Anthropic 发布 Claude Sonnet 5:便宜四成,部分任务追平 Opus 4.8
- Anthropic 发布 Claude Sonnet 5,官方称其为目前自主执行任务(agentic)能力最强的 Sonnet 系列模型。
- 限时定价为每百万 token 输入 $2 / 输出 $10(截至 2026 年 8 月 31 日),之后涨至 $3 / $15;作为对比,旗舰 Opus 4.8 定价为 $5 / $25。
- 今日起在 Free、Pro、Max、Team、Enterprise 全部计划及 Claude Code、Claude 开发平台上线,是 Free 和 Pro 计划的默认模型。
- 安全评测显示其整体不当行为率低于上一代 Sonnet 4.6,但开发软件漏洞利用等网络攻击能力明显弱于 Opus 4.8,官方默认为其开启了实时网络安全防护。
- 换用了新分词器,同样文字可能被切分成更多 token(约 1.0 到 1.35 倍),限时定价已把这个因素折算进去,此次升级换算下来大致成本中性。
这次发布,便宜的那个追上了贵的那个
Anthropic 近日发布 Claude Sonnet 5,称其为迄今能力最强、最擅长自主执行任务(agentic,指模型能自己拆解任务、调用浏览器和终端等工具、连续跑完多个步骤,过程中还主动检查自己有没有做对)的 Sonnet 系列模型。
为什么值得看:按每百万输出 token 算,Sonnet 5 标准价 $15,Opus 4.8 是 $25,正好六成;限时价更低到输入/输出 $2/$10。而在 BrowseComp(智能体搜索)和 OSWorld-Verified(电脑操作)这两项评测里,调高算力挡位后 Sonnet 5 能与 Opus 4.8 打平。「更便宜」和「够得到旗舰」这两件事,第一次落在同一个 Sonnet 上。
