Anthropic が Claude Sonnet 5 を発表:4割安く、一部タスクで Opus 4.8 に並ぶ
- Anthropic が Claude Sonnet 5 を発表。公式は現時点で自律的にタスクを遂行する(agentic)能力が最も高い Sonnet 系列モデルだとしている。
- 期間限定価格は100万 token あたり入力 $2 / 出力 $10(2026年8月31日まで)、その後は $3 / $15 に上がる。比較として、フラッグシップの Opus 4.8 は $5 / $25。
- 本日より Free、Pro、Max、Team、Enterprise の全プランと Claude Code、Claude 開発プラットフォームで提供開始。Free と Pro プランのデフォルトモデルとなる。
- 安全性評価では全体的な不適切行動率が前世代の Sonnet 4.6 より低い一方、ソフトウェアの脆弱性エクスプロイト開発などサイバー攻撃能力は Opus 4.8 より明らかに弱く、公式はデフォルトでリアルタイムのサイバーセキュリティ防護を有効にしている。
- 新しいトークナイザーに切り替えたため、同じ文章でもより多くの token に分割される可能性があり(約1.0〜1.35倍)、期間限定価格はこの要因を織り込み済み。今回のアップグレードは換算するとおおむねコスト中立になる。
今回のリリースで、安いほうが高いほうに追いついた
Anthropic は先日 Claude Sonnet 5 を発表し、これまでで最も能力が高く、自律的なタスク遂行(agentic、モデルが自らタスクを分解し、ブラウザやターミナルなどのツールを呼び出し、複数のステップを連続でこなし、その過程で自分が正しくできているかを能動的に確認すること)が最も得意な Sonnet 系列モデルだとしている。
