結局どう選ぶか
同じ世代に三段を用意、違いは「どれだけ強いか、速いか、高いか」。下のいずれかをクリックして、何に向くか見てみよう。
↓ 一つクリックして適した用途を見る
Sol:OpenAI が史上最強のモデルと称し、二つの新モードを備える。max(モデルに最大限の時間を与えてじっくり考えさせる)と ultra(複数のサブエージェントを動員し手分けして並行処理)。最も難しく入り組んだコーディング、研究、サイバーセキュリティなどの長い連鎖タスクに対応。
Terra:日常の主力。OpenAI によれば前世代 GPT‑5.5 に近い性能で価格は半分、「十分に強くてかつ節約したい」大半の日常業務に対応。
Luna:最速で最安。OpenAI によれば最低価格帯でも相応の能力を保ち、大量処理やレイテンシ・コストに敏感な場面に対応。
新しい命名の読み方
以前は一つの数字で全てを表し、能力グレードも新旧もその数字に混ざっていた。今回は二つの軸に分けた。数字が「世代」を、名前が「能力レベル」を担い、それぞれが自分のペースで更新される。
旧命名
一つの数字が全てを決める:GPT‑5、GPT‑5.5……大きいほど新しいが、「もっと安くて速い版が欲しい」場合は次のマイナーバージョンを待つしかない。
新命名
数字(5.6)は第何世代かだけを示す。Sol/Terra/Luna が能力グレード(強/バランス/速くて安い)を示す。同じ世代の中でニーズに応じて直接選べる。
3能力の飛躍
今世代は結局どこが強いのか
OpenAI が打ち出した能力向上は三分野に集中:コーディング、バイオ、サイバーセキュリティ。それぞれにベンチマーク成績を示している。
コーディング · Terminal‑Bench 2.1
コマンドラインのワークフローを問う。計画立案、試行錯誤の反復、複数ツールの協調が必要。GPT‑5.6 Sol が最高成績(SOTA)を更新。
OpenAI 自己評価
バイオ · GeneBench v1
長い連鎖のゲノミクスと定量的バイオ分析を問う。Sol は前世代 GPT‑5.5 より強く、しかも少ない token で済む。
OpenAI 自己評価