会干活的模型,一直是 Sonnet 系列先做出来的
对很多开发者来说,「AI 会自己干活」这股风气是从 Sonnet 起的:Claude Sonnet 3.5、3.6、3.7 是最早在写代码和调用工具上让人眼前一亮的一批模型。但最近这段时间,能力提升最明显的是更贵的 Opus 系列,Sonnet 这条线被拉开了差距。Sonnet 5 要做的,就是把这个差距追回来。
agentic 能力
Opus 拉开
追回来
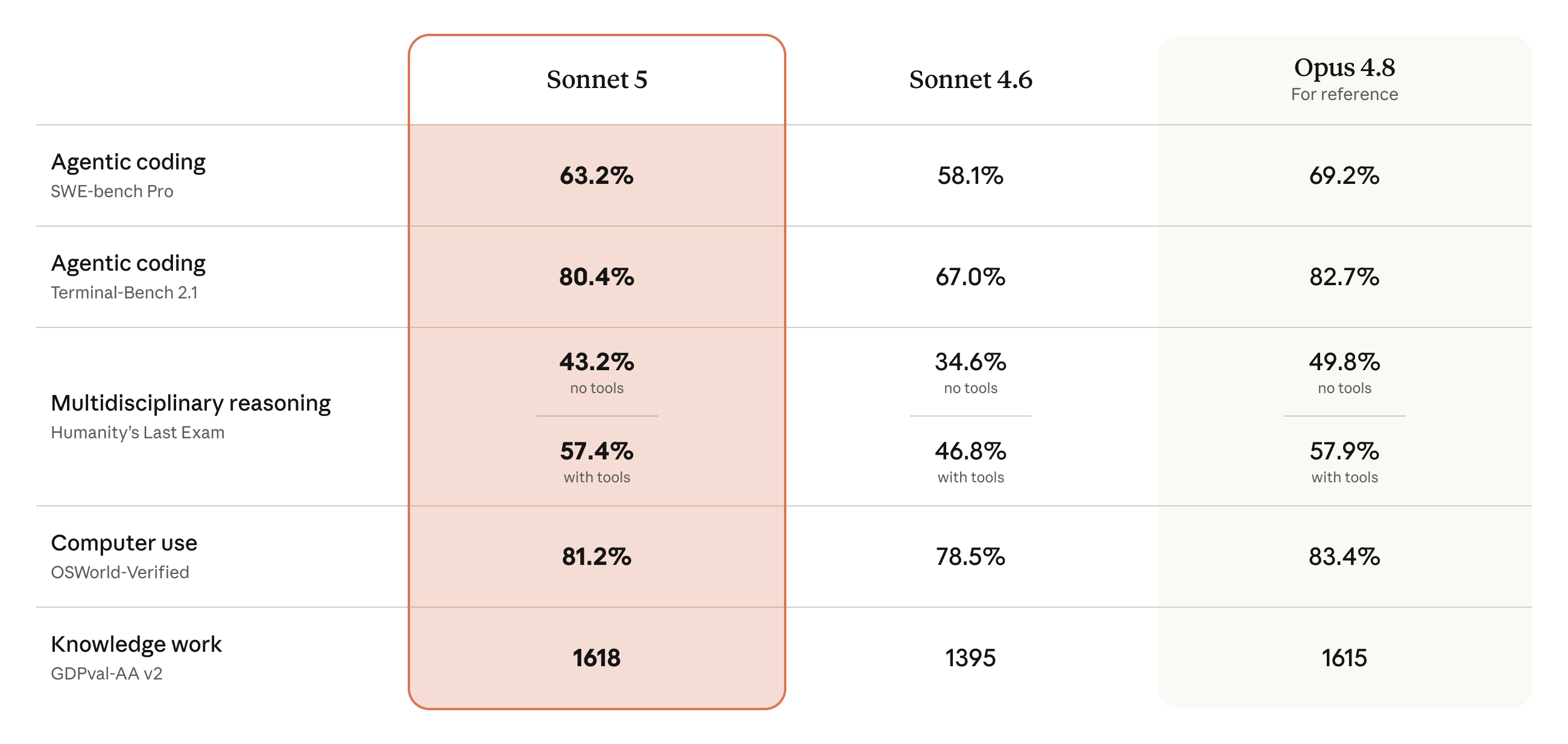
相比上一代 Sonnet 4.6,官方称 Sonnet 5 在推理、工具调用、写代码、知识工作这些和 agentic 表现相关的关键环节上都有明显进步。
同样一块钱,现在能买到多少智能
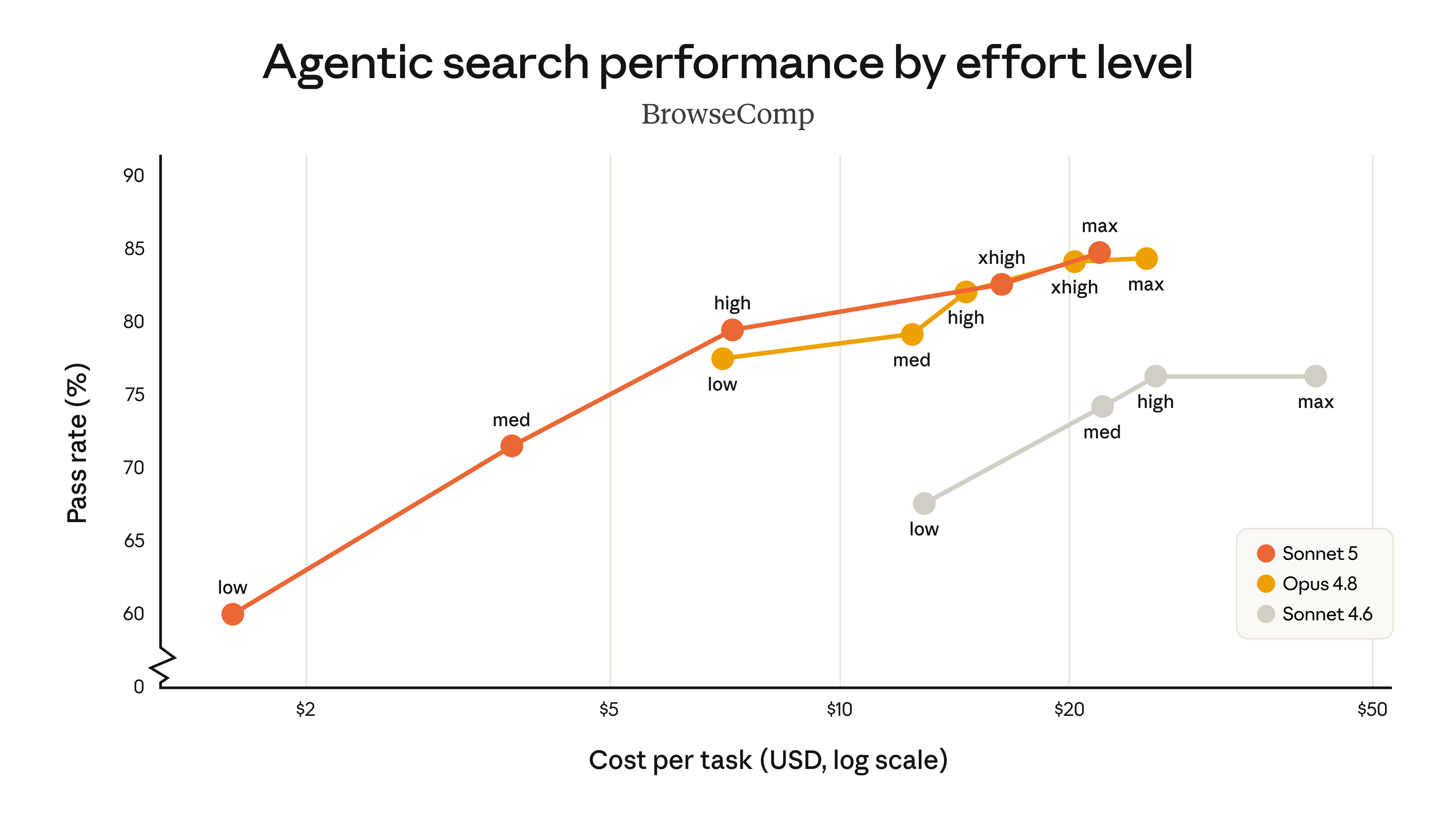
官方放出两张成本-性能曲线,比的是 Sonnet 5、Sonnet 4.6、Opus 4.8 在不同算力挡位下的表现,横轴是每个任务的花费(成本),纵轴是评测得分。结论是:Sonnet 5(橙线)全面强于 Sonnet 4.6(灰线),覆盖的成本区间比 Opus 4.8(黄线)宽得多,中等挡位性价比提升明显,最高挡位在部分任务上追平 Opus 4.8。
评测口径的两处更新(6 月 30 日更正)
