AI Saved 700 Headcount — Then Klarna Said Quality Dropped
- Around June 2026, Salesforce bought Fin for roughly $3.6B, NICE bought Cognigy, Zendesk bought Forethought, and Sierra hit a $10B valuation — AI support poured into enterprise core budgets en masse.
- In February 2024 Klarna disclosed that its AI support covered two-thirds of requests — the work of 700 full-time agents; about a year later the CEO admitted an over-focus on cost led to "lower quality."
- Alibaba's four-week randomized trial across 2.56 million conversations showed AI made issue identification 8.2% faster and lifted on-the-spot satisfaction 1.2% — but the odds of contacting support again about the same issue within 3 days didn't budge statistically.
- All 4 mainstream metrics (auto-resolution rate / handle time / escalation rate / cost per contact) quantify savings from the company's side — a confidently wrong answer can make every one of them look better.
- Author Lucius proposes a new framework: Support quality = Resolution × Context × Trust × Learning × Experience, replacing cost savings with the user's full journey as the core measure.
One Month, Four Big Deals, and AI Support Suddenly Became a Main Arena
On June 15, 2026, Salesforce announced it would acquire AI support company Fin for roughly $3.6 billion. In the same window, NICE bought Cognigy, Zendesk bought Forethought, and Sierra closed a new funding round at a $10 billion valuation.

Klarna: All Metrics Green — A Year Later the CEO Said "We Got It Wrong"
The old scorecard once handed first-gen AI support a beautiful report card.
In February 2024, Klarna reported that in its first month live, the AI assistant handled 2.3 million conversations, covering about two-thirds of support requests — the workload of 700 full-time agents. Average resolution time dropped from 11 minutes to 2, and the company expected the year's profit to improve by about $40 million as a result. For anyone managing a support budget, the numbers were flawless.

- 2.3M first-month conversations
- ≈700 full-time agents equivalent
- 11→2 minutes, resolution time
- $40M projected profit gain (self-estimated)
The company "focused too much on cost" and ended up with "lower quality." CEO Sebastian Siemiatkowski re-emphasized human agents.
Both statements hold at once, with no contradiction. AI did handle more conversations and did drive cost down. The problem is how you define "success."
Today's Scorecard Only Measures How Much the Company Saved
Auto-resolution rate, average handle time, escalation rate, cost per conversation — all four mainstream metrics are quantified from the company's side. They can tell you how much the queue shrank and how many tickets the human team dodged, but not whether the user got the right answer, whether they were forced to repeat themselves, or whether anyone picked up the hard problems.
Here's a key term: deflection rate — the share of conversations the AI resolves on its own without handing off to a human. As long as it isn't passed to a person, it counts as "success."
It's like steering people in line over to a self-service kiosk and calling it "served" — whether they actually got their task done, nobody records.
When "deflection rate" becomes the goal, the product gets pushed toward a few moves: keep users inside automation as long as possible, delay handoff to humans, cram fuzzy questions into existing answers, and close the easy tickets first. Each move makes the automation metrics look better — and each one can make the user's experience worse. A confidently wrong answer still counts as "success."
The user is stuck in automation repeating themselves while the system logs several "efficient responses." Even if the user eventually quits, handle time and ticket volume both look fine. First-gen AI support did automation well; its weakness was treating the cost the company saved as the result the user got.
Alibaba's 2.56-Million-Conversation Trial Exposed a Precise Gap in the Numbers
In a four-week randomized trial, Alibaba observed 5,940 agents, about 2.56 million conversations, and 390,000 user ratings. After generative AI was added, several metrics improved together.