サイバーセキュリティ · ExploitBench / ExploitGym
ExploitBench では Mythos Preview と互角だが、出力 token は約 1/3 のみ。ExploitGym(UC Berkeley が OpenAI などと共同で作ったベンチマーク)では、推論量を増やすにつれ Sol/Terra/Luna のサイバーセキュリティ能力がいずれも伸びることを示す。
OpenAI 自己評価、比較条件はメーカー設定
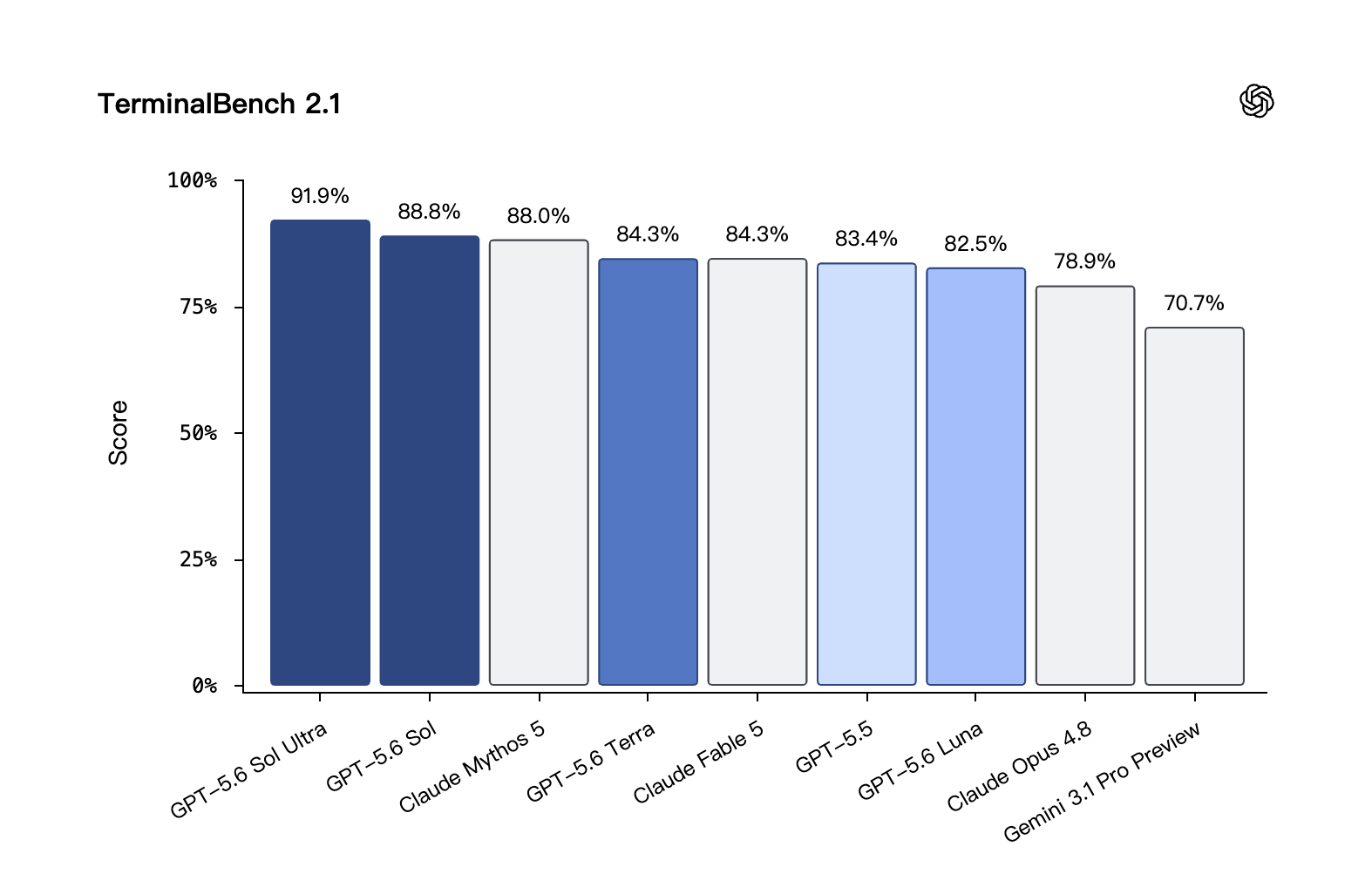
コーディング · TerminalBench 2.1:GPT-5.6 Sol Ultra が 91.9% でリード、基本版 Sol(88.8%)も Claude Mythos 5(88.0%)を上回る。出典:OpenAI 自己評価。
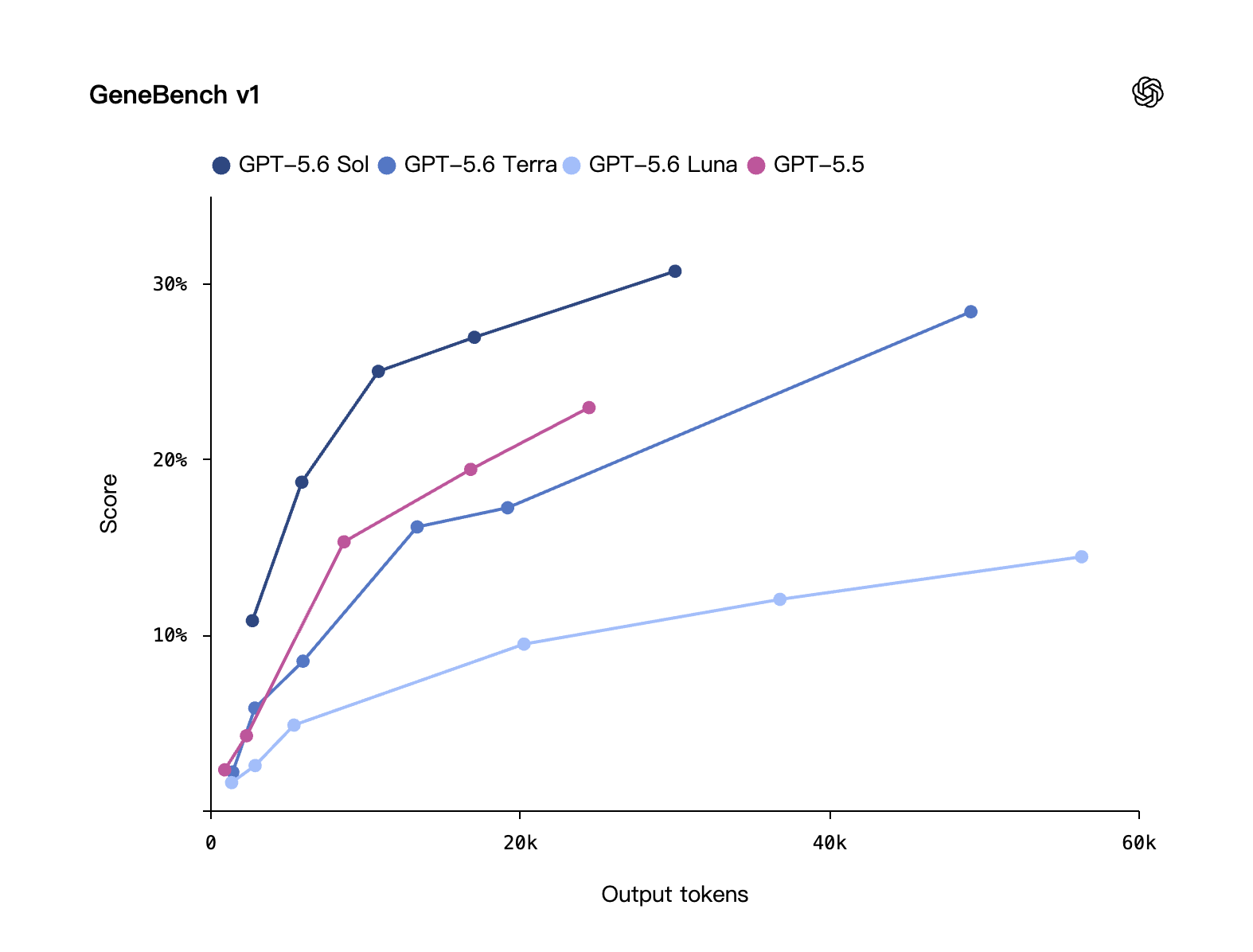
バイオ · GeneBench v1:横軸は出力 token、縦軸はスコア。GPT-5.6 Sol はより少ない token で高いスコアを獲得。出典:OpenAI 自己評価。
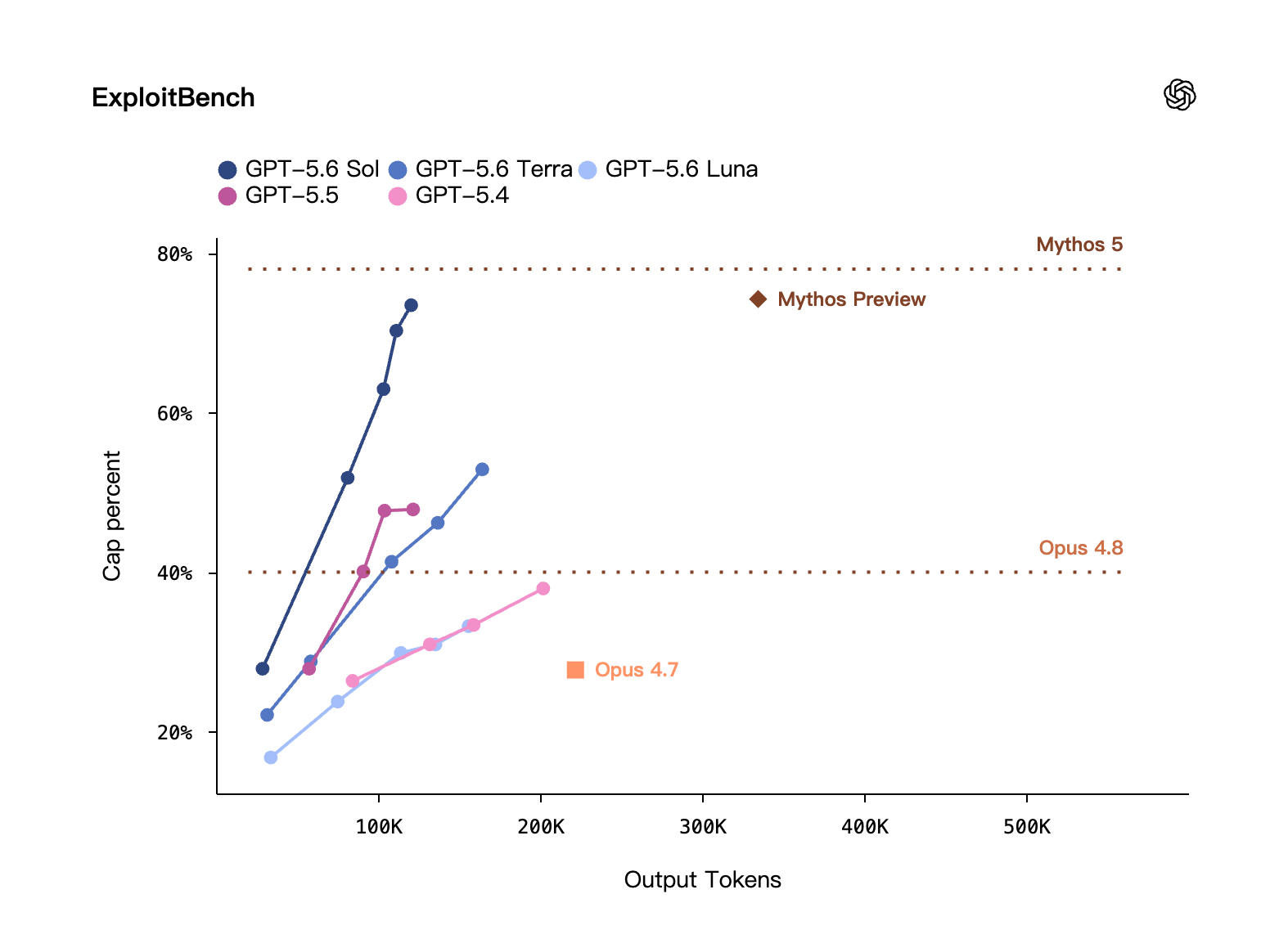
サイバーセキュリティ · ExploitBench:縦軸は cap percent、横軸は出力 token。GPT-5.6 Sol は Mythos 5 の水準(上部の破線)に迫り、しかも token は約 1/3 のみ。出典:OpenAI 自己評価。
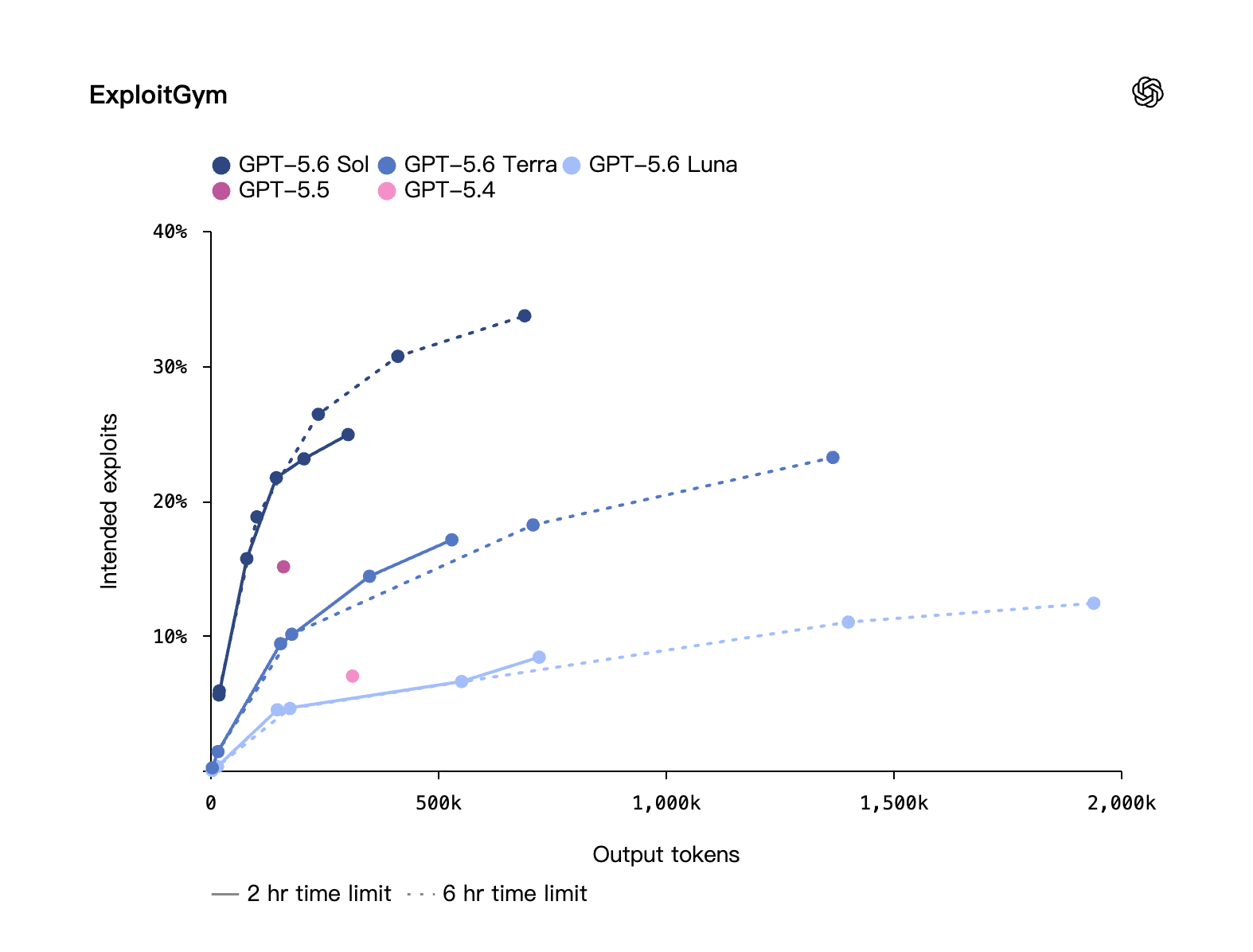
サイバーセキュリティ · ExploitGym:縦軸は intended exploits、横軸は出力 token。推論量(token)が大きいほど、Sol/Terra/Luna の攻防スコアが高くなる。出典:OpenAI 自己評価(UC Berkeley など共同ベンチマーク)。
二つの新モード:max と ultra
max
モデルに最大限の時間を与えてじっくり考えさせる。最も難しく、何度も練り直しが必要な問題に対応。
ultra
