产品发布 · 小互解读
GPT‑5.6 发布了,但好像又没发布
一次出旗舰 Sol、均衡 Terra、低价 Luna 三档,网络安全是这代主攻方向。但先限量给可信伙伴、名单已报备美国政府,几周后才广泛开放。
速览
- OpenAI 于 2026 年 6 月 26 日开启 GPT‑5.6 系列限量预览,一次推出旗舰 Sol、均衡型 Terra、低价型 Luna 三个模型。
- 启用新命名:数字代表「第几代」,Sol/Terra/Luna 代表「能力档位」;Terra 性能接近上一代 GPT‑5.5,价格只要一半。
- 能力提升集中在编码、生物、网络安全三块,在 Terminal‑Bench 2.1 等基准刷新纪录,但所有数据均为 OpenAI 自评,完整评测要等广泛开放时公布。
- 配套号称迄今最强的安全栈:多层防护叠加协同,并投入超 70 万 A100 等效 GPU 小时做自动化红队找通用越狱。
- 应美国政府要求先限量给少数可信伙伴(名单已报备),几周后更广开放;定价每百万 token:Sol $5/$30、Terra $2.5/$15、Luna $1/$6。
⚑立场提示:本文基于 OpenAI 官方发布博客,属厂商通稿。文中能力跃升、基准成绩、安全栈强度均为 OpenAI 单方表述,未经独立第三方验证;预览期 OpenAI 自己也承认安全机制可能误拦合法请求。下文只解读它说了什么、怎么运作,不替读者打分。
1发布概览
GPT‑5.6 来了,一次来仨
OpenAI 于 2026 年 6 月 26 日开启 GPT‑5.6 系列的限量预览,一次推出旗舰 Sol、均衡型 Terra 和低价型 Luna 三个模型。
这不是一次普通的版本迭代。OpenAI 把「模型能力跳级」和「政府预览流程」捆在了一起:上线前先把能力和发布计划拿给美国政府看过,并按政府要求只先开放给一小批可信伙伴,几周后才广泛放开。
