VerifiedSourceOpenAI 官方博客 ↗06-27 · 7 min read⚑ Vendor content · take with context
🎧 Listen to the podcast0:00 / --:--
↓ Article body below · each piece has its own look
Product Launch · Xiaohu Explains
GPT‑5.6 Is Out — Except It Kind of Isn't
Three tiers at once: flagship Sol, balanced Terra, budget Luna — and cybersecurity is this generation's main thrust. But it ships first as a limited release to trusted partners, with the list already filed with the US government, and only goes broadly available a few weeks later.
速览
OpenAI opened a limited preview of the GPT‑5.6 family on June 26, 2026, launching three models at once: flagship Sol, balanced Terra, and budget Luna.
A new naming scheme kicks in: the number marks the generation, while Sol / Terra / Luna mark the capability tier. Terra performs close to the previous GPT‑5.5 at half the price.
The capability gains center on three areas — coding, biology, and cybersecurity — setting records on benchmarks like Terminal‑Bench 2.1. But every number is OpenAI's own self-eval; the full evaluations come out when access widens.
It ships with what OpenAI calls its strongest safety stack yet: multiple layers working together, plus over 700,000 A100-equivalent GPU hours spent on automated red-teaming to hunt for universal jailbreaks.
At the US government's request, it first goes to a small set of trusted partners (the list has been filed), with wider access weeks later. Pricing per million tokens: Sol $5 / $30, Terra $2.5 / $15, Luna $1 / $6.
⚑Heads-up: this piece is based on OpenAI's official launch blog — it's a vendor announcement. The capability leaps, benchmark scores, and safety-stack strength are all OpenAI's own claims, not verified by independent third parties; OpenAI itself admits the preview's safeguards may wrongly block legitimate requests. Below we explain what it says and how it works — we don't grade it for you.
1Launch Overview
GPT‑5.6 Is Here — Three at Once
OpenAI opened a limited preview of the GPT‑5.6 family on June 26, 2026, launching three models in one go: flagship Sol, balanced Terra, and budget Luna.
This isn't an ordinary version bump. OpenAI bundled a "model capability jump" with a "government preview process": before launch it showed the capabilities and rollout plan to the US government, and at the government's request opened access only to a small set of trusted partners first — going broadly available only weeks later.
⚡
Why it's worth a look: this is the first time OpenAI has tied a model capability leap to a government preview process. Cybersecurity is the headline improvement this generation, the partner list has been filed with the government, and over 700,000 A100-equivalent GPU hours went into automated red-teaming. At the same time, OpenAI says plainly it does not want this kind of government-gated access to become a lasting default.
2Picking a Model
One Family, Three Models — How to Choose
Three tiers within the same generation, differing on "how strong, how fast, how pricey." Tap any tier below to see what it's good for.
↓ tap a tier to see its use cases
Sol: what OpenAI calls its strongest model yet, with two new tiers — max (gives the model the most time to think slowly) and ultra (spins up a batch of sub-agents to work in parallel). For the hardest, most tangled long-horizon tasks in coding, research, cybersecurity, and the like.
Terra: the everyday workhorse. OpenAI says it performs close to the previous GPT‑5.5 at half the price — fit for most "needs to be strong yet cheap" daily work.
Luna: fastest and cheapest. OpenAI says it keeps solid capability at the lowest price point — for high-volume work that's sensitive to latency and cost.
How to Read the New Naming
Before, a single number carried everything — capability tier, old vs. new, all mashed into that one number. This time it splits into two dimensions: the number handles "generation," the name handles "capability tier," and each side upgrades on its own schedule.
Old naming
One number settles everything: GPT‑5, GPT‑5.5… bigger means newer, but "wanting a cheaper, faster version" meant waiting for the next minor number.
New naming
The number (5.6) only marks the generation; Sol / Terra / Luna mark the capability tier (strong / balanced / fast-and-cheap). Within a generation, you just pick by need.
3Capability Leap
So Where's the Strength This Generation
The capability gains OpenAI released cluster in three areas: coding, biology, and cybersecurity. Each comes with a benchmark score.