The first four all improved — only the last one, the odds of contacting support again about the same issue within 3 days, was statistically insignificant (no detectable change). And that one is the only metric here that measures whether the problem was actually solved.
Speed went up, users felt better on the spot, but the share who came back didn't fall. Fast and satisfied explain only part of the experience; whether the problem moved toward a result is a separate question.
A New Framework: From "How Much We Saved" to "Did the User's Journey Finish"
If enterprise support is to carry the user's whole journey, the scorecard has to cover the whole journey too. Lucius breaks support quality into five dimensions measured together.
The previous generation of dashboards counted how many replies the AI sent and how many human hours it saved. This framework answers five questions: Did the user get a result? Did the context keep up? Did this interaction burn trust? Did this time make next time better? Does the user still want to stay in the community? Open each layer to see what the old system measured and what this layer adds.
1ResolutionDid the problem reach a result?+
Deflection rate and handle time — only whether the queue shrank.
Task success rate, first-contact resolution, repeat-contact rate, ticket reopen rate, and whether there's a clear owner and next step.
2ContextDid the information keep up?+
How big the knowledge base is, how many docs were stuffed in.
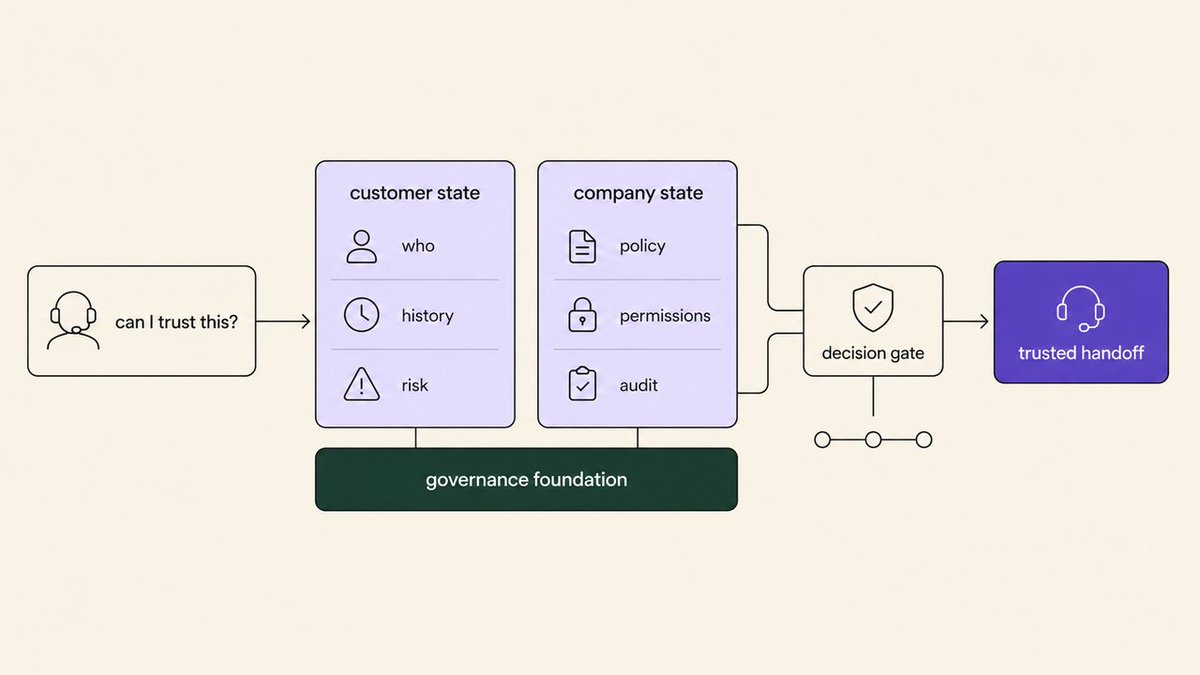
A live snapshot of company state + user state — whether the content is current, bounded, and actionable, rather than fluent answers based on an old version.
3TrustDid this interaction spend the relationship?+
Barely measured. The AI replies in the company's name, so a wrong line still counts as a company promise.
Whether it stops when information is missing, whether it over-promises, whether sensitive issues can move to a private channel, whether it keeps a full evidence trail for promises, refunds, and compliance, and whether it's accountable when something goes wrong.
Per a Sinch survey cited by ITPro, 74% of companies surveyed have rolled back or shut down a support AI agent over a governance failure. The main reasons: customer data leaks 31%, hallucinations or brand risk 22%, lack of auditability 16%. What companies care about isn't whether the AI seems human, but whether they can hand the service over with confidence.
4LearningDid this time make next time better?+
Not measured. Every conversation is one-off — once handled, it's over.
Whether uncertain questions become new knowledge in the system; whether the pitfalls, sticking points, and final breakthroughs from this user become reusable experience for next time.
5ExperienceDoes the user still want to stay?+
A single satisfaction score that papers over everything that happened along the way.
Whether the user is understood right where they are, or kicked to another entry point to log in again, fill out a form, and retell the problem. Every public reply shows how this organization treats people who ask for help.
An example: a beginner builds their first project from their own idea
In a tooling community, a beginner builds their first project from their own idea — wiring a workflow platform together with a low-code tool to make a page that takes article content and API credentials and, with one click, pushes the article to a draft folder. The project got stuck on response structure, API fields, variable binding, displaying results, and a 60-second timeout — and the whole chain finally ran end to end. Afterward he asked the community's AI persona to take the whole thing, from the very first message, and lay it out as a reusable path: project goal, overall architecture, five stages, every error, current state, and next step. He said it was the first time he felt he could build something from his own idea — the AI seemed to hold the entire process in its head and walk him forward. Old-style support that can only search a database for answers can't sustain this kind of end-to-end coaching.
Real "Resolution" Starts With Whether the User Dares to Speak Up
Resolution doesn't start with "did the AI answer" — it starts with whether the user is willing to speak up.
Educational psychology has a related concept, question-asking anxiety: when people feel the other side is authoritative, formal, and might judge them, they start censoring their own questions — is this too dumb, will I look like an amateur, am I bothering someone. Support is no different. An entry point that's too formal and cold makes users first weigh whether they're "qualified" to ask; an official window that only offers canned answers bottles many early questions back up in users' heads. By the time they actually come for help, the problem is often already more complex.
Speed matters. Right when the user speaks up, the problem is still fresh, emotions haven't fermented, and the missing context is easiest to fill. If the system at that moment dumps them onto another entry point, demands a form, or makes them wait for email, they may not ask next time. Real resolution is the system showing the user a path to a result: who's responsible, what happens next, when there'll be an update, where it's stuck now. Routing the user to another person, another channel, another form only proves the problem was moved elsewhere — if the user still doesn't know who's handling it, when, and how far along, the problem hasn't moved forward.
This echoes the gap in Alibaba's trial: AI made things feel better on the spot, but the repeat-contact rate didn't fall — proof that "answered fast" isn't "answered right, with a next step."
Lucius's 8 signals for measuring "resolution"
Task success rate · first-contact resolution · repeat-contact rate · ticket reopen rate · time to resolve · escalation success rate · owner-assignment rate · whether the next step is clear (with a bit of subjective judgment).
Context Isn't the Knowledge Base — It's Two Live Tracks Running at Once
Context holds two records that change at the same time: company state and user state. Miss either one and you answer new questions with old answers.

