Claude Code 公式がループ設計を徹底解説:4段階で無人運用へ
- Anthropic の Claude Code チームがブログを公開し、「ループ(loop)の設計」を4つの標準パターンに整理した。ターン制、ゴール制(
/goal)、時間制(/loopと/schedule)、能動型の順に、自律度が低いものから高いものへと段階的に進む。 - ループの公式な定義は、agent が一巡ずつの作業を繰り返し、ある停止条件を満たして初めて終える、というもの。4つのタイプは「誰が起動するか、どう停止を判断するか、どの機能で実現するか、どんなタスクに向くか」の4つの軸で区別される。
/goalの核心は、独立した評価モデルを導入して基準達成を判定する点にある。Claude 自身が「もう十分だから終わり」と早めに言うことはできず、試行回数の上限も設定できる。- 能動型ループは、
/schedule(定時起動)、/goal(停止条件)、skills(検証基準)、dynamic workflows(複数 agent の並列編成)、auto mode(人手の確認不要)の5つの機能を積み重ね、bug 報告のトリアージ、issue の分類、依存関係のアップグレードといった継続的な作業を無人で処理できる。 - 実践アドバイスは2つ。確定的な作業はスクリプトに任せる方が、毎回 Claude に推論し直させるより token を節約できる。大規模な dynamic workflows(数百もの agent を立ち上げうる)は、本番投入前にまず小さな範囲で試し打ちする。
90 点「数百の agent」といった数字はいずれも原文からの引用で、公式の見解である。AI が作業を代行する、では「終わった」と決めるのは誰か?
Claude Code チームの Delba de Oliveira と Michael Segner は、2026年6月30日に Anthropic 公式ブログへ寄稿し、Claude Code のための「ループ(loop)」設計をどう行うかを体系的に整理した。すなわち、agent に作業を繰り返させ、停止条件を満たすまで走らせる、というものだ。
筆者は冒頭である現象を指摘する。X では「コーディング agent に一言ずつ指示を出すのはやめて、ループを設計しよう」という話があちこちで交わされている。ところが「ループとは結局何なのか」を実際に調べると、互いに矛盾する答えが山ほど出てくる。この記事がやろうとしているのは、まさにそこをはっきりさせることだ。