Coding · Terminal‑Bench 2.1
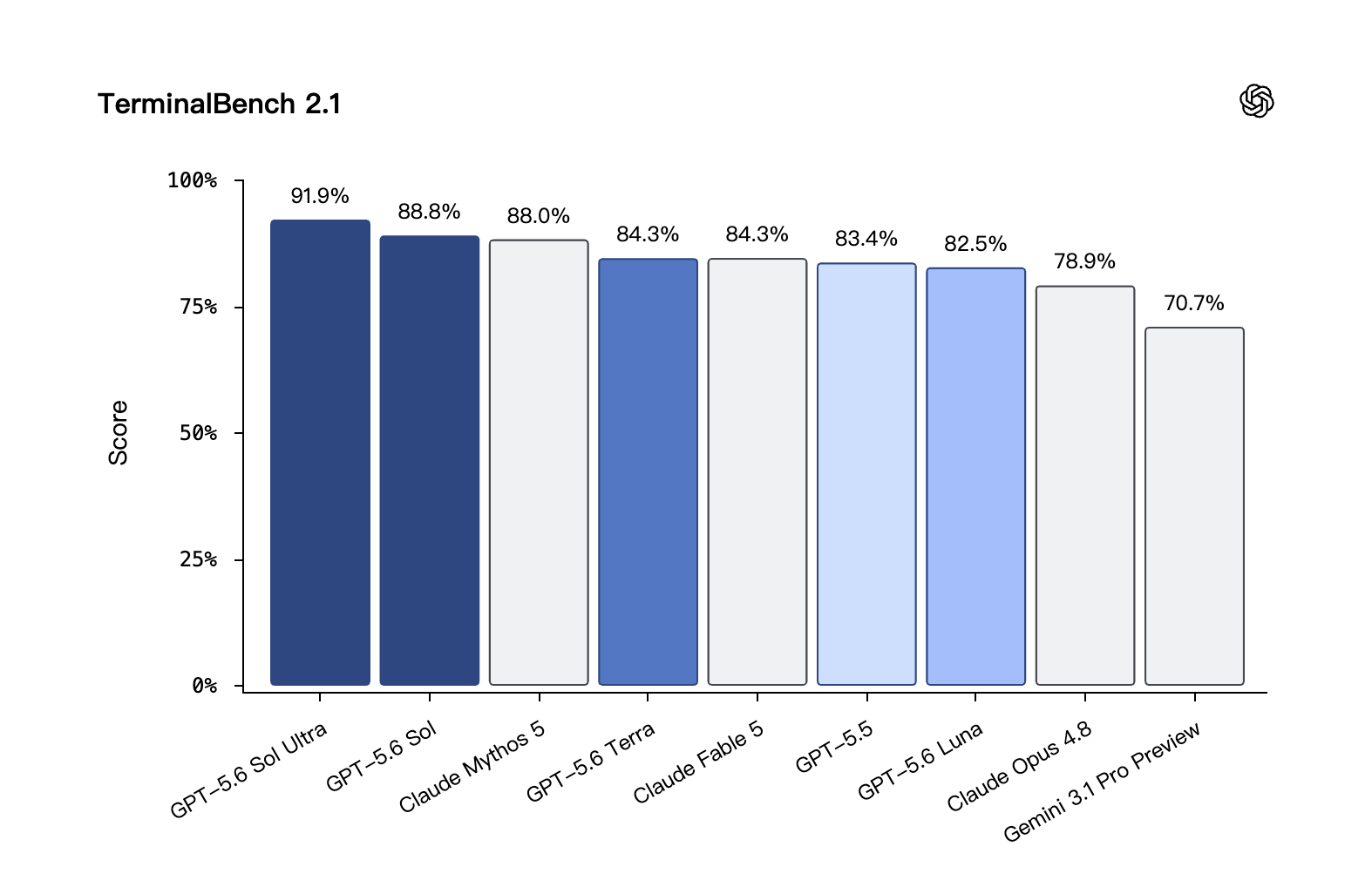
Tests command-line workflows that need planning, repeated trial and error, and coordinating multiple tools. GPT‑5.6 Sol sets a new best (SOTA).