Many companies take pride in the sheer size of their knowledge base. Production forces a harder question: does this content still hold? Features change, prices change, policies change, staff revise the messaging, users receive new promises. Once the docs fall behind, the AI can still answer — it just gives old answers in fluent language. Context is useful only if it's current, bounded, and actionable.
Here's a term to keep straight: working memory — the running tally the AI keeps while handling this ticket: what it has collected, which actions it took, which step it's stuck on now.
It isn't the medical chart (the knowledge base) — it's the live operating record of "which step this surgery is on right now."
In Nubank's support system serving over 100 million users, instructions, workflows, macros, tool descriptions, and working memory are managed as separate, independently versioned components. Working memory records the information already collected, tool execution results, and which step handling is on now. When a low-confidence question is handed to a human, the entire conversation context goes with it, so the user doesn't have to play "context courier." This is closer to production-grade context management than cramming more docs into the prompt: the system has to know both the current facts and the current state of the task.
Update the Knowledge Base Once a Month, and Everything That Changes in Between Gets Old Answers
Same context, different maintenance cadence — and the odds of the AI answering new questions with old answers differ.
Traditional knowledge-base maintenance gets stuck here: many teams used to update docs only once a month, and even after updating they couldn't guarantee the AI retrieved the right one, so they chopped docs into ever-smaller fragments. Chopping doesn't necessarily make retrieval more accurate — it creates more similar fragments instead, making it harder for the system to tell which one still holds.

The team doesn't maintain docs by hand; Lucius routes uncertain questions to them, they answer as if replying to a message, and the system learns. Flip it around: if those 400 updates were compressed into one manual cleanup a month, that whole batch of new rules, exceptions, promises, and product changes would vanish in the gaps. A system that can't reach this context can only answer new questions with old answers.
Demand Has Woken Up — the Companies That Can Deliver Haven't Caught Up
The market sees the direction, but the migration isn't done. That gap is the window for whoever moves first.
Most companies are still stuck in old systems: docs scattered everywhere, past conversations buried in channels, support flows disconnected from what's happening in the community, human handoffs with no evidence trail, AI replies lacking boundaries and memory. Many misread the problem with AI support as "not human enough," so they keep polishing tone, persona, avatar, and greetings — but what users care about is something else entirely: whether the system actually understands the problem. Per Lucius, in support communities using its system, the share of users who actively ask for a human can fall below 0.1% (Lucius's own data).
Once users have experienced "the moment I speak up, the system knows who I am, I don't repeat myself, it remembers where I got stuck last time, and it brings in a human when it should," old-style support will feel as dated as dial-up internet. Companies still using last-gen chatbots to stall users will have to catch up eventually — and by then the problem they face won't be a tech-procurement one, it'll be a trust-repair one.
First-gen AI support was built around the company; the next generation will be built around the user's whole journey.Lucius / X · June 29, 2026