⚡为什么值得看:这是 OpenAI 首次把模型能力跃升与政府预览流程绑定发布。网络安全是这代重点提升方向,合作伙伴名单已报备政府,并投入超 70 万 A100 等效 GPU 小时做自动化红队。OpenAI 同时明说,不希望这种政府准入流程成为长期默认。
2怎么挑型号
一家仨型号,到底怎么挑
同一代里摆了三档,差别在「多强、多快、多贵」。点下面任意一档,看它适合干什么。
↓ 点一档查看适用场景
Sol:OpenAI 称是迄今最强的模型,配了两个新档位,max(给模型最多时间慢慢想)和 ultra(调一批子代理分头并行干)。对应最难、最绕的编码、科研、网络安全等长链条任务。
Terra:日常主力。OpenAI 称性能接近上一代 GPT‑5.5,价格只要一半,对应大多数「要够强又要省钱」的日常工作。
Luna:最快最便宜。OpenAI 称在最低价位上仍保留不错能力,对应走量、对延迟和成本敏感的场景。
新命名怎么读
以前一个数字打天下,能力档位、新旧全混在那个数字里。这次拆成两个维度:数字管「代际」,名字管「能力层级」,两边各自按自己的节奏升级。
旧命名
一个数字定全部:GPT‑5、GPT‑5.5……越大越新,但「想要更便宜更快的版本」只能等下一个小版本号。
新命名
数字(5.6)只表示第几代;Sol/Terra/Luna 表示能力档位(强/均衡/快省)。同一代里直接按需求选档。
3能力跃升
这代到底强在哪
OpenAI 放出的能力提升集中在三块:编码、生物、网络安全。每块都给了一个基准成绩。
编码 · Terminal‑Bench 2.1
考查命令行工作流,需要规划、反复试错和多工具协同。GPT‑5.6 Sol 刷新最佳成绩(SOTA)。
OpenAI 自评
生物 · GeneBench v1
考查长链条的基因组学与定量生物分析。Sol 比上一代 GPT‑5.5 更强,且用更少的 token。
OpenAI 自评
网络安全 · ExploitBench / ExploitGym