OpenAI self-eval
Biology · GeneBench v1
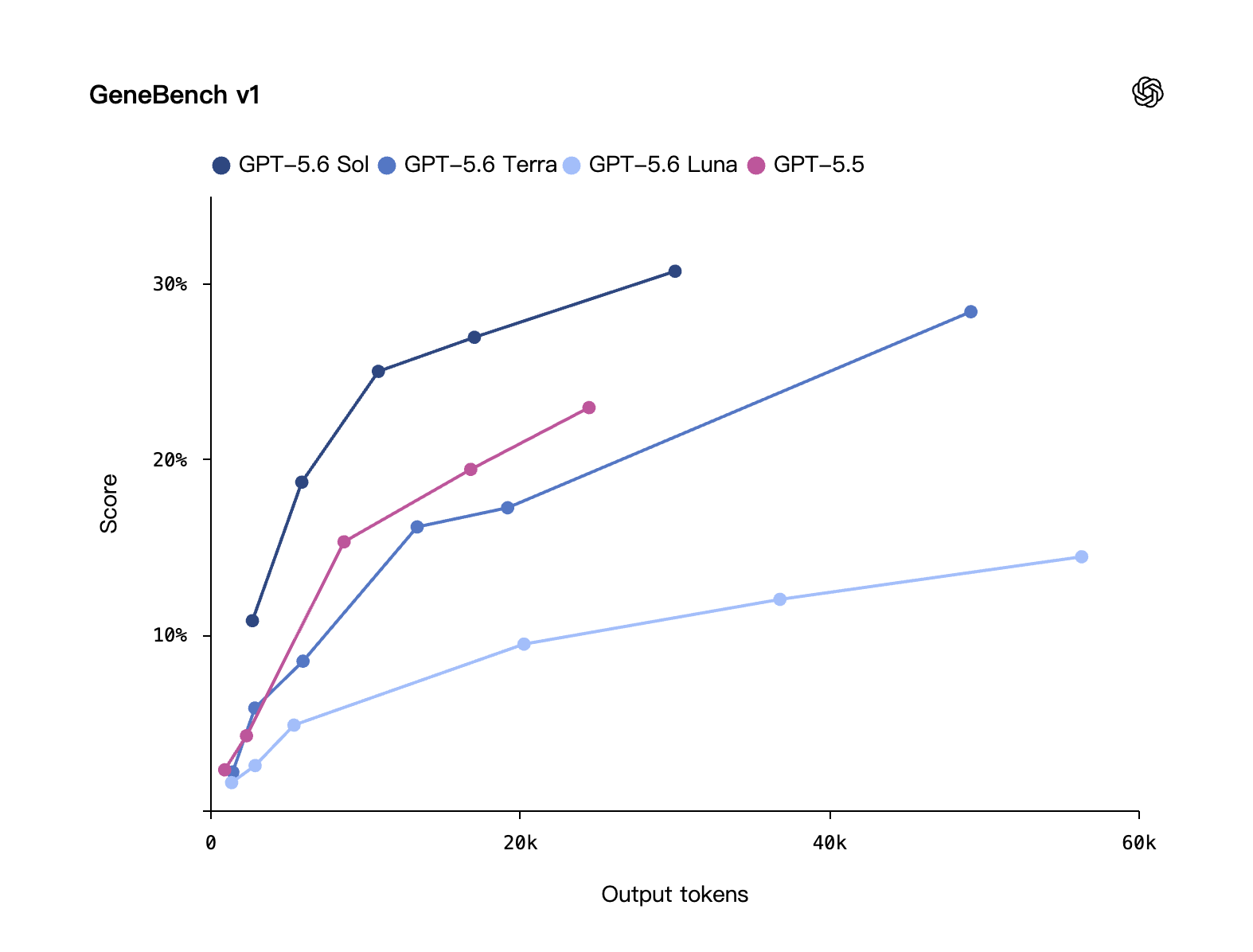
Tests long-horizon genomics and quantitative biology analysis. Sol beats the previous GPT‑5.5 while using fewer tokens.