以下では、4段階のループを簡単なものから複雑なものへと順に分解していく。どの段階も、あなたの手元にある何らかの作業に対応するはずだ。
まず押さえる:「ループ」とは結局何か
公式の定義はたった一文だ。ループとは、agent が一巡ずつの作業を繰り返し、ある停止条件を満たすまで走ること。肝心な違いは、「いつ完了とするか」があらかじめ決められ、システムに判断が委ねられている点にある。あなた自身が一巡ごとに見張って急かすわけではない。
筆者はループを4つの軸で分類する。この4軸こそ、後述する各ループ共通のものさしだ。誰がそれを起動するか、どう停止を判断するか、Claude Code のどの機能で実現するか、どんなタスクに最も向くか。まず座標系を立て、そこへ4種類のループを当てはめていく。
一言の指示 → 手動でリアルタイム → 時間が来たら(一定間隔)→ イベントまたはスケジュール、全編で人は不在
Claude が自分で判断 → 基準達成か再試行の上限 → あなたが中止するか作業完了 → 各タスクは基準達成で終了、パイプライン全体は手動で停止
デフォルトの対話 → /goal → /loop、/schedule → 以上すべて + dynamic workflows + auto mode
短いタスク → 検証可能な終了基準を持つタスク → 周期的、または外部システムと連携 → 繰り返し現れ定義が明確なワークフロー
筆者はこうも念を押す。すべてのタスクに複雑なループが要るわけではない。いちばんシンプルなやり方から始め、これらのパターンは必要に応じて選べばいい。
あなたが一言、agent が一巡
これはあなたが毎日使っているデフォルトのモードそのものだ。あなたが送る一つひとつの指示が、毎巡をあなた自身の手で導くループを立ち上げる。Claude はコンテキストを集め、手を動かし、自分の作業を点検し、必要なら繰り返し、そして返答する。公式にはこれを「agentic loop」と呼ぶ。
原文の例を挙げよう。あなたが Claude に「いいね」ボタンを作らせる。Claude はコードを読み、ファイルを直し、テストを走らせ、そして「自分では使えると思う」ものを返してくる。次はあなたが手動で受け入れ検査し、さらに次の指示を書く。起動するのは一言の指示、止めるかどうかの判断権は Claude 自身の手にある。決まった手順にも属さず、スケジュールにも従わない短いタスクに向く。