官方在 6 月 30 日修订了这篇发布:原先 BrowseComp 那张图用的是一套更简单的方法,低估了 Sonnet 5 的表现,现已改用系统卡里的标准方法(1000 万 token 预算 + 压缩 + 程序化工具调用)重绘。另外,两项旧分数因评分方式更新而被修正:Humanity's Last Exam 的 Sonnet 4.6 得分更新为 34.6%(无工具)/ 46.8%(有工具);OSWorld-Verified 的 Sonnet 4.6 得分更新为 78.5%。这几处与 Sonnet 4.6 发布博客里的数字不同,原因就在于评测方式变了。
多花算力多想一步:一个模型怎么同时做到便宜和顶级
Sonnet 5 能横跨这么宽的价格区间,靠的是一个叫 effort(算力/推理强度挡位)的机制:同一个模型,让你自己选它「思考多用力」。挡位越低越便宜越快,但可能不够仔细;挡位越高,模型花越多算力去反复推理、自我核查,答案更准,但也更贵更慢。
就像同一家馆子点同一道菜,你可以让厨师照常出餐,也可以加钱请他多花功夫、上菜前自己先尝一遍确认没问题再端出来。菜是同一道菜,变的是他有多用心、检查了几遍。effort 挡位调的就是这个「用心程度」。
可能不够仔细
成本效率提升明显
更准更稳
部分任务追平 Opus 4.8
过去要更强的能力,得换一个更大更贵的模型。现在你不换模型,只调一个旋钮:低挡位就是便宜快的入门款,高挡位(xhigh)多花算力反复推理和自查,部分任务追平旗舰 Opus 4.8。一个 Sonnet 5,把从入门到接近旗舰的整条价格带一口气占满,而不像 Sonnet 4.6 那样早早触顶。成本和性能之间的平衡点,交给你自己按项目去定。
早期用户反馈:不用催,它自己会检查作业