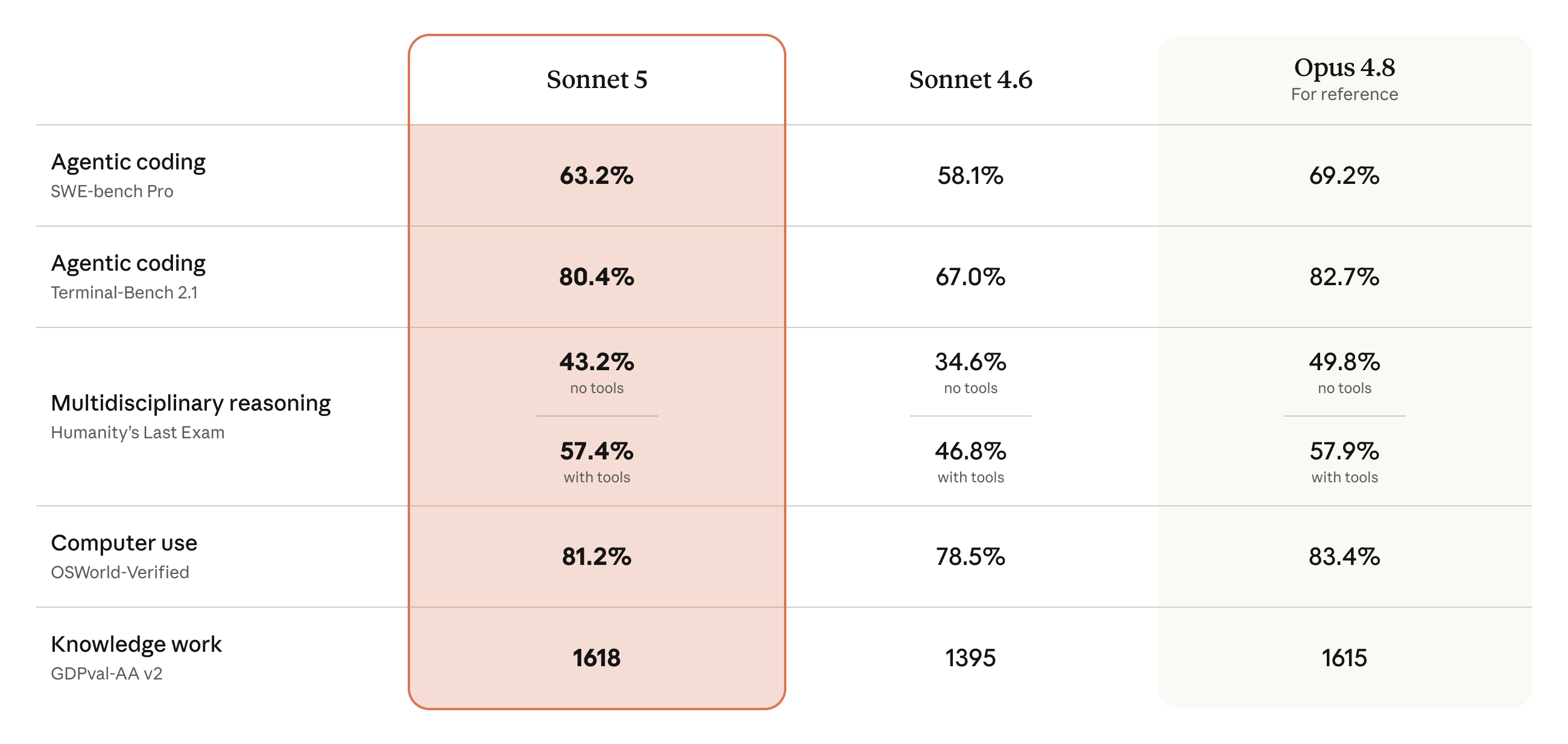
注目すべき理由:100万出力 token あたりで見ると、Sonnet 5 の標準価格は $15、Opus 4.8 は $25 で、ちょうど6割。期間限定価格なら入力/出力 $2/$10 とさらに安い。そして BrowseComp(エージェント検索)と OSWorld-Verified(コンピュータ操作)の2つの評価では、演算リソース段を上げると Sonnet 5 は Opus 4.8 と互角になる。「より安い」と「フラッグシップに手が届く」──この2つが初めて同じ Sonnet に同居した。
仕事をこなすモデルは、いつも Sonnet 系列が先に実現してきた
多くの開発者にとって、「AI が自分で仕事をこなす」という流れは Sonnet から始まった。Claude Sonnet 3.5、3.6、3.7 は、コード記述とツール呼び出しで最初に目を見張らせたモデル群だ。だがここ最近、能力の伸びが最も目立ったのはより高価な Opus 系列で、Sonnet のラインは差を広げられてしまった。Sonnet 5 がやろうとしているのは、この差を取り戻すことだ。
最初に披露
差を開けられた
取り戻す
前世代の Sonnet 4.6 と比べ、公式は Sonnet 5 が推論、ツール呼び出し、コード記述、ナレッジワークといった agentic 性能に関わる重要な部分でいずれも明らかに進歩したとしている。
同じ1ドルで、いまどれだけの知能が買えるか
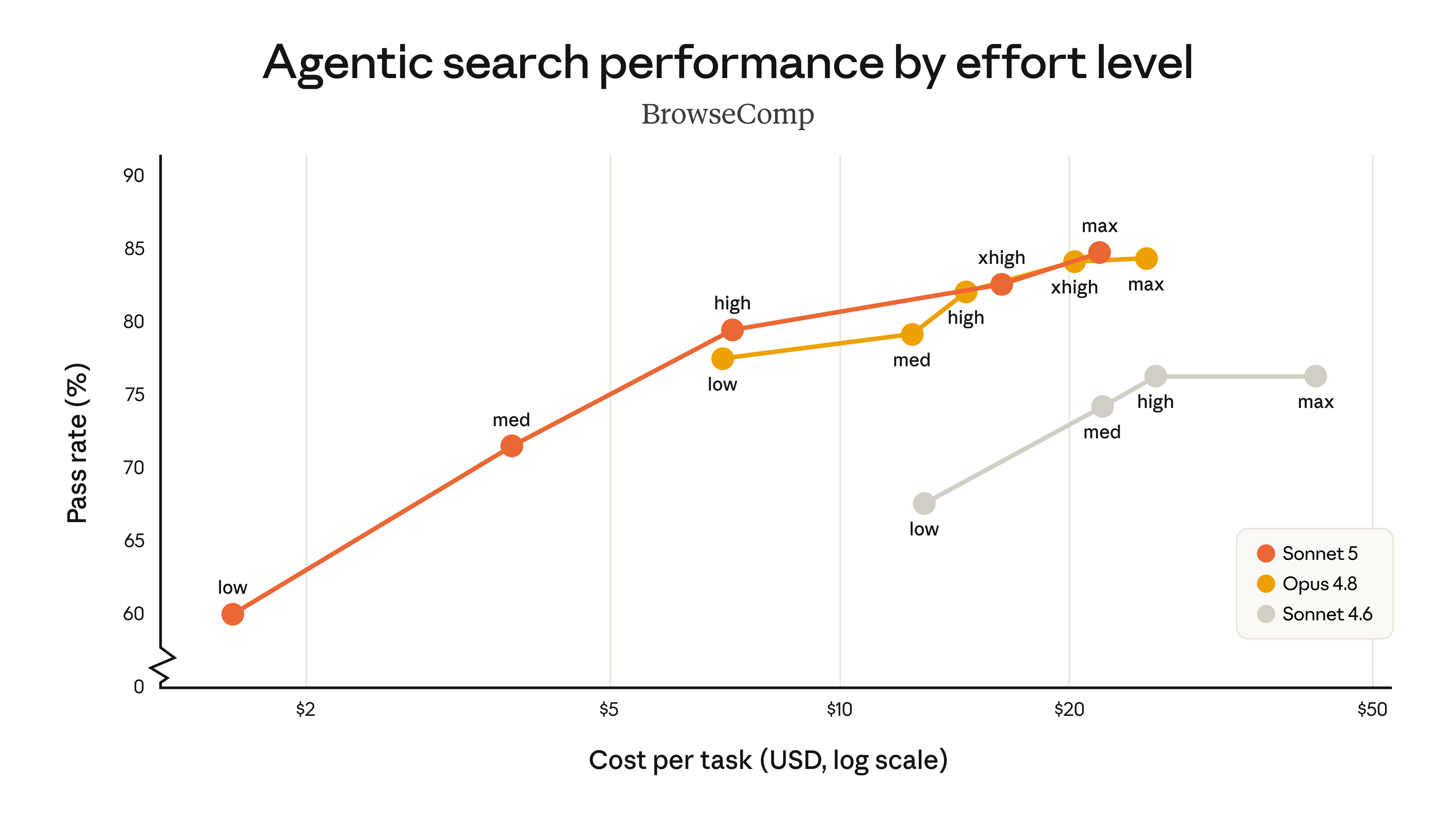