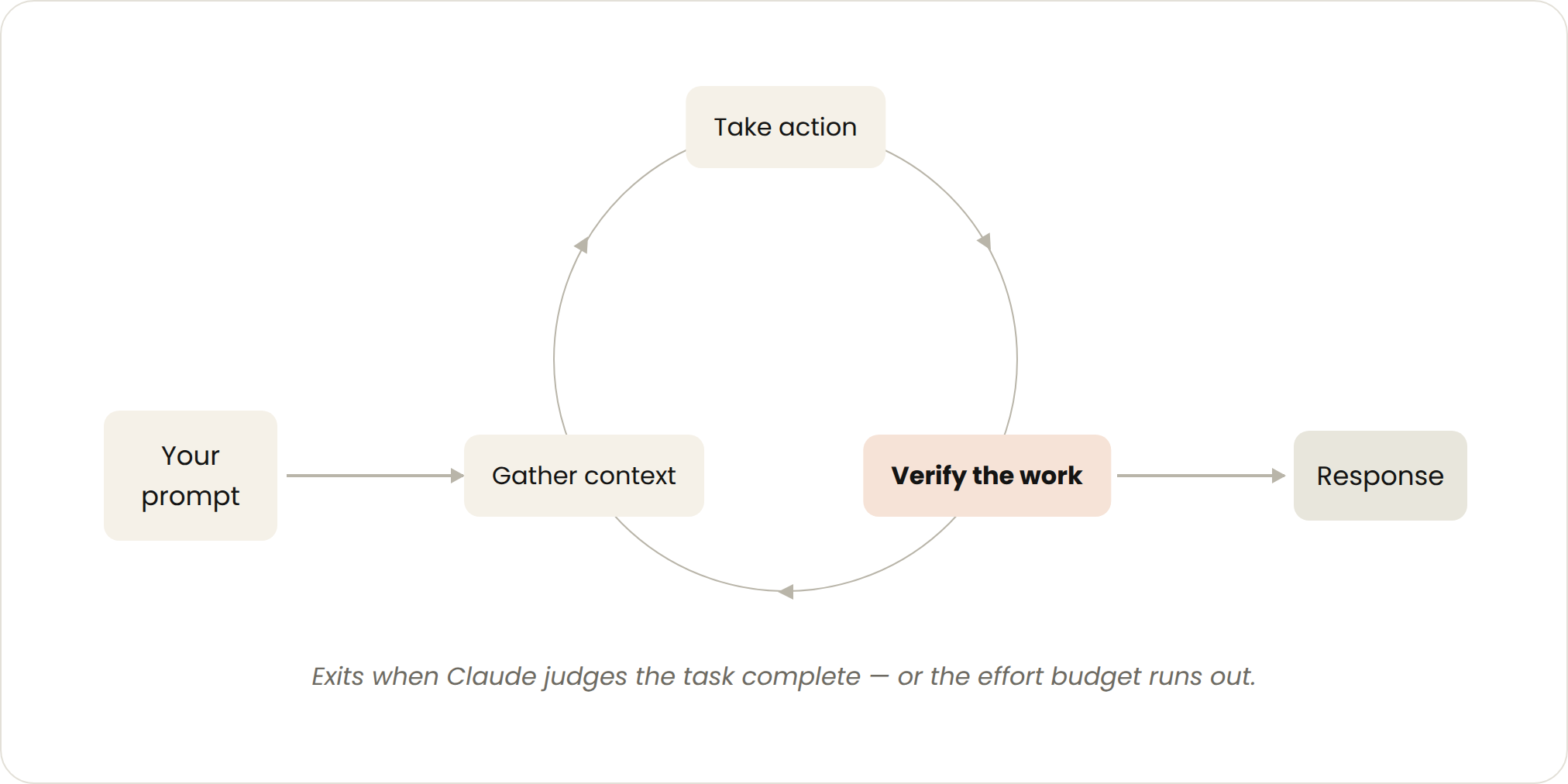
自己点検をより徹底させるには
「検証」というステップを強化するといい。ふだん手動でやっている受け入れ検査の手順を SKILL.md に書き起こし、Claude がエンドツーエンドでより多くを自分で確認できるようにするのだ。肝心なのは、見る・測る・手を動かすためのツールやコネクタを与えること。検査が定量的であるほど、Claude は自己検証しやすくなり、必要なターン数も減る。
原文では verify-frontend-change というスキルが示されている。フロントエンドのどんな変更も、「編集に成功した」というだけで完了と報告してはならず、人間のレビュアーのように一連のプロセスをすべて踏まなければならない。
- dev server を起動し、変更したページをブラウザで開く
- 変更と直接やり取りする。ボタンを押し、状態の変化を確認し、前後をスクリーンショットで比較する
- ブラウザのコンソールを見る。新しいエラーや警告が一切あってはならない
- Chrome DevTools MCP で性能 trace を走らせ、Core Web Vitals を精査する
いずれかのステップで失敗したら、直したうえで第1ステップからやり直す。決して中途半端なものは渡さない。
元の SKILL.md サンプルコードを見る
--- name: verify-frontend-change description: Verify any UI change end-to-end before declaring it done. --- # Verifying frontend changes Never report a UI change as complete based on a successful edit alone. Verify it the way a human reviewer would: 1. Start the dev server and open the edited page in the browser. 2. Interact with the change directly. For a new control (button, input, toggle): click it, confirm the expected state change, and screenshot before/after. 