在 ExploitBench 上与 Mythos Preview 打平,但只用约 1/3 的输出 token;ExploitGym(UC Berkeley 联合 OpenAI 等机构做的基准)显示随推理量加大,Sol/Terra/Luna 的网络安全能力都在涨。
OpenAI 自评,对比口径由厂商设定
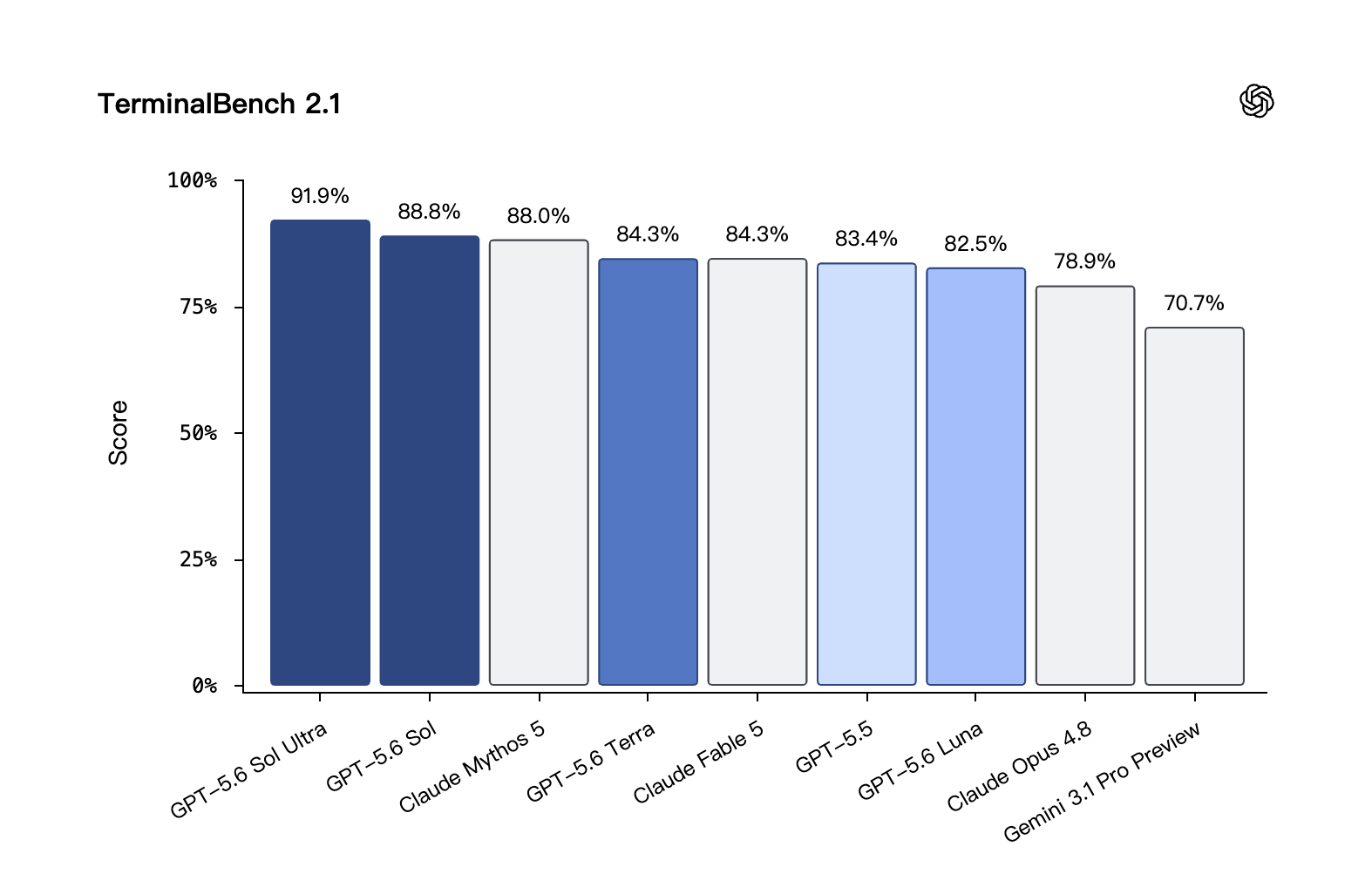
编码 · TerminalBench 2.1:GPT-5.6 Sol Ultra 以 91.9% 领先,基础版 Sol(88.8%)也超过 Claude Mythos 5(88.0%)。来源:OpenAI 自评。
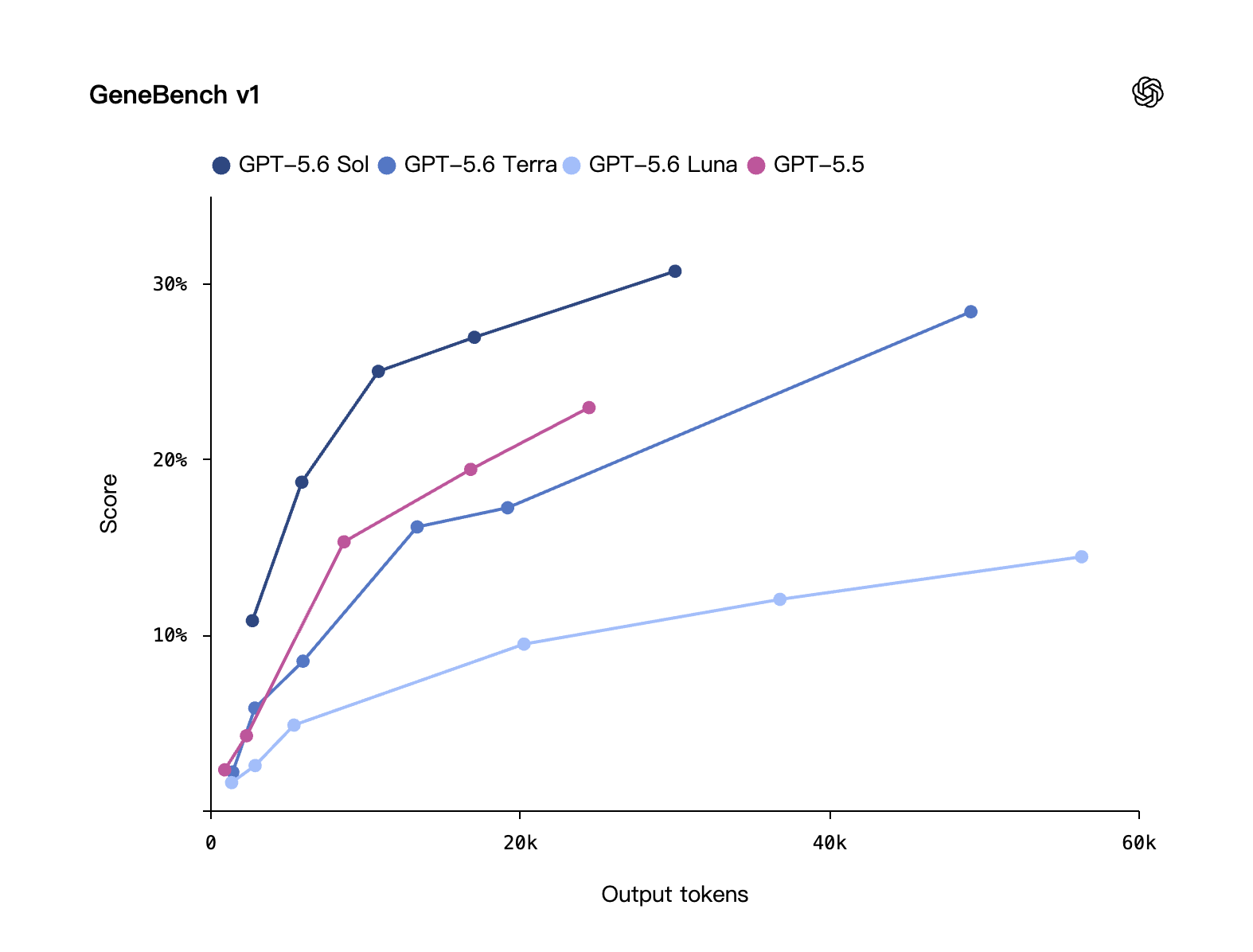
生物 · GeneBench v1:横轴输出 token、纵轴得分。GPT-5.6 Sol 用更少 token 拿到更高分。来源:OpenAI 自评。
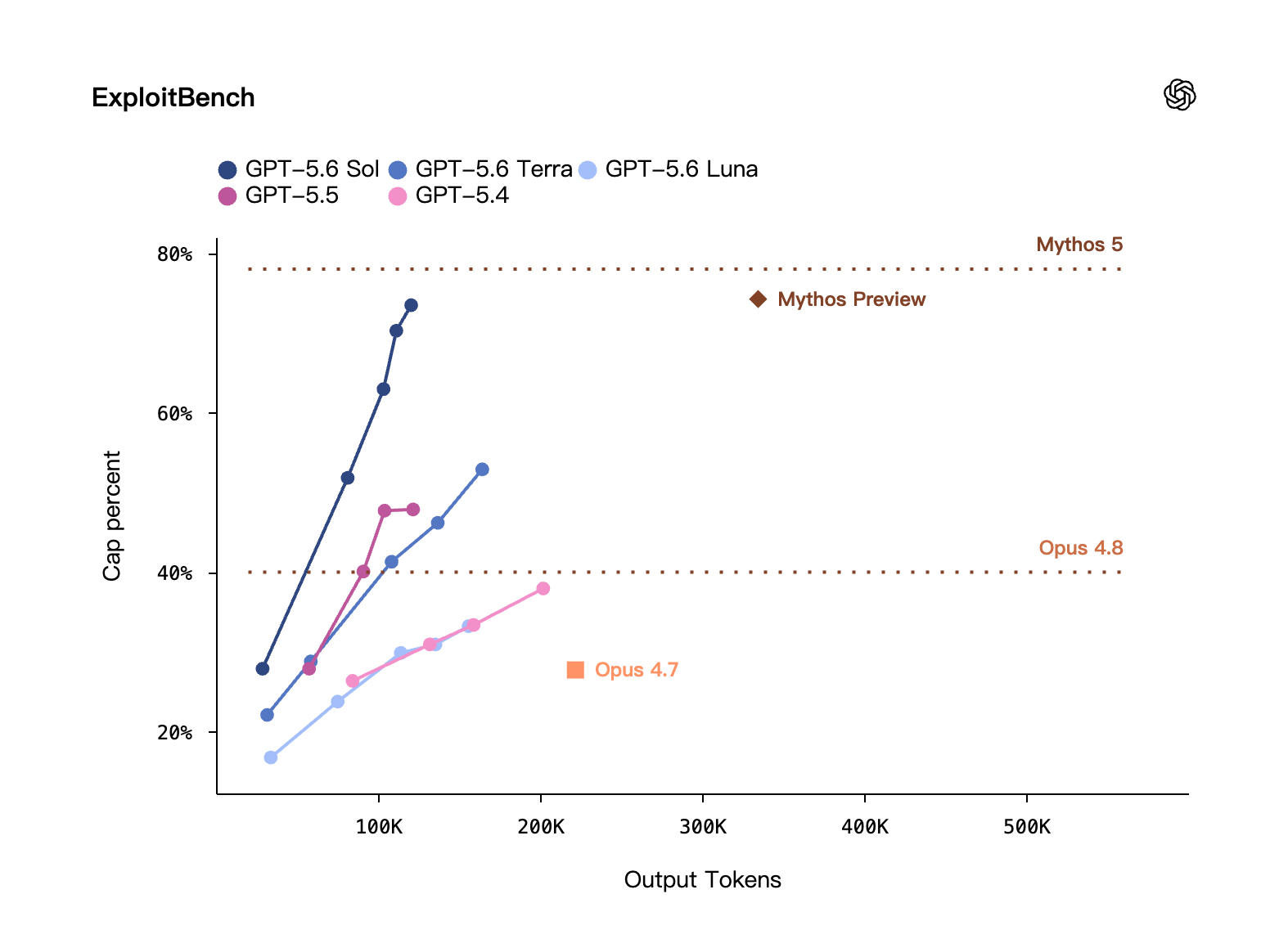
网络安全 · ExploitBench:纵轴 cap percent、横轴输出 token。GPT-5.6 Sol 逼近 Mythos 5 水平(顶部虚线),且只用约 1/3 的 token。来源:OpenAI 自评。
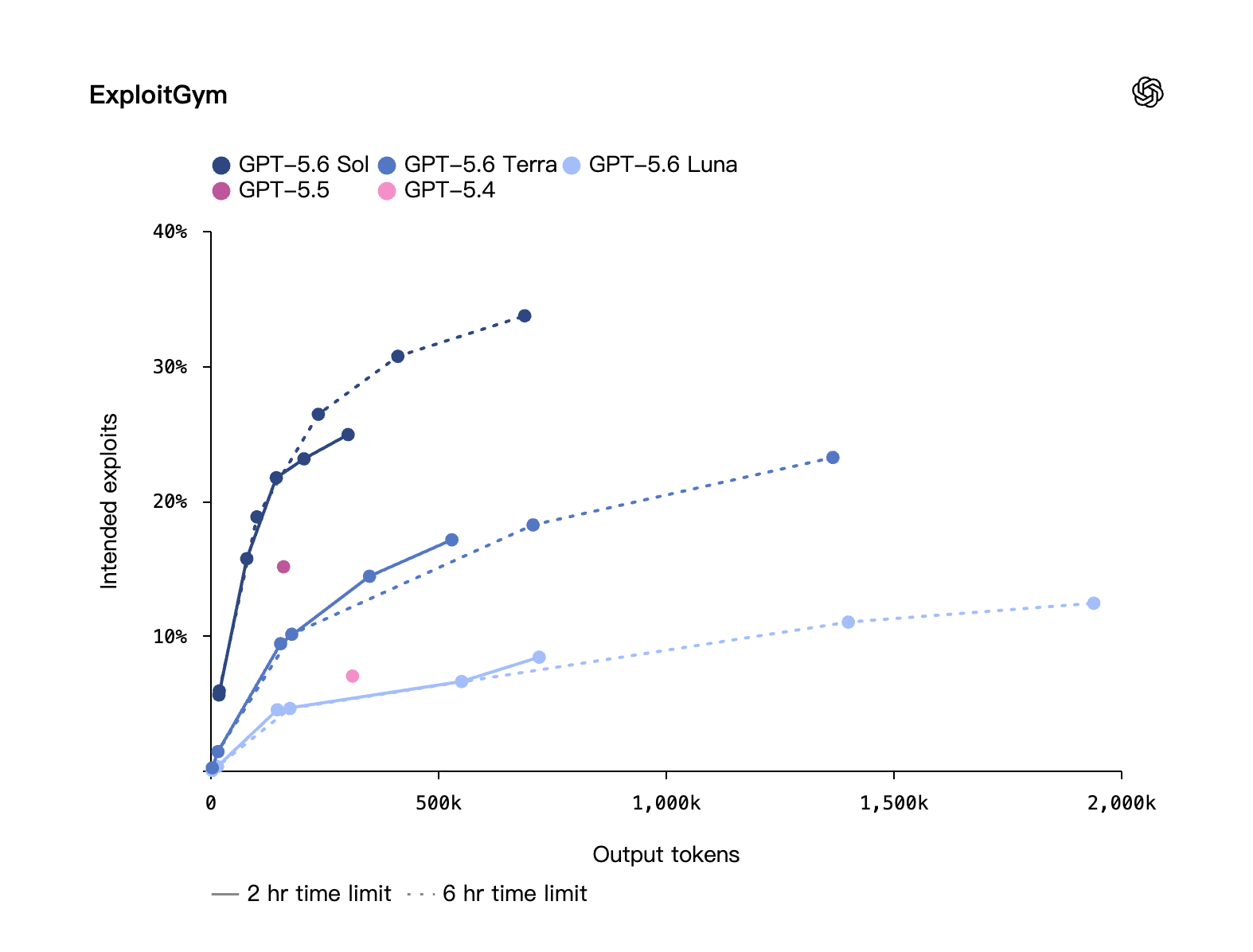
网络安全 · ExploitGym:纵轴 intended exploits、横轴输出 token。推理量(token)越大,Sol/Terra/Luna 的攻防得分越高。来源:OpenAI 自评(UC Berkeley 等联合基准)。
两个新档位:max 和 ultra
max
给模型最多时间慢慢想,对应最难、最需要反复推敲的问题。
ultra
不止靠一个智能体,临时调动一批「子代理」分头并行干活,加速复杂任务,超出单个智能体的能力上限。
打个比方
max 是让一个人想得更久;ultra 是临时拉一支小队,分头同时干。