官方称早期访问伙伴的反馈相当一致:Sonnet 5 比前几代明显更「会自己干活」。测试者提到的几点客观描述如下。
- 面对复杂任务,它能一直做到完成,而前几代 Sonnet 常常做到一半就停下。
- 没人明确要求,它也会主动检查自己的输出对不对。
- 做这些自主执行的活儿,价格还很有吸引力。
更安全了,但网络攻击这一项被刻意摁住
部署前的安全评测显示,Sonnet 5 整体比 Sonnet 4.6 更安全:更擅长拒绝恶意请求、更能抵抗提示词注入(prompt injection,指攻击者把恶意指令偷偷藏进模型要处理的网页或邮件里,企图劫持模型去执行攻击者而非用户的指令),幻觉和讨好用户的倾向也更低。在覆盖多种不当行为的自动化行为审计里,它整体得分更低(也就是更安全),但仍高于更强的 Opus 4.8 和 Claude Mythos Preview。
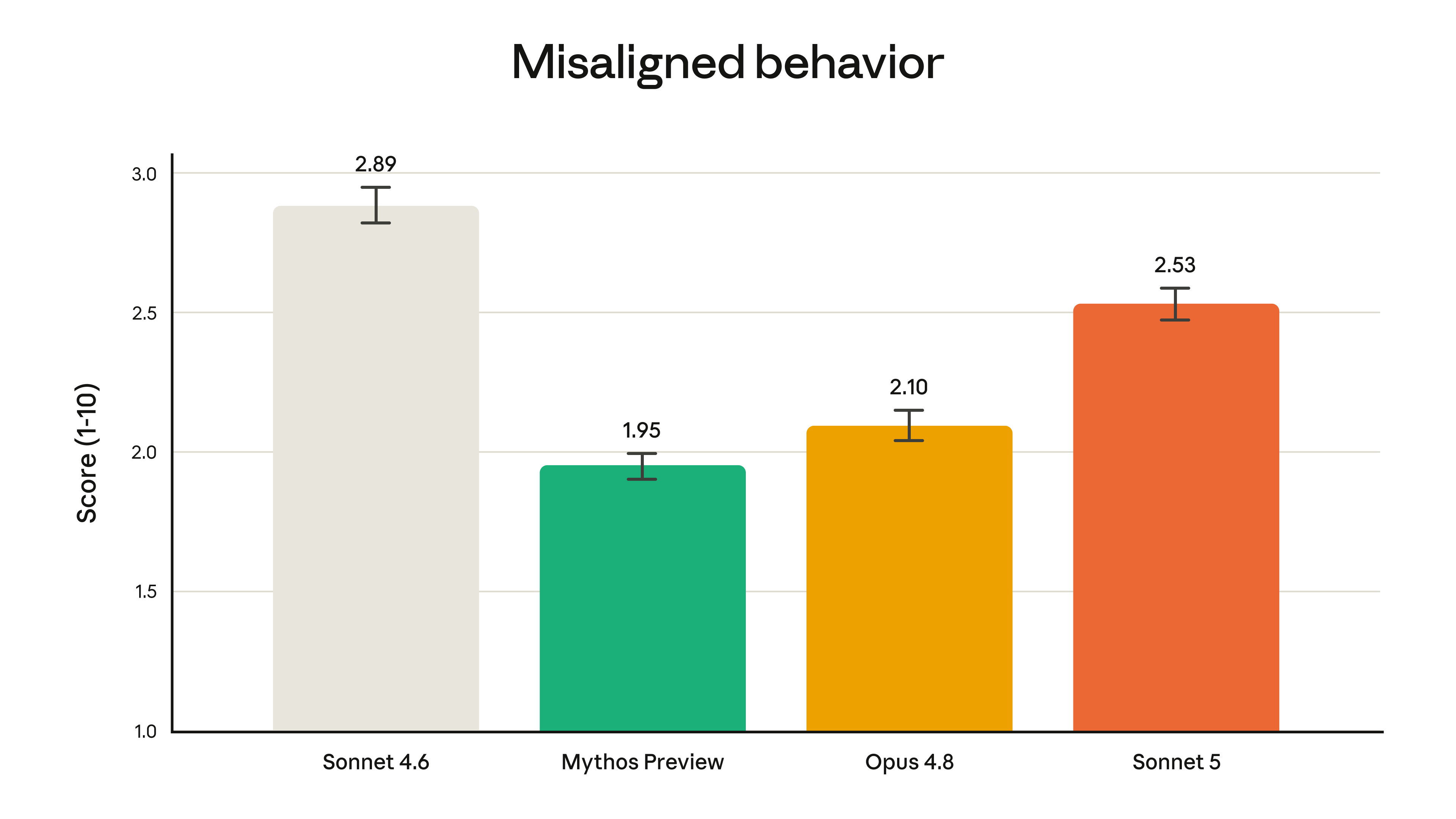
网络安全是被单独摁住的一项。官方说没有专门拿网络安全任务去训练 Sonnet 5:它能做些常规、无害的网络任务,但在开发软件漏洞利用这类可能造成危害的评测上,表现明显弱于 Opus 4.8 和 Mythos 5。
一次具体的测试:能不能黑穿 Firefox
「网络攻击能力弱」听着抽象,官方给了一组具体数字:让各模型去为 Firefox 浏览器里的漏洞开发利用程序(exploit)。这项评测由 Anthropic 与 Mozilla 联合开发,涉及的漏洞都已在 Firefox 148 里修复。