OpenAI self-eval
Cybersecurity · ExploitBench / ExploitGym
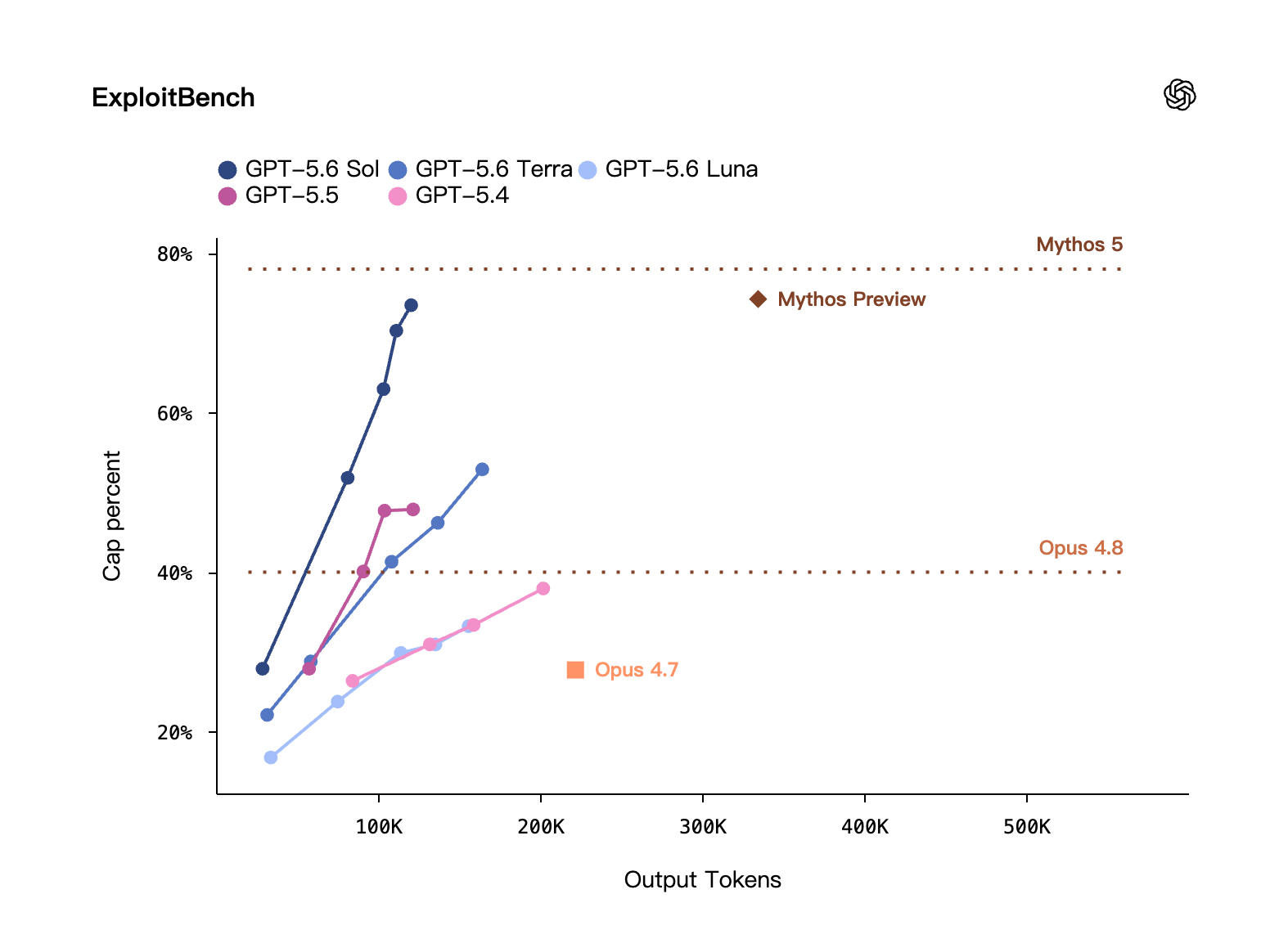
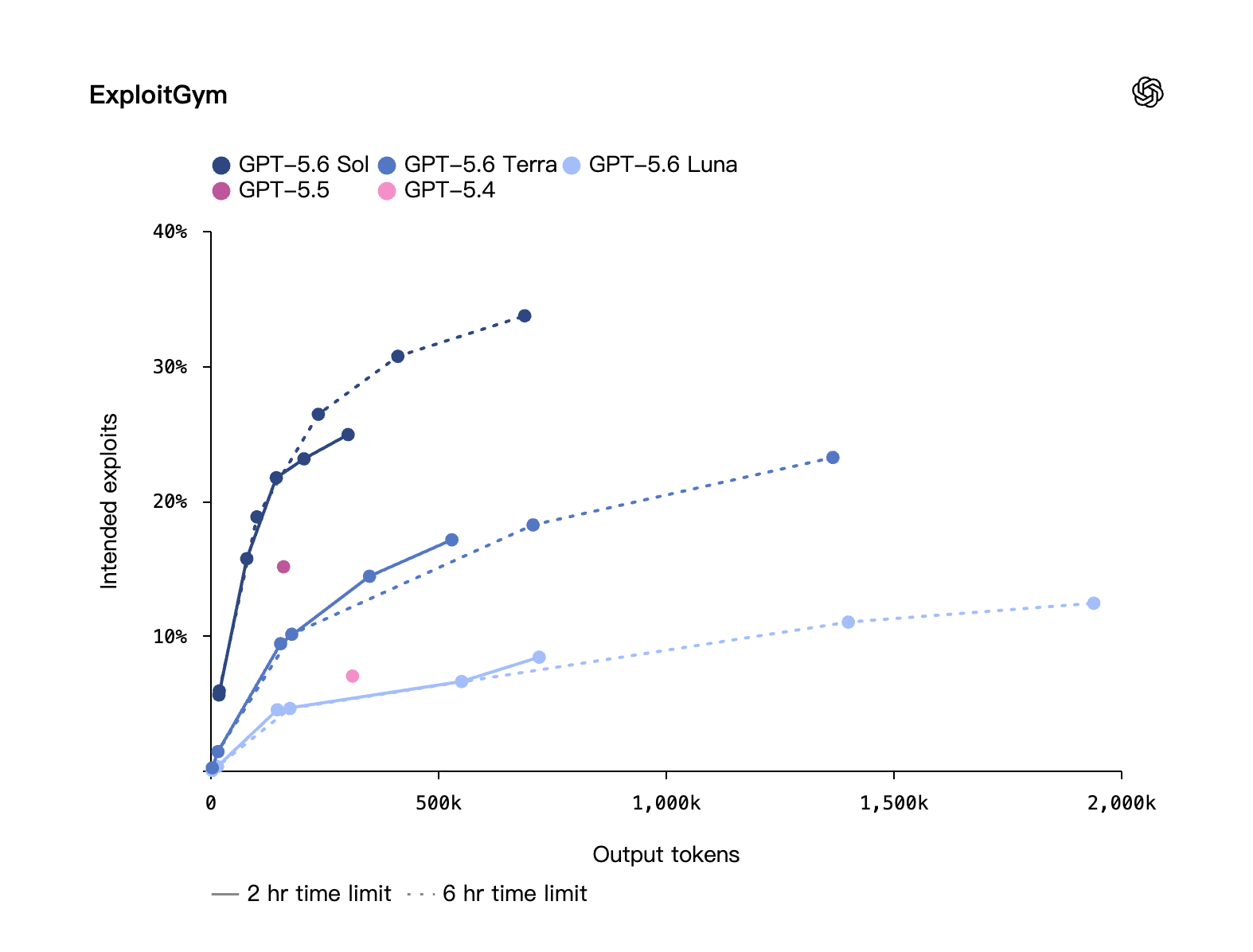
On ExploitBench it ties Mythos Preview while using only about 1/3 the output tokens; ExploitGym (a benchmark built by UC Berkeley with OpenAI and others) shows that as reasoning scales up, Sol / Terra / Luna all keep gaining cyber capability.
OpenAI self-eval; comparison terms set by vendor
Coding · TerminalBench 2.1: GPT-5.6 Sol Ultra leads at 91.9%, and base Sol (88.8%) also tops Claude Mythos 5 (88.0%). Source: OpenAI self-eval.
Biology · GeneBench v1: output tokens on the x-axis, score on the y-axis. GPT-5.6 Sol gets a higher score using fewer tokens. Source: OpenAI self-eval.
Cybersecurity · ExploitBench: cap percent on the y-axis, output tokens on the x-axis. GPT-5.6 Sol nears Mythos 5's level (top dashed line) while using only about 1/3 the tokens. Source: OpenAI self-eval.
Cybersecurity · ExploitGym: intended exploits on the y-axis, output tokens on the x-axis. More reasoning (tokens) means higher offense/defense scores for Sol / Terra / Luna. Source: OpenAI self-eval (joint benchmark with UC Berkeley and others).