4网络安全红线
会帮人写攻击武器吗?踩没踩红线
这代网络安全能力强了,自然有人担心:它会不会直接帮人造出攻击武器?OpenAI 给的答案是,能造「零件」,但在测试里没自己拼出「成品」。
先分清两个词
exploitation primitives(漏洞零件)是攻击用的积木,比如一处内存越界;full‑chain exploit(完整攻击链)是把零件拼成、按下就能用的成品武器。模型能造零件,但没在测试里自己拼出能开火的那把「枪」。
在涉及 Chromium 和 Firefox 的评估里,GPT‑5.6 Sol 能找到 bug 和 exploitation primitives,但在测试条件下没有自主产出可用的完整攻击链。按 OpenAI 的 Preparedness Framework(自定的危险预案框架),它被评定为没跨过 Cyber Critical 红线,也就是没达到「具备关键攻击能力、必须触发更强管控」的那条线。
Cyber Critical 红线
GPT‑5.6 Sol
评估位置
✓能做到:找到 bug 与 exploitation primitives(漏洞零件)。
✕测试中没做到:自主拼出可用的 full‑chain exploit(完整攻击链)。
→结论:评估位置落在红线之下,更擅长帮人「找漏洞、修漏洞」,而不是端到端发动攻击。
不过基准红线盖不住模型和其他工具组合后的所有真实用法,这份不确定加上能力的整体跳级,正是这代要配上更强防护、分阶段发布的原因。
5核心 · 分层安全栈
六道关卡拦住坏请求
所谓「迄今最强的安全栈」,不是一道更高的墙,而是六层防护叠起来协同工作。OpenAI 的说法很直接:面对铁了心、会随机应变的滥用者,任何单一防护都不够。
能力越强,关卡越多。一条高风险请求在第二层(实时检查)就被拦下;一条合法请求穿过六层到达用户。每一层只负责拦不同的东西,叠起来才比单层稳。