公式は2枚のコスト・性能曲線を公開した。比較しているのは Sonnet 5、Sonnet 4.6、Opus 4.8 の異なる演算リソース段での成績で、横軸はタスクごとの費用(コスト)、縦軸は評価スコアだ。結論は:Sonnet 5(オレンジ線)は Sonnet 4.6(グレー線)を全面的に上回り、カバーするコスト帯は Opus 4.8(黄色線)よりずっと広く、中程度の段ではコスパの向上が顕著で、最高段では一部タスクで Opus 4.8 に並ぶ。
評価基準の2点の更新(6月30日訂正)
公式は6月30日にこのリリースを改訂した:もともと BrowseComp のあの図はより単純な手法を使っており、Sonnet 5 の成績を過小評価していた。現在はシステムカードの標準手法(1000万 token の予算 + 圧縮 + プログラムによるツール呼び出し)で描き直している。また、2つの旧スコアが採点方式の更新により修正された:Humanity's Last Exam の Sonnet 4.6 スコアは 34.6%(ツールなし)/ 46.8%(ツールあり)に更新。OSWorld-Verified の Sonnet 4.6 スコアは 78.5% に更新。これらが Sonnet 4.6 リリースブログの数字と異なるのは、評価方式が変わったためだ。
演算を増やせば一歩多く考える:1つのモデルが安さとトップ性能をどう両立するか
Sonnet 5 がこれほど広い価格帯をまたげるのは、effort(演算リソース/推論の強度段)という仕組みのおかげだ:同じモデルで、それが「どれだけ力を入れて考えるか」を自分で選べる。段が低いほど安くて速いが、十分に丁寧でないかもしれない。段が高いほど、モデルはより多くの演算を使って繰り返し推論し自己チェックし、答えはより正確になるが、その分高価で遅くなる。
同じ店で同じ料理を頼むようなものだ。いつも通り出してもらうこともできれば、追加料金を払ってより手間をかけてもらい、出す前に自分で一口味見して問題ないか確かめてから出してもらうこともできる。料理は同じ料理で、変わるのはどれだけ丁寧にやり、何度チェックしたかだ。effort 段が調整するのは、まさにこの「丁寧さの度合い」だ。