两款 Sonnet 都做不出一个完整可用的漏洞(均为 0.0%)。Sonnet 5 只是在部分成功率上比 Sonnet 4.6 略高,官方判断这多半来自整体智能变强的溢出,而非专门训练。作为对照,Opus 4.8 和 Mythos 5 的网络攻击能力都远强于这两款 Sonnet。
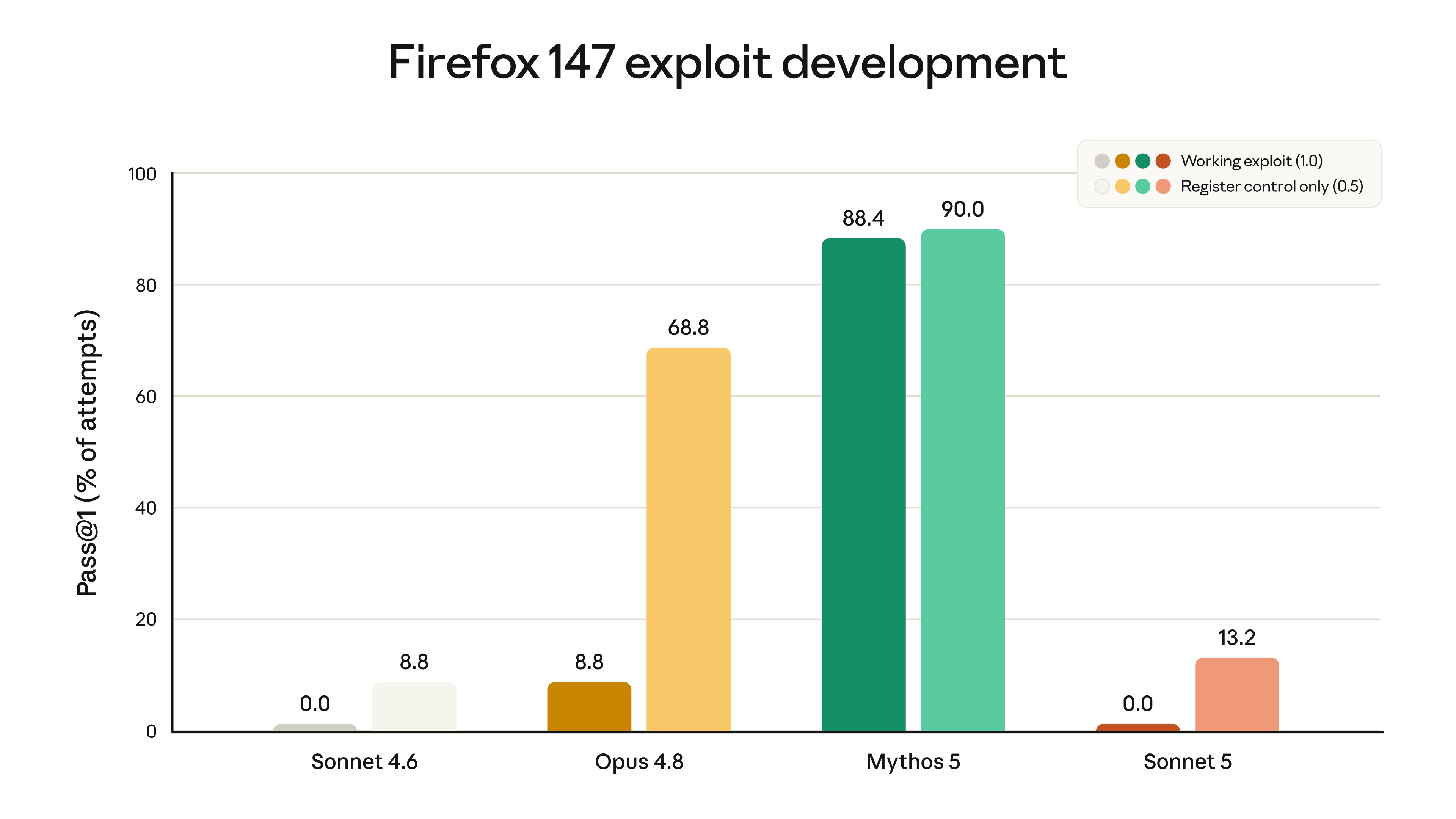
因为 Sonnet 5 在这类任务上比上一代略强,官方给它默认开启了实时网络安全防护,能实时检测并拦截危险的网络用途,这套防护与 Claude Opus 4.7、4.8 同级。官方判断 Sonnet 5 的整体网络安全风险较低,所以这套防护比 Fable 5 那套宽松(后者会拦截范围大得多的网络安全任务)。
看着降价了,其实是换了一把新尺子
Sonnet 5 换了新的分词器(tokenizer)。模型处理文字前,要先把文字切成一个个 token 来计费和计算。换了新分词器后,同一段文字可能被切成更多 token,大约 1.0 到 1.35 倍(看内容类型)。也就是说,单看每 token 的价格降了,但同样一段话消耗的 token 变多了,实际单位成本没降那么多。
每百万 token 从 Sonnet 4.6 的价位,降到限时 $2/$10。
限时定价就是照着抵消分词器变化来定的,让从 Sonnet 4.6 换到 Sonnet 5 大致成本中性。
官方明说:限时定价的设定,就是要让这次升级换算下来接近成本中性。这也是为什么「降价」得打个引号,账要连 token 数一起算。这次分词器的调整,和 Claude Opus 4.7 那次是同一类做法。
现在就能用:上线范围、价格表、怎么选