一つのエージェントに頼らず、複数の「サブエージェント」を臨時に動員し手分けして並行作業。複雑なタスクを加速し、単一エージェントの能力の上限を超える。
たとえるなら
max は一人にもっと長く考えさせること。ultra は臨時に小隊を組み、手分けして同時に進めること。
4サイバーセキュリティの一線
攻撃兵器の作成を手伝う?一線を越えたか
今世代はサイバーセキュリティ能力が強まり、当然こう懸念する人もいる。攻撃兵器を直接作るのを手伝うのではないか?OpenAI の答えは、「部品」は作れるが、テスト内では自力で「完成品」を組み上げてはいない、というものだ。
まず二つの語を区別
exploitation primitives(脆弱性の部品)は攻撃用の積み木、たとえばメモリ境界外アクセス一つ。full‑chain exploit(完全な攻撃チェーン)は部品を組み上げ、押せばすぐ使える完成品の兵器。モデルは部品は作れるが、テスト内で自力で発砲できる「銃」を組み上げてはいない。
Chromium と Firefox を含む評価では、GPT‑5.6 Sol は bug と exploitation primitives を見つけられたが、テスト条件下では使用可能な完全な攻撃チェーンを自律的に作り出すことはなかった。OpenAI の Preparedness Framework(独自に定めた危険対応フレームワーク)では、Cyber Critical の一線を越えていないと判定された。つまり「重要な攻撃能力を備え、より強い管理を発動させねばならない」その線には達していない。
Cyber Critical 一線
GPT‑5.6 Sol
評価位置
✓できること:bug と exploitation primitives(脆弱性の部品)を見つける。
✕テストでできなかったこと:使用可能な full‑chain exploit(完全な攻撃チェーン)を自律的に組み上げる。
→結論:評価位置は一線の下にあり、エンドツーエンドで攻撃を仕掛けるより「脆弱性を見つけ、直す」方が得意。
ただしベンチマークの一線では、モデルと他のツールを組み合わせた後のあらゆる実利用を覆い切れない。この不確実さに能力の全体的な飛躍が加わったことこそ、今世代がより強い防護を備え、段階的にリリースされる理由だ。