丁寧さ不足かも
効率向上が顕著
正確で安定
一部で Opus 4.8 と互角
かつては、より強い能力が欲しければ、より大きく高価なモデルに替える必要があった。いまはモデルを替えず、つまみを1つ回すだけだ:低い段は安くて速い入門版、高い段(xhigh)はより多くの演算を使って繰り返し推論し自己チェックし、一部タスクではフラッグシップの Opus 4.8 に並ぶ。1つの Sonnet 5 が、入門からフラッグシップ近くまでの価格帯を一気に埋め尽くし、Sonnet 4.6 のように早々に頭打ちにならない。コストと性能のバランス点は、プロジェクトに応じて自分で決められる。
初期ユーザーの声:催促しなくても、自分で答え合わせをする
公式によれば、早期アクセスパートナーのフィードバックはかなり一致している:Sonnet 5 は前の数世代より明らかに「自分で仕事をこなす」。テスターが挙げた客観的な点は以下の通り。
- 複雑なタスクでも最後までやり遂げられる。前の数世代の Sonnet はしばしば途中で止まってしまっていた。
- 誰も明示的に求めていなくても、自分の出力が正しいかを能動的にチェックする。
- こうした自律的な作業をこなす上で、価格もかなり魅力的だ。
より安全になった、ただしサイバー攻撃だけは意図的に抑え込まれている
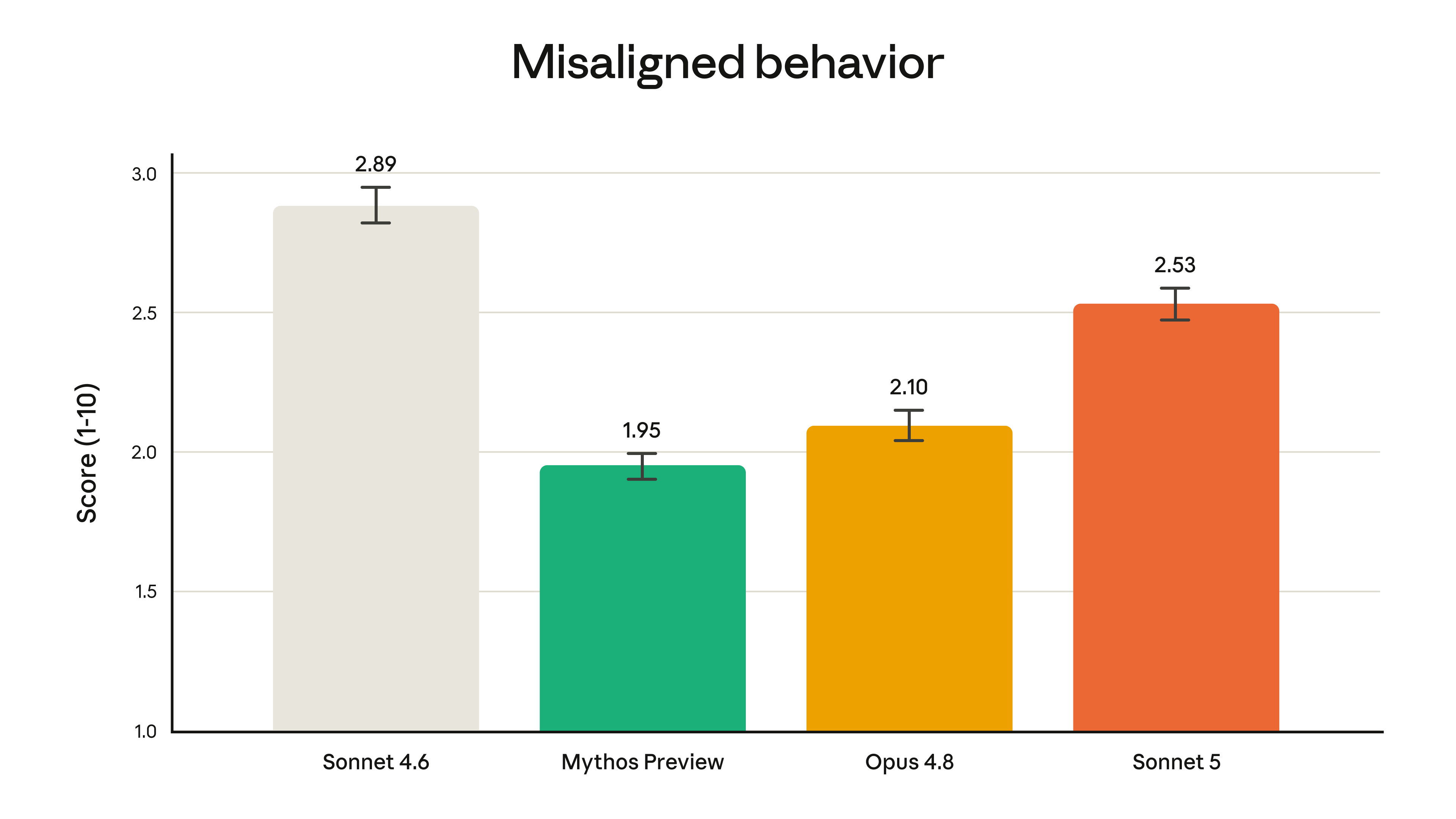
デプロイ前の安全性評価では、Sonnet 5 は全体として Sonnet 4.6 より安全だ:悪意あるリクエストの拒否がより得意で、プロンプトインジェクション(prompt injection、攻撃者が悪意ある指示を、モデルが処理するウェブページやメールにこっそり忍ばせ、ユーザーではなく攻撃者の指示を実行させようとする手口)への耐性も高く、幻覚やユーザーへの迎合の傾向も低い。