Claude Code 官方讲透循环设计:4 级递进到无人值守
- Anthropic 的 Claude Code 团队发博客,把「设计循环(loop)」拆成 4 种标准模式:回合制、目标制(
/goal)、时间制(/loop和/schedule)、主动式,按自主程度从低到高递进。 - 循环的官方定义:agent 反复执行一轮轮工作,直到满足某个停止条件才收工。四种类型按「谁触发、怎么判断停、用什么功能实现、适合什么任务」四个维度区分。
/goal的核心机制是引入一个独立的评估模型来判定是否达标,Claude 自己不能提前喊「够了就收工」,还可以设最多尝试次数上限。- 主动式循环把
/schedule(定时触发)、/goal(停止条件)、skills(校验标准)、dynamic workflows(多 agent 并行编排)、auto mode(免人工确认)五个功能叠起来,能无人值守地处理 bug 报告分诊、issue 分类、依赖升级这类持续性工作。 - 两条实操建议:确定性工作用脚本,比让 Claude 每次重新推导更省 token;大规模 dynamic workflows(可能拉起数百个 agent)上线前先在小范围试跑。
90 分「数百个 agent」等数字均引自原文,是官方口径。AI 帮你干活,但谁来决定「干完了」?
Claude Code 团队的 Delba de Oliveira 和 Michael Segner 于 2026 年 6 月 30 日在 Anthropic 官方博客发文,系统梳理了怎么为 Claude Code 设计「循环(loop)」:让 agent 反复执行工作,直到满足停止条件。
作者开篇点出一个现象:X 上到处在聊「别再一句句提示编码 agent 了,要设计循环」,但你真去找「循环到底是什么」,会看到一堆互相打架的答案。这篇文章要做的,就是把这件事说清楚。
下面按 4 级循环从简单到复杂逐个拆开,每级都能对上你手头的某类活儿。
先搞懂:「循环」到底是什么
官方定义只有一句:循环,就是 agent 反复执行一轮轮工作,直到满足某个停止条件。关键区别在于,「什么时候算完成」是提前定好、交给系统判断的,不是你自己一轮一轮盯着催。
作者按四个维度给循环分类,这四个维度就是后面每种循环的统一参照系:谁触发它、它怎么判断该停、它用 Claude Code 里的哪个功能实现、它最适合什么任务。先把坐标系立起来,四种循环再往里对号入座。
一句提示 → 手动实时 → 到点(时间间隔)→ 事件或排期,全程无人在场
Claude 自己判断 → 达标或到重试上限 → 你取消或活干完 → 每个任务达标退出、整条流水线你手动关
默认对话 → /goal → /loop、/schedule → 以上全部 + dynamic workflows + auto mode
短任务 → 有可验证退出标准的任务 → 周期性或对接外部系统 → 反复出现且定义清晰的工作流
作者也提醒:不是所有任务都需要复杂循环,从最简单的方案起步,这些模式按需选用就好。
你问一句,它做一轮