5核心 · 多層安全スタック
六つの関門で不正リクエストを阻む
いわゆる「史上最強の安全スタック」とは、より高い一枚の壁ではなく、六層の防護を重ねて連携させたもの。OpenAI の言い分は単刀直入だ。固い決意で臨機応変に動く悪用者の前では、いかなる単一の防護も不十分である。
能力が強いほど関門は増える。ある高リスク要求は第二層(リアルタイム検査)で阻まれ、ある正当な要求は六層を通り抜けてユーザーへ届く。各層はそれぞれ別のものを阻む役目を担い、重ねることで単層より堅くなる。
核心の革新今世代の最も特別な点はモデル自体ではなく、「モデルを強くする」ことと「悪用を難しくする」ことを同時に積み増している点にある。能力を一段引き上げれば防護も数層上乗せし、設定も各モデルの能力に応じて個別に調整する。
1
モデル内で訓練された拒否
訓練段階でモデルに、違反するサイバー攻撃の要求を拒むことを教え込む。ユーザーが意図を偽ったりジェイルブレイクを試みても同様。これが第一の境界で、モデルが何を手伝い、何を手伝わないかを決める。
2
生成時のリアルタイム検査
cyber と biology 二種類の悪用分類器が、生成しながら出力をスキャンする。高リスクの状況で違反の疑いを見つけると、生成は一時停止し、より大きな推論モデルに再審査を委ねる。
3
アカウント単位の信号
フラグの付いた活動が、対話をまたぐアカウント単位の再審査を引き起こす。一文だけでなくアカウント全体を見ることで、「継続的な悪事」と「正常なデュアルユースのセキュリティ作業」を区別できる。
4
差別化アクセス
最も機微な能力は既定で全員に開放せず、しかしコードレビュー、脆弱性研究、パッチ開発、デバッグ、セキュリティ教育といった正常な防御作業の経路は残す。
5
監視と執行
利用規約とポリシーに沿って内容の保存、再審査、対応を行い、違反行為に対して措置を取る。
6
継続的テスト
プレビュー期間中はレッドチームとストレステストを継続し、新たに見つかった脆弱性を防護へ補い、仕組み全体を攻撃手法とともに進化させる。