複数の不適切行動をカバーする自動行動監査でも、全体スコアはより低い(つまりより安全)が、それでもより強力な Opus 4.8 や Claude Mythos Preview よりは高い。
サイバーセキュリティは単独で抑え込まれた項目だ。公式によれば、Sonnet 5 をサイバーセキュリティのタスク向けに特別に訓練してはいない:一般的で無害なサイバー関連のタスクはこなせるが、ソフトウェアの脆弱性エクスプロイト開発のような危害を及ぼしうる評価では、成績が Opus 4.8 や Mythos 5 より明らかに弱い。
具体的なテスト:Firefox を突破できるか
「サイバー攻撃能力が弱い」は抽象的に聞こえるが、公式は具体的な数字を出した:各モデルに Firefox ブラウザの脆弱性を突くエクスプロイト(exploit)を開発させるというものだ。この評価は Anthropic と Mozilla が共同開発したもので、対象となる脆弱性はすべて Firefox 148 で修正済みだ。
2つの Sonnet はどちらも完全に使えるエクスプロイトを作れなかった(いずれも 0.0%)。Sonnet 5 が Sonnet 4.6 よりわずかに高いのは部分成功率だけで、公式はこれが専門的な訓練ではなく、全体的な知能向上の副産物によるものだと判断している。対照として、Opus 4.8 と Mythos 5 のサイバー攻撃能力はどちらもこの2つの Sonnet よりはるかに強い。
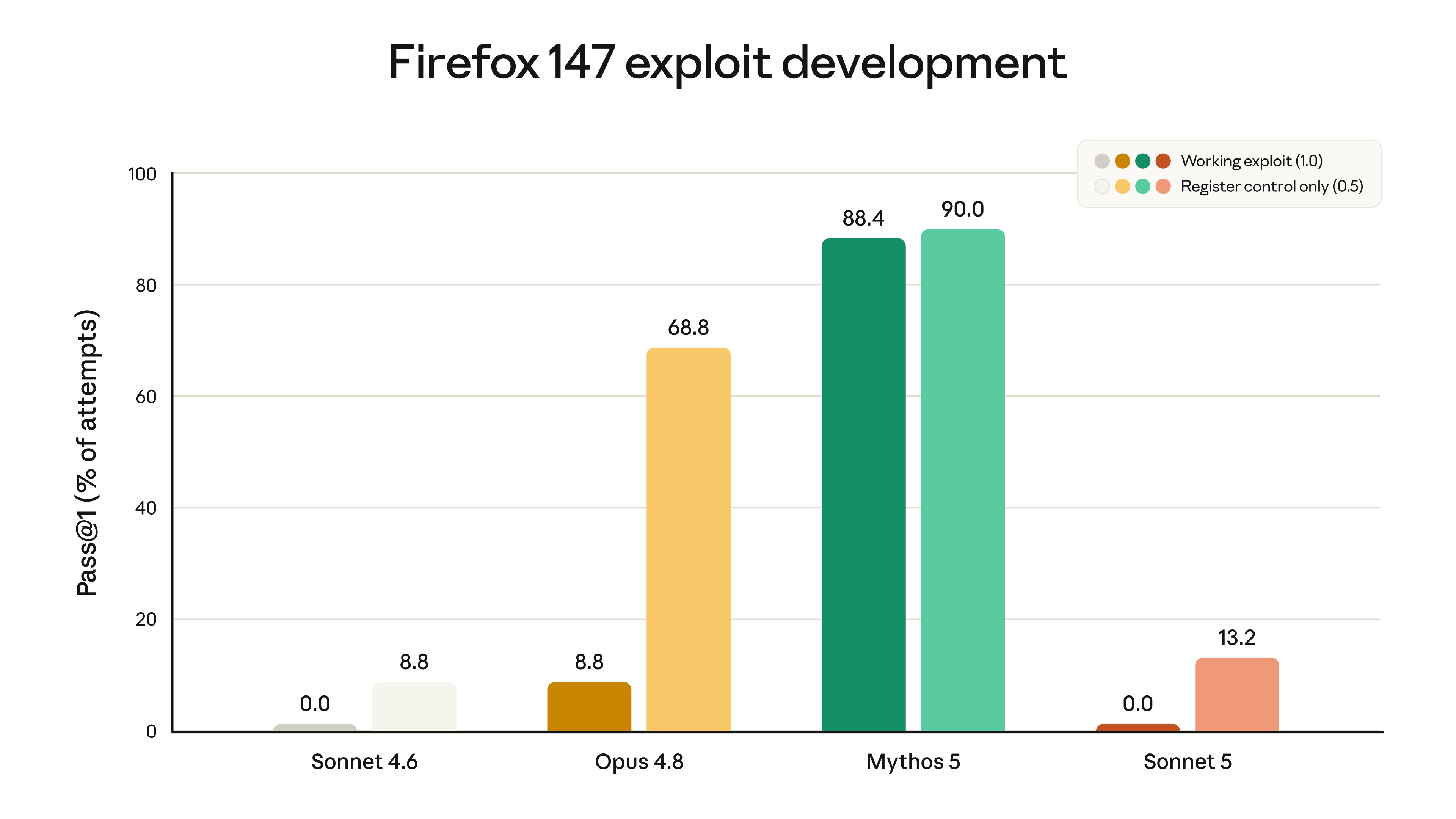