核心创新这代最特别的地方不在模型本身,而在「让模型更强」和「让滥用更难」是一起加码的:能力往上提一档,防护就多铺几层,配置还按每个型号的能力分别调。
1
模型内训练的拒绝
训练阶段就教会模型拒绝违规的网络攻击请求,哪怕用户伪装意图或试图越狱。这是第一道边界,决定模型该帮什么、不该帮什么。
2
生成时实时检查
cyber 和 biology 两类滥用分类器边生成边扫输出。高风险情形下若发现疑似违规,生成会暂停,交给更大的推理模型复审。
3
账户级信号
被标记的活动会触发跨对话的账户级复查。看一整个账户而不只看一句话,能把「持续作恶」和「正常的双重用途安全工作」区分开。
4
差异化访问
最敏感的能力不默认对所有人开放,但保留代码审查、漏洞研究、补丁开发、调试、安全教育这些正常防御工作的通道。
5
监控执法
按使用条款和政策做内容留存、复查与处置,对违规行为采取行动。
6
持续测试
预览期持续做红队和压力测试,把新发现的漏洞补回防护里,让整套机制跟着攻击手法一起进化。
双重用途的难题:防御和攻击初看很像,同样的技术概念会出现在完全不同的语境里。所以预览期的安全机制可能误拦一部分合法工作、或因暂停复审让正常任务变慢,这正是预览阶段要测的事情之一。
6拦截怎么发生
一个危险问题在系统里走一遭
把上一节第二层「实时检查」单独拆开走一遍:一条高风险请求进来,「生成中途暂停、更大模型复审、不合规就拦下」是怎么发生的。
请求进来
→
边生成边被分类器扫
→
命中高风险,暂停
→
更大推理模型读上下文复审
→
判定违规,在到达用户前截断
关键在于检查是「边生成边做」的:cyber 和 biology 分类器实时盯着模型正在吐的内容,一旦高风险情形里发现疑似违规,就把生成暂停,叫一个更大的推理模型把整段对话和上下文重读一遍。复审认定违规,这段输出就在送到用户面前之前被扣下。
7自动化红队
用 AI 来防 AI
防护还得扛得住攻击者随时换打法。只对一份固定的已知攻击清单管用的防护,对前沿模型来说不够。所以 OpenAI 这次把大量算力投进了「让模型自己找漏洞」。