Two New Tiers: max and ultra
max
Gives the model the most time to think slowly — for the hardest problems that need the most back-and-forth.
ultra
Goes beyond a single agent: temporarily spins up a batch of "sub-agents" to work in parallel, speeding up complex tasks and pushing past one agent's ceiling.
An Analogy
max is letting one person think longer; ultra is pulling together a small squad to work at the same time, split across tasks.
4Cyber Red Line
Will It Help Build Attack Weapons? Did It Cross the Line
With stronger cyber capability this generation, the natural worry is: will it just help someone build an attack weapon? OpenAI's answer is that it can make the "parts," but in testing it didn't assemble the finished "product" on its own.
Two Terms, First
Exploitation primitives are the building blocks of an attack — say, a single memory out-of-bounds. A full-chain exploit assembles those parts into a press-and-go finished weapon. The model can make the parts, but in testing it didn't assemble a "gun" that fires on its own.
In evaluations involving Chromium and Firefox, GPT‑5.6 Sol could find bugs and exploitation primitives, but under test conditions it did not autonomously produce a usable full chain. Under OpenAI's Preparedness Framework (its self-defined risk-readiness framework), it was assessed as not crossing the Cyber Critical line — that is, not reaching the threshold of "possessing critical attack capability that must trigger stronger controls."
Cyber Critical line
GPT‑5.6 Sol assessed here
✓
Can do:find bugs and exploitation primitives.
✕
Didn't do in testing:autonomously assemble a usable full-chain exploit.
→
Takeaway:assessed below the line — better at helping people "find and fix vulnerabilities" than at launching end-to-end attacks.
Still, a benchmark line can't cover every real-world use once the model is combined with other tools. That uncertainty, plus the across-the-board capability jump, is exactly why this generation pairs stronger safeguards with a phased rollout.
5Core · Layered Safety Stack
Six Gates to Stop Bad Requests
What OpenAI calls "the strongest safety stack yet" isn't one taller wall but six layers stacked to work together. Its point is blunt: against a determined, adaptive abuser, no single safeguard is enough.
The stronger the capability, the more gates. A high-risk request is stopped at layer two (real-time checks); a legitimate request passes all six to reach the user. Each layer only blocks a different thing — stacked, they're steadier than any one alone.
Core Innovation
What's most distinctive this generation isn't the model itself, but that "making the model stronger" and "making abuse harder" scale up together: bump capability up a notch and you lay down more layers of defense, with the configuration tuned per model by capability.
1
Trained-in refusals
During training the model is taught to refuse policy-violating cyberattack requests, even when users disguise intent or try to jailbreak. This is the first boundary, deciding what the model should and shouldn't help with.
2
Real-time output checks
Two classes of abuse classifiers — cyber and biology — scan the output as it's generated. In high-risk cases, if something looks like a violation, generation pauses and hands off to a larger reasoning model for review.
3
Account-level signals
Flagged activity triggers an account-level review across conversations. Looking at a whole account rather than a single line helps tell "persistent abuse" apart from "normal dual-use security work."
4
Differentiated access
The most sensitive capabilities aren't open to everyone by default, but channels stay open for normal defensive work — code review, vulnerability research, patch development, debugging, security education.
5
Monitoring & enforcement
Content retention, review, and handling per the terms of use and policy, with action taken against violations.
6
Continuous testing
Ongoing red-teaming and stress-testing during the preview, feeding newly found holes back into the safeguards so the whole system evolves alongside attack techniques.
The dual-use dilemma: defense and offense look alike at first — the same technical concepts show up in completely different contexts. So the preview's safeguards may wrongly block some legitimate work, or slow normal tasks via pause-and-review — which is exactly one of the things the preview is meant to test.
6How a Block Happens
One Dangerous Question's Trip Through the System
Let's pull out layer two — "real-time checks" — and walk it once: a high-risk request comes in, and "pause mid-generation, larger model reviews, block if non-compliant" plays out.
Request comes in
→
Scanned by classifier as it generates
→
Hits high-risk, pauses
→
Larger reasoning model re-reads context
→
Ruled a violation, cut off before reaching user
The key is that checking happens "as it generates": the cyber and biology classifiers watch the model's output in real time, and the moment a high-risk case turns up something that looks like a violation, generation pauses and a larger reasoning model is called to re-read the whole conversation and context. If the review rules it a violation, that output is held back before it ever reaches the user.