Sonnet 5 はこの種のタスクで前世代よりわずかに強いため、公式はデフォルトでリアルタイムのサイバーセキュリティ防護を有効にした。危険なサイバー用途をリアルタイムで検知・遮断でき、この防護は Claude Opus 4.7、4.8 と同等だ。公式は Sonnet 5 の全体的なサイバーセキュリティリスクは低いと判断しており、そのためこの防護は Fable 5 のもの(はるかに広い範囲のサイバーセキュリティタスクを遮断する)より緩い。
値下げに見えて、実はものさしを取り替えただけ
Sonnet 5 は新しいトークナイザー(tokenizer)に替えた。モデルは文章を処理する前に、まず文章を1つ1つの token に切り分けて課金・計算する。新しいトークナイザーに替えた後、同じ文章がより多くの token に切られる可能性があり、おおよそ1.0〜1.35倍(内容の種類による)だ。つまり、token あたりの価格だけ見れば下がったが、同じ文章が消費する token は増えたため、実際の単位コストはそれほど下がっていない。
100万 token あたり、Sonnet 4.6 の価格から期間限定の $2/$10 に下がった。
期間限定価格はトークナイザーの変化を相殺するように設定されており、Sonnet 4.6 から Sonnet 5 への移行がおおむねコスト中立になるようにしている。
公式は明言している:期間限定価格の設定は、今回のアップグレードが換算するとコスト中立に近くなるようにするためだ。だからこそ「値下げ」にはカギ括弧を付けるべきで、勘定は token 数まで含めて計算しなければならない。今回のトークナイザー調整は、Claude Opus 4.7 のときと同じ類いのやり方だ。
今すぐ使える:提供範囲、価格表、選び方
Sonnet 5 は本日より全プランで提供開始:Free と Pro プランのデフォルトモデルであり、Max、Team、Enterprise ユーザーも利用できる。同時に Claude Code と Claude 開発プラットフォームでも提供開始し、開発者は Claude API 経由で claude-sonnet-5 を呼び出せる。