3. Check the browser console: zero new errors or warnings. 4. Use the Chrome Devtools MCP, run a performance trace and audit Core Web Vitals. If any step fails, fix the issue and rerun from step 1 — do not hand back partially verified work.
先に「合格ライン」を決めてこそ、正しく止まれる
一巡では足りないこともある。とくに複雑なタスクではそうだ。agent は繰り返し反復できるときほどよく働く。/goal を使って「どうなれば完了か」を明確に定義し、Claude が反復する時間を延ばせる。
成功基準を定義すれば、Claude は「もう十分か」を自分で判断して早めに切り上げる必要がなくなる。Claude が止まろうとするたびに、独立した評価モデル(evaluator)があなたの条件を手に一通り照合する。基準に達していなければ突き返して作業を続けさせ、目標を達成するか、あなたが設定した試行回数の上限に至って初めて本当に止まる。
言い換えれば、判定権は Claude の手から取り上げられ、基準の照合を専門に行う評価モデルへ渡される。だからこそ「確定的な基準」がとりわけ効く。たとえば合格したテストの数や、あるスコアのしきい値の突破なら、評価モデルは曖昧さなくはっきりチェックを入れられる。
宿題を提出する前に品質チェックの関門を一つ通すようなものだ。検査するのは自分自身ではなく、別の人(評価モデル)が基準表を手に一項目ずつチェックを入れる。基準に達しなければ差し戻してやり直させ、手戻りは最大でも数回まで、というわけだ。
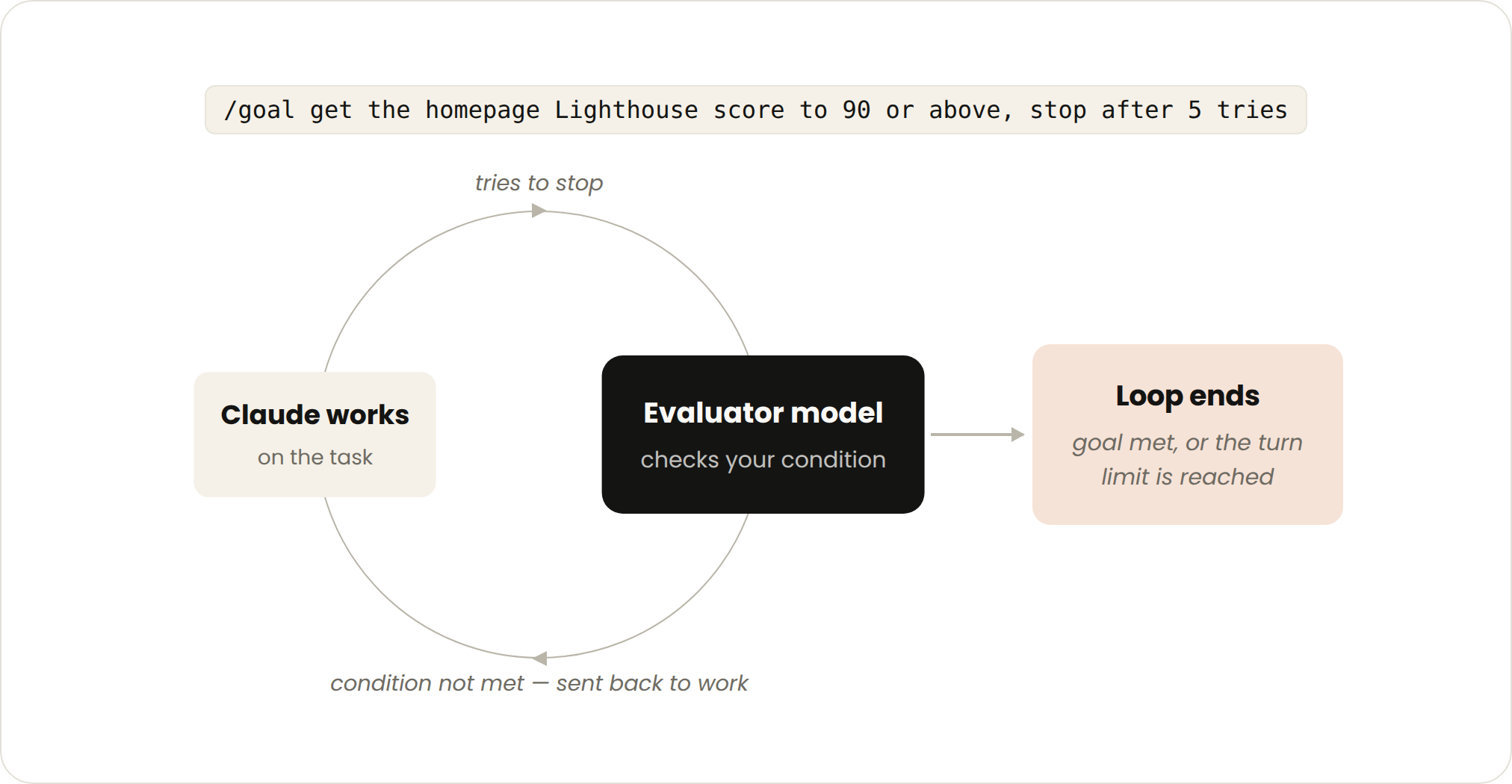
具体的な例を一つ挙げよう。
/goal get the homepage Lighthouse score to 90 or above, stop after 5 tries.
ゴール制は、検証可能な終了基準を持つタスクに向く。あなたが渡すのは「停止条件」で、使う機能は /goal だ。コストを抑える手立ては、完了基準と再試行の上限をどちらも具体的に定めること。たとえば「5回試して止める」といった具合だ。
時間が来たら自分で様子を見に行く