7Automated Red-Teaming
Using AI to Defend Against AI
Safeguards also have to withstand attackers who switch tactics on the fly. Defenses that only work against a fixed, known list of attacks aren't enough for a frontier model. So this time OpenAI poured serious compute into "letting the model find its own holes."
700,000+
A100-equivalent GPU hours spent on automated red-teaming, hunting for universal jailbreaks
Universal jailbreaks
The automated red team's main target: a hole that works across many prompts and many scenarios
Two Terms First
A universal jailbreak isn't a key that opens one door — it's a master key that works across many prompts and scenarios, which is why it's the most dangerous and the one the red team specifically goes after. An A100-equivalent GPU hour is a unit that converts compute into "how many hours one A100 card runs," and 700,000 hours is roughly the scale of one card running continuously for about 80 years.
Why automated rather than purely manual? OpenAI's reasoning: setting its own model loose to find weaknesses covers far more attack patterns than humans can, spots failure patterns earlier, and shortens the path from "finding a weakness" to "patching it." Going after these harder, more universal attacks adds another layer of testing beyond the fixed list of known holes.
How human red teams and rapid response fill the gaps
Beyond automation, OpenAI also brought in third-party testers for large-scale human-expert red-teaming, which will continue during the preview. Human red teams cover the creative blind spots — the abuse methods the system can't anticipate, the ones a human brain dreams up.
OpenAI also admits no evaluation can cover every product configuration, multi-step attack, or real-world workflow. So it keeps a rapid-response process: reproduce, assess, prioritize, and patch newly found jailbreaks, then fold each into routine evals so the same class of failure can be caught later.
8Rollout Pace & Pricing
Why the Government Sees It First, Then You
This "limited preview" isn't OpenAI's long-term wish but a short-term step taken at the US government's request. Here's how the rollout goes.
Before launch · Preview to government
As part of ongoing communication with the US government, OpenAI showed the rollout plan and model capabilities to the government before launch.
Now · Limited to trusted partners
At the government's request, it first opens via API and Codex to a small set of trusted partners and institutions, with the list shared with the government. Testing and close coordination with partners continue through the preview.
Weeks later · Wider access
The plan is to open Sol / Terra / Luna more broadly to people using ChatGPT, Codex, and the API.
OpenAI's stance: it says plainly it doesn't think this kind of government-gated access should become a lasting default, because that would keep the best tools from the users, developers, businesses, and cyber defenders who actually need them. It says it's taking this step because, while building out a cybersecurity executive-order framework with the government and setting a reusable process for future model launches, this is the steadiest path to the wider access coming weeks later.
Pricing: Per Million Tokens
Model
Input
Output
Position
Sol
$5
$30
flagship, strongest
Terra
$2.5
$15
balanced, everyday
Luna
$1
$6
fastest, cheapest
Caching is more predictable: it supports explicit cache breakpoints (you pick where caching splits) and gives a minimum 30-minute cache lifetime. Starting with GPT‑5.6, cache writes are billed at 1.25× the uncached input price, while cache reads keep the 90% discount.
One more thing: Cerebras in July
OpenAI also plans to deploy GPT‑5.6 Sol on Cerebras in July, reaching up to 750 tokens per second. This is a future plan, open only to some customers at first, with wider access as capacity scales.
"We don't think this kind of government-gated access should become a lasting default. It would keep the best tools from the users, developers, businesses, cyber defenders, and partners worldwide who actually need them."OpenAI official blog, "Previewing GPT‑5.6 Sol"
This piece is an explainer of OpenAI's official blog post "Previewing GPT‑5.6 Sol" (June 26, 2026). Every capability claim, benchmark score (Terminal‑Bench 2.1, GeneBench v1, ExploitBench, ExploitGym), safety-stack strength, and the "did not cross the Cyber Critical line" conclusion is OpenAI's own evaluation and self-reported framing, not verified by independent third parties; OpenAI says the full evaluation suite will be published when the model goes broadly available. The Cerebras launch is a July plan, not an accomplished fact. Source: OpenAI official blog.