这就是你每天在用的默认模式。你发的每一条提示,都开启一个由你亲手引导每一轮的循环:Claude 收集上下文、动手、检查自己的工作、必要时重复、然后回复。官方管它叫「agentic loop」。
举个原文的例子:你让 Claude 做一个点赞按钮。它读你的代码、改文件、跑测试,然后交回一个它「自认为」能用的东西。接下来由你手动验收,再写下一条提示。触发它的是一句提示,停下来的判断权在 Claude 自己手里,适合那些不属于固定流程、也不按排期来的短任务。
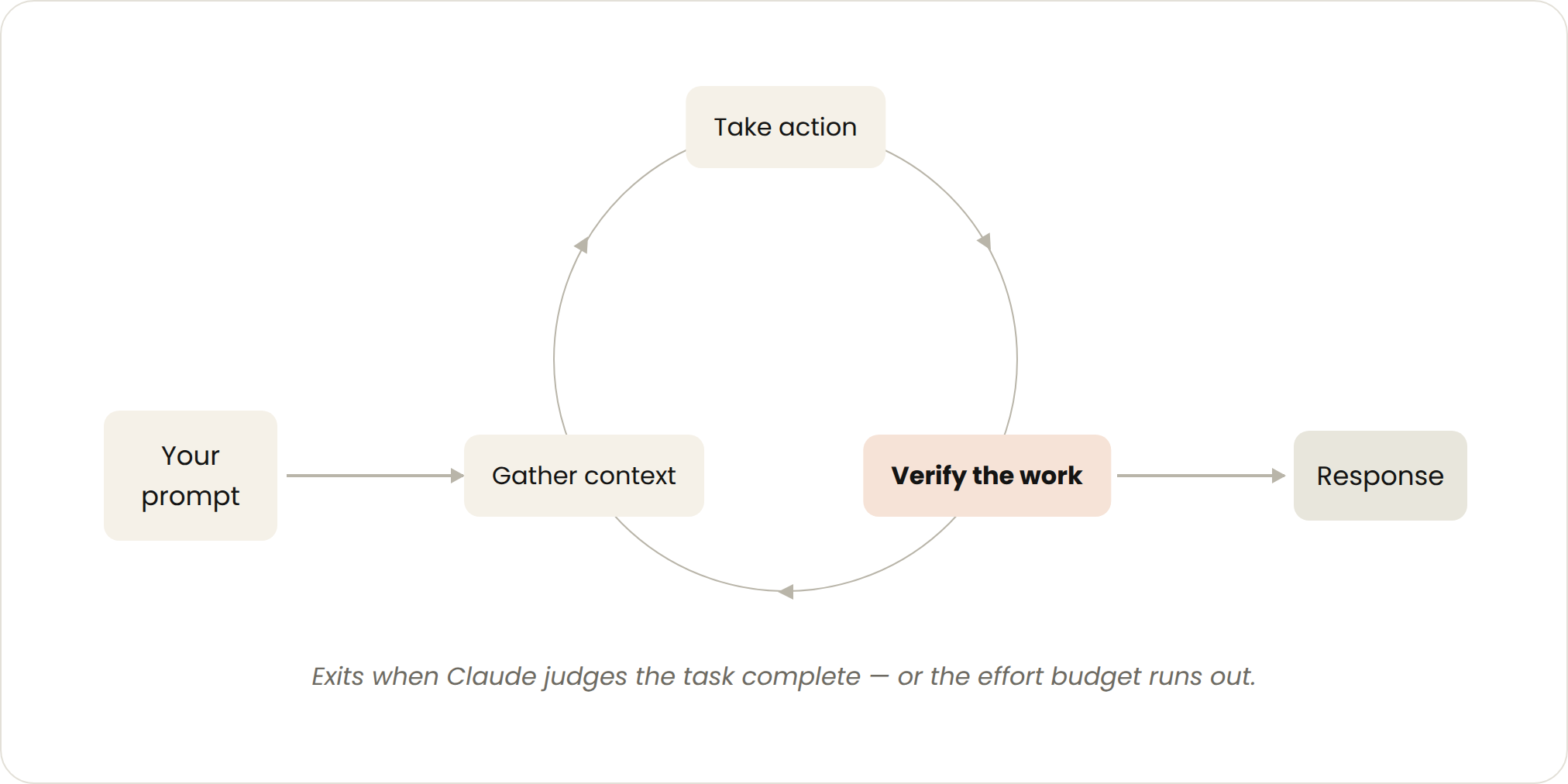
怎么让它自查得更彻底
你可以把「验证」这一步做强:把你平时手动验收的步骤写成一个 SKILL.md,让 Claude 能端到端地自己检查更多东西。关键是给它能看到、量到、动手的工具或连接器:检查越量化,Claude 越容易自我验证,需要的回合数也越少。
原文给了一个 verify-frontend-change 技能:任何前端改动,不许只凭「编辑成功」就报完成,得像人类审查者那样走完整流程。
- 启动 dev server,在浏览器打开改动的页面
- 直接和改动交互:点按钮、确认状态变化、截图前后对比
- 看浏览器控制台:不能有任何新报错或警告
- 用 Chrome DevTools MCP 跑性能 trace,审 Core Web Vitals
任一步失败,就修好后从第 1 步重跑,绝不交半成品。
看原始 SKILL.md 示例代码
--- name: verify-frontend-change description: Verify any UI change end-to-end before declaring it done. --- # Verifying frontend changes Never report a UI change as complete based on a successful edit alone. Verify it the way a human reviewer would: 1. Start the dev server and open the edited page in the browser. 2. Interact with the change directly. For a new control (button, input, toggle): click it, confirm the expected state change, and screenshot before/after. 3. Check the browser console: zero new errors or warnings. 4. Use the Chrome Devtools MCP, run a performance trace and audit Core Web Vitals. If any step fails, fix the issue and rerun from step 1 — do not hand back partially verified work.