デュアルユースの難題:防御と攻撃は一見よく似ており、同じ技術概念がまったく異なる文脈に現れる。だからプレビュー期間の安全機構は、一部の正当な作業を誤って阻んだり、一時停止と再審査で正常なタスクを遅くしたりしうる。これこそプレビュー段階で検証すべきことの一つだ。
6遮断はどう起きるか
危険な質問がシステム内を一巡する
前節の第二層「リアルタイム検査」だけを取り出して辿ってみる。高リスクの要求が入ってきたとき、「生成を途中で一時停止、より大きなモデルが再審査、不適合なら阻止」がどう起きるのか。
要求が入る
→
生成しながら分類器がスキャン
→
高リスクに該当、一時停止
→
より大きな推論モデルが文脈を読み再審査
→
違反と判定、ユーザー到達前に遮断
肝心なのは検査が「生成しながら」行われる点だ。cyber と biology の分類器がモデルの吐き出している内容をリアルタイムで見張り、高リスクの状況で違反の疑いを見つけた瞬間に生成を一時停止し、より大きな推論モデルに対話と文脈の全体をもう一度読み直させる。再審査で違反と認められれば、この出力はユーザーの目の前に届く前に差し止められる。
7自動化レッドチーム
AI で AI を防ぐ
防護は、攻撃者がいつでも手口を変えてくるのにも耐えねばならない。既知の攻撃の固定リストにだけ効く防護は、最前線のモデルには不十分だ。そこで OpenAI は今回、大量の計算力を「モデル自身に脆弱性を探させる」ことへ投じた。
700,000+
自動化レッドチームに投じた A100 等価 GPU 時間、汎用ジェイルブレイク専門の探索
汎用ジェイルブレイク
自動化レッドチームの主目標:多様な質問・場面をまたいで通用する脆弱性
二つの語をまず明らかに
universal jailbreak(汎用ジェイルブレイク)は一枚の扉しか開けない鍵ではなく、万能の鍵だ。多くの質問や場面をまたいで効くため最も危険で、レッドチームはこれを狙い撃ちする。A100 等価 GPU 時間とは、計算力を「A100 一枚で何時間動かしたか」という統一単位に換算したもの。70 万時間は、おおよそ一枚のカードを約 80 年連続で回す計算量の規模に相当する。