Sonnet 5 今日起在全部计划上线:它是 Free 和 Pro 计划的默认模型,Max、Team、Enterprise 用户也能用;同时上线 Claude Code 和 Claude 开发平台,开发者可通过 Claude API 调用 claude-sonnet-5。
| 模型 | 输入 / 输出(每百万 token) |
|---|---|
| Sonnet 5(限时,至 2026-08-31) | $2 / $10 |
| Sonnet 5(之后标准价) | $3 / $15 |
| Opus 4.8(对比) | $5 / $25 |
$2 / $10
限时
$3 / $15
标准价
为了适配更高算力挡位带来的更高 token 消耗,官方已在 Chat、Cowork、Claude Code、Claude 开发平台全线提高了调用速率上限,你可以按项目自己选合适的挡位。
怎么选
| 你是谁 | 建议 |
|---|---|
| 开发者 | 预算不变想要更强的 agentic 编程和工具调用:用高挡位;想省钱:调低 effort,用更低成本拿到接近旗舰的效果,自己在成本和性能间找平衡。 |
| 企业 / 团队 | Chat、Cowork、Claude Code、开发平台的速率上限已提高,适配高挡位的更高 token 消耗。 |
| 安全相关工作 | 默认网络安全防护与 Opus 4.7/4.8 一致;若需要限制更少的网络安全研究、攻防类工作,官方建议改用 Opus 4.8,而非 Sonnet 5。 |
Sonnet 5 缩小了差距:它的表现接近 Opus 4.8,但价格更低。 Anthropic《Introducing Claude Sonnet 5》