周期的な作業もある。タスクは変わらず、変わるのは入力だけ、というものだ。たとえば毎朝 Slack のメッセージを一通りまとめる、といった具合。また外部システムに依存する作業もあり、いちばんシンプルな連携のやり方は、一定間隔で確認しに行き、変化に応じて反応することだ。たとえばある PR は、レビューコメントが付くこともあれば、CI が落ちることもある。
この種の作業は /loop で起動する。一定間隔で一言の指示を再実行してくれる。止まる条件は、あなたが中止するか、作業が終わる(PR がマージされた、キューが空になった)ことだ。例:
/loop 5m check my PR, address review comments, and fix failing CI
自分のパソコン上で、一定間隔で同じ指示を再実行する。
パソコンを閉じれば止まる。あなたがその場にいて、一時的に見張る作業に向く。
/schedule で routine を作り、この「定時での再実行」をクラウド上に常駐させる。
パソコンを閉じても走り続ける。長期にわたり動かし続け、あなたの在不在に左右されない作業に向く。
/loop 5m は5分ごとに PR を確認し、レビューコメントに対応し、失敗した CI を修正する5つの機能を組み合わせ、人手なしで自ら走る
これまでのいくつかのプリミティブに、auto mode(自動モード。各ステップで止まって続行の可否を尋ねない)と dynamic workflows(動的ワークフロー、研究プレビュー版)を加えると、長期的な作業を処理する一本のループを組み立てられる。起動するのはイベントかスケジュールで、全編を通じて人がリアルタイムに立ち会うことはない。
能動型ループの停止ロジックは2層に分かれる。個々の具体的なタスクは自分の目標に達すれば終了し、routine 全体はあなたが手動で止めるまでずっと走り続ける。繰り返し現れ、定義の明確なワークフローに最も向く。bug 報告、issue のトリアージ、移行、依存関係のアップグレードなどだ。
フィードバックの処理を例にとると、公式が示す組み方は、4つの機能を一層ずつ積み重ね、その上に auto mode をかぶせる、というものだ:
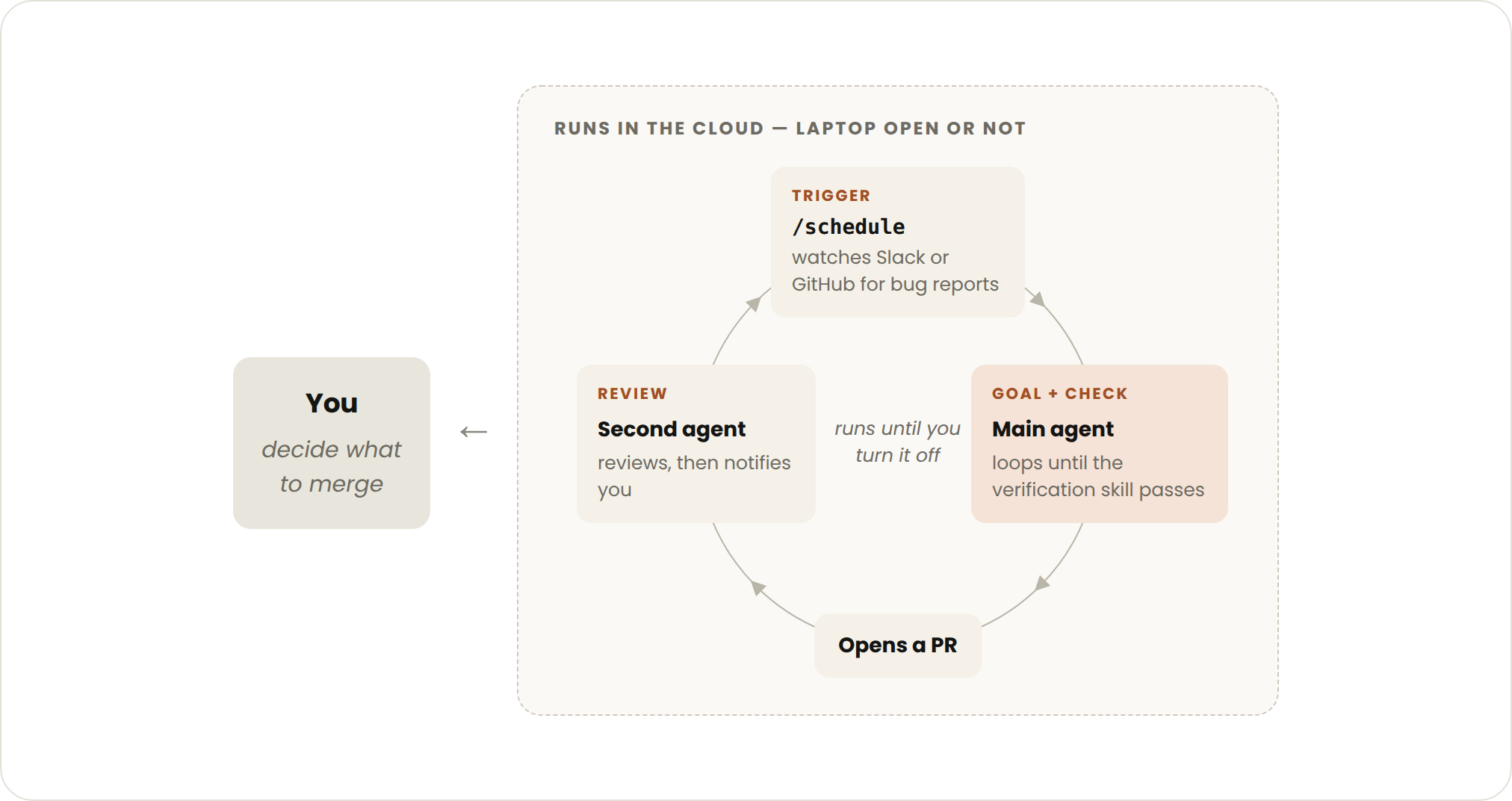
組み合わせると、一本の完全な指示はこうなる:
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.