先定好「及格线」,它才准停
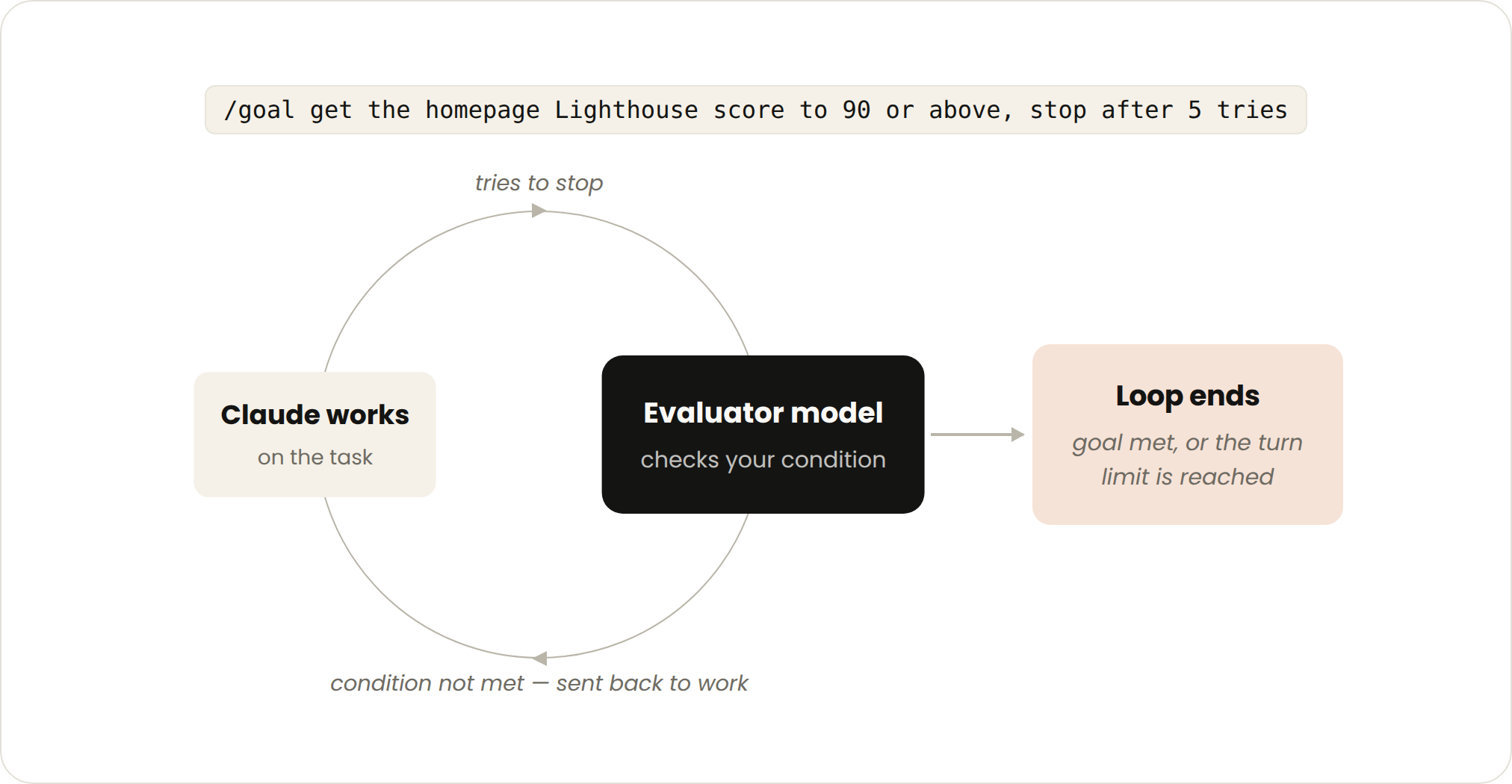
有时候一轮不够,尤其是复杂任务。agent 在能反复迭代时表现更好。你可以用 /goal 把「什么样才算做完」定义清楚,来延长 Claude 迭代的时间。
当你定义了成功标准,Claude 就不用自己去判断「够好了吗」然后提前收工。每次 Claude 想停下来,都有一个独立的评估模型(evaluator)拿着你的条件核对一遍,没达标就把它打回去继续干,直到目标达成、或者到了你设定的尝试次数上限才真正停。
换句话说,判定权从 Claude 手里拿走了,交给一个专门核对标准的评估模型。这也是为什么「确定性标准」特别好使:比如通过的测试数量、清除某个分数阈值,评估模型能明确打勾,不含糊。
像交作业前先过一道质检关卡:质检员不是自己批自己,而是换了个人(评估模型)拿着标准表逐条打勾,不达标就打回重做,最多返工几次为止。
一个具体例子:
/goal get the homepage Lighthouse score to 90 or above, stop after 5 tries.