700,000+
投入自动化红队的 A100 等效 GPU 小时,专找通用越狱
通用越狱
自动化红队的主攻目标:一招能跨多种提问、多种场景奏效的漏洞
两个词先讲明白
universal jailbreak(通用越狱)不是一把只能开一扇门的钥匙,而是一把万能钥匙,能跨很多提问和场景都奏效,所以最危险,红队专挑这种打。A100 等效 GPU 小时则是把算力折成「用一块 A100 显卡跑多少小时」的统一单位,70 万小时大致相当于一块卡连续跑约 80 年的算力量级。
为什么用自动化而不是纯人工?OpenAI 的理由是:让自己的模型去找弱点,能覆盖远比人工更多的攻击套路,更早发现失败规律,也能把「发现弱点」到「补上弱点」的路缩短。专攻这种更难、更通用的攻击,等于在固定的已知漏洞之外再测一层。
人工红队和快速响应怎么补位
除了自动化,OpenAI 还找了第三方测试者做大规模人类专家红队,预览期会继续。人类红队补的是创意盲区,那些系统预料不到的、靠人脑想出来的滥用方式。
OpenAI 也承认,没有任何评测能覆盖所有产品配置、多步攻击或真实工作流。所以它维持一套快速响应流程:复现、评估、排序、修补新发现的越狱,再把它加进日常评测,以后能测出同类失败。
8发布节奏与定价
为什么先给政府看、再给你用
这次「限量预览」不是 OpenAI 的长期意愿,而是应美国政府要求的短期一步。发布路径是这样走的。
上线前 · 向政府预览
作为与美国政府持续沟通的一部分,OpenAI 在发布前先把发布计划和模型能力拿给政府看过。
现在 · 限量给可信伙伴
应政府要求,先通过 API 和 Codex 开放给一小批可信伙伴和机构,名单已与政府共享。预览期继续测试、和伙伴密切协调。
几周后 · 更广开放
计划把 Sol/Terra/Luna 更广泛地开放给使用 ChatGPT、Codex 和 API 的人。