かみ砕くとこうだ。1時間ごとに #project-feedback チャンネルへ bug 報告を確認しに行く。この巡で見つけた一つひとつを、トリアージし、対応し、返信し終えるまで止めない。ある bug を直すときは、一つの workflow を使い、3つの独立したブランチ(worktree)で3通りの解法を並列に試し、さらに裁判役の agent に敵対的に互いのあらを探させる。ここでの dynamic workflows は、一度に数百規模の子 agent を立ち上げ、手分けして作業し、互いに連携させることができる。
コストを抑える手立て:routine は、より小さく速いモデルに走らせ、判断が要る肝心なところでだけ最も強力なモデルを使う。
ループが自分で暴走しないように
ループの出力品質は、それを取り巻くシステム次第だ。システムを設計するにあたり、公式は4つを挙げている:
- コードベース自体を清潔に保つ
Claude はあなたのコードベースに既にあるパターンや規約に倣う。土台が清潔であってこそ、それに倣って出てくるものも清潔になる。
- Claude に自己点検の手段を与える
「どうなれば良いか」を skills であなたとチームの基準として固定化し、エンドツーエンドで自らを点検できるようにする。
- ドキュメントを手の届くところに
フレームワークやライブラリの公式ドキュメントには最新のベストプラクティスが載っている。古い記憶で当て推量させてはいけない。
- 2つ目の agent でコードレビューする
コンテキストがまっさらなレビュアーは偏りが少なく、メインの agent の推論に影響されない。組み込みの
/code-reviewを使うか、GitHub の Code Review をつなげるとよい。
ある一度の結果が基準に達しなかったとき、その一度の問題を直すだけで止まってはいけない。それをルールとして固定化し、システム全体を改善し、以後の毎巡の反復が恩恵を受けるようにする。誤りが出たときに直すべきはシステムのルールであり、その一度の結果ではない。
ループにこっそり token を焼き尽くされないように
token を抑えるには、ループに明確な境界が要る。原文は実行可能な6項目のリストを示している:
/usage は skills、subagents、MCP ごとに直近の使用量を分解する。/goal は引数なしで使ったターン数と token を確認できる。/workflows は各 agent の使用量を見て、いつでも止められる。4種類のループの選び方を一表で
具体的なタスクに向き合うとき、はっきりさせるべきは3つ。何を委ねるか、いつ使うか、どの機能を使うか。原文のこの総括表は4段階のループを一行ずつ対照でき、各カードを開くと具体例が見られる。
| ループ | 委ねるもの | 使う場面 | 使う機能 |
|---|---|---|---|
| ターン制 | 「検査」 | 探索中や意思決定中 | カスタム検証 skills |
| ゴール制 | 「停止条件」 | 何を完了とするか分かっている | /goal |
| 時間制 | 「起動」 | 作業がプロジェクトの外で時間表に沿って発生する | /loop、/schedule |
| 能動型 | 「プロンプト」 | 作業が繰り返し現れ定義が明確 | 以上すべて + dynamic workflows |
ターン制 · 例を見る
Claude に「いいね」ボタンを作らせる。コードを読み、ファイルを直し、テストを走らせ、自分では使えると思う版を返す。あなたが手動で受け入れ検査した後、次の指示を書く。
ゴール制 · 例を見る
/goal get the homepage Lighthouse score to 90 or above, stop after 5 tries.
時間制 · 例を見る
/loop 5m check my PR, address review comments, and fix failing CI
能動型 · 例を見る
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.
すでにやっている作業を見渡し、あなたがボトルネックになっているタスクを一つ選び、どの部分を委ねられるかを自問する:
- この作業の受け入れ検査を書けるか?
- この作業の目標は十分に明確か?
- この作業は時間表に沿って発生するか?
考えがまとまったらループを走らせ、どこで詰まり、どこで一線を越えるかを観察し、そして思い切って反復改善していこう。
私たちはループをこう定義する。agent が一巡ずつの作業を繰り返し、ある停止条件を満たすまで走ること。 Claude Code チーム、Getting started with loops、2026-06-30