なぜ純粋な人手でなく自動化を使うのか。OpenAI の理由はこうだ。自社のモデルに弱点を探させれば、人手よりはるかに多くの攻撃パターンを網羅でき、失敗の規則性をより早く見つけ、「弱点の発見」から「弱点の補修」までの道のりも縮められる。こうしたより難しく汎用的な攻撃に専念することは、既知の固定された脆弱性の外にもう一層検証を加えるに等しい。
人手のレッドチームと迅速対応はどう補うか
自動化に加え、OpenAI は第三者のテスターにも大規模な人間専門家レッドチームを依頼し、プレビュー期間中も継続する。人間のレッドチームが補うのは発想の死角、つまりシステムが予期できない、人間の頭で考え出される悪用の手口だ。
OpenAI も、あらゆる製品構成、多段階の攻撃、現実のワークフローを網羅できる評価は存在しないと認めている。そのため迅速対応のプロセスを維持する。新たに見つかったジェイルブレイクを再現し、評価し、優先順位を付け、修補したうえで日常の評価に組み込み、今後は同種の失敗を検出できるようにする。
8リリースの進め方と価格
なぜ先に政府へ見せ、後であなたに使わせるのか
今回の「限定プレビュー」は OpenAI の長期的な意向ではなく、米政府の要請に応じた短期的な一手だ。リリースの経路はこう進む。
公開前 · 政府へのプレビュー
米政府との継続的な対話の一環として、OpenAI はリリース前に発表計画とモデル能力を政府に見せた。
現在 · 信頼できるパートナーに限定
政府の要請で、まず API と Codex を通じて少数の信頼できるパートナーと機関に開放し、名簿は政府と共有済み。プレビュー期間はテストを続け、パートナーと密に連携する。
数週間後 · より広く開放
Sol/Terra/Luna を、ChatGPT、Codex、API を使う人々へより広く開放する計画。
OpenAI の姿勢:こうした政府承認の手続きが長期的な既定になるべきとは考えていないと明言する。なぜならそれは、最良のツールを本当に必要とするユーザー、開発者、企業、サイバー防御者の手に届かなくしてしまうからだ。それでもこの一手を踏むのは、政府とともにサイバーセキュリティの大統領令の枠組みを築き、将来のモデルリリースに向けた再利用可能なプロセスを定めると同時に、これが数週間後のより広い開放へ至る最も確実な道だからだという。