OpenAI 的态度:它明说不认为这种政府准入流程应该成为长期默认,因为这会让最好的工具到不了真正需要它的用户、开发者、企业和网络防御者手里。它说走这一步,是因为在和政府一起搭建网络安全行政令框架、为将来模型发布定一套可复用流程的同时,这是通往几周后更广开放的最稳路径。
定价:每百万 token
| 型号 | 输入 | 输出 | 定位 |
|---|
| Sol | $5 | $30 | 旗舰最强 |
| Terra | $2.5 | $15 | 均衡日常 |
| Luna | $1 | $6 | 最快最便宜 |
缓存方面更可预测:支持显式 cache breakpoints(自己指定缓存切点),并给出 30 分钟的最小缓存存活时长。从 GPT‑5.6 起,缓存写入按未缓存输入价的 1.25 倍计费,缓存读取继续享 90% 的折扣。
还有一条:7 月上 Cerebras
OpenAI 还计划在 7 月把 GPT‑5.6 Sol 部署到 Cerebras 上,速度可达每秒 750 个 token。这是未来计划,初期只对部分客户开放,随产能扩张再放开。
「我们不认为这种政府准入流程应该成为长期默认。它会让最好的工具无法到达真正需要它的用户、开发者、企业、网络防御者和全球伙伴手中。」OpenAI 官方博客《Previewing GPT‑5.6 Sol》
本文为 OpenAI 官方博客《Previewing GPT‑5.6 Sol》(2026 年 6 月 26 日)的解读。文中所有能力描述、基准成绩(Terminal‑Bench 2.1、GeneBench v1、ExploitBench、ExploitGym)、安全栈强度及「未跨越 Cyber Critical 红线」的结论均为 OpenAI 自家评测与自评口径,未经独立第三方验证;完整评测套件 OpenAI 称将在模型广泛开放时再公布。Cerebras 上线为 7 月计划,非已发生事实。来源:OpenAI 官方博客。