| モデル | 入力 / 出力(100万 token あたり) |
|---|---|
| Sonnet 5(期間限定、2026-08-31 まで) | $2 / $10 |
| Sonnet 5(以降の標準価格) | $3 / $15 |
| Opus 4.8(比較) | $5 / $25 |
$2 / $10
期間限定
$3 / $15
標準価格
より高い演算リソース段がもたらす token 消費の増加に対応するため、公式はすでに Chat、Cowork、Claude Code、Claude 開発プラットフォームの全体で呼び出しレート上限を引き上げている。プロジェクトに応じて適切な段を自分で選べる。
選び方
| あなたは誰か | おすすめ |
|---|---|
| 開発者 | 予算を変えずにより強い agentic なコーディングとツール呼び出しが欲しい:高い段を使う。節約したい:effort を下げ、より低コストでフラッグシップに近い効果を得て、コストと性能のバランスを自分で取る。 |
| 企業 / チーム | Chat、Cowork、Claude Code、開発プラットフォームのレート上限が引き上げられ、高い段でのより多い token 消費に対応している。 |
| セキュリティ関連の業務 | デフォルトのサイバーセキュリティ防護は Opus 4.7/4.8 と同等。制限のより少ないサイバーセキュリティ研究や攻防系の業務が必要なら、公式は Sonnet 5 ではなく Opus 4.8 の利用を勧めている。 |
Sonnet 5 は差を縮めた:その成績は Opus 4.8 に近いが、価格はより低い。 Anthropic『Introducing Claude Sonnet 5』