価格:100 万 token あたり
| モデル | 入力 | 出力 | 位置づけ |
|---|
| Sol | $5 | $30 | フラッグシップ最強 |
| Terra | $2.5 | $15 | バランス日常 |
| Luna | $1 | $6 | 最速最安 |
キャッシュ面はより予測しやすい。明示的な cache breakpoints(キャッシュの区切り点を自分で指定)に対応し、30 分の最小キャッシュ保持時間を設けた。GPT‑5.6 からは、キャッシュ書き込みは未キャッシュ入力価格の 1.25 倍で課金、キャッシュ読み出しは引き続き 90% の割引を受けられる。
もう一つ:7 月に Cerebras へ
OpenAI はさらに 7 月に GPT‑5.6 Sol を Cerebras 上へ展開する計画で、速度は毎秒 750 token に達しうる。これは将来の計画で、初期は一部の顧客にのみ開放し、生産能力の拡大に伴って開放を広げる。
「私たちは、こうした政府承認の手続きが長期的な既定になるべきだとは考えていない。それは最良のツールを、本当に必要とするユーザー、開発者、企業、サイバー防御者、そして世界中のパートナーの手に届かなくしてしまう。」OpenAI 公式ブログ『Previewing GPT‑5.6 Sol』
本記事は OpenAI 公式ブログ『Previewing GPT‑5.6 Sol』(2026 年 6 月 26 日)の解読である。文中のすべての能力記述、ベンチマーク成績(Terminal‑Bench 2.1、GeneBench v1、ExploitBench、ExploitGym)、安全スタックの強度、および「Cyber Critical の一線を越えていない」という結論は、いずれも OpenAI 自身の評価・自己評価の基準であり、独立した第三者の検証は経ていない。完全な評価スイートは、モデルが広く開放される際に改めて公表すると OpenAI は述べている。Cerebras の稼働開始は 7 月の計画であり、すでに起きた事実ではない。出典:OpenAI 公式ブログ。