目标制适合有可验证退出标准的任务;你交出去的是「停止条件」,用的功能就是 /goal。管花销的办法:把完成标准和重试上限都定具体,比如「试 5 次后停」。
到点自己去看一眼
有些活儿是周期性的:任务不变,只有输入在变,比如每天早上汇总一遍 Slack 消息。还有些活儿依赖外部系统,最简单的对接办法就是按固定间隔去查一下、根据变化做出反应,比如一个 PR,它可能收到评审意见、也可能 CI 挂掉。
这类工作用 /loop 触发,它会按间隔重跑一句提示。停下来的条件是你取消它、或者活干完了(PR 合并了、队列空了)。例子:
/loop 5m check my PR, address review comments, and fix failing CI
在你自己的电脑上按固定间隔重跑同一句提示。
你把电脑关了,它就停。适合你人在、临时盯一段的活儿。
用 /schedule 建一个 routine,把这套「定时重跑」搬到云端常驻。
你电脑关了,它照样跑。适合要长期挂着、不受你在不在场影响的活儿。
/loop 5m 每 5 分钟检查一次 PR、处理评审意见、修失败的 CI五个功能拼起来,不用人管自己跑
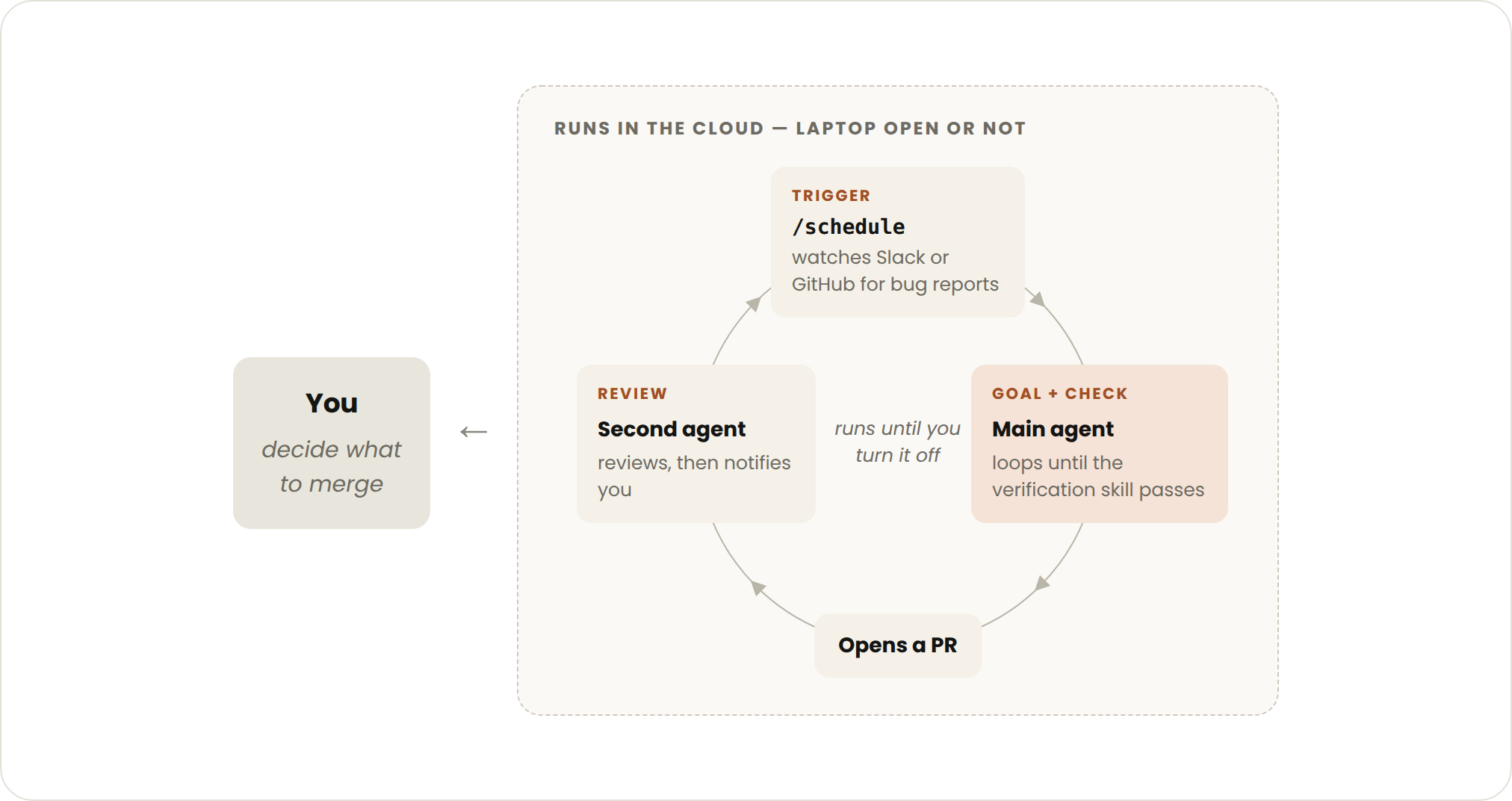
前面几种原语,加上 auto mode(自动模式,不用每步停下来问你要不要继续)和 dynamic workflows(动态工作流,研究预览版),能组合成一条处理长期工作的循环。触发它的是事件或排期,全程没有人实时在场。
主动式循环的停止逻辑分两层:每个具体任务达到自己的目标就退出,而整条 routine 本身会一直跑,直到你手动把它关掉。它最适合那种反复出现、定义清晰的工作流:bug 报告、issue 分诊、迁移、依赖升级等等。
以处理反馈为例,官方给的拼法是把四个功能一层层叠起来,再罩上 auto mode:
拼在一起,一条完整提示长这样:
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.
翻成大白话:每小时去 #project-feedback 频道查 bug 报告;这一轮找到的每一条,不分诊完、处理完、回复完就别停;修某个 bug 时,用一个 workflow 在三个独立分支(worktree)里并行试三种解法,再让一个裁判 agent 对抗式地互相挑错。这里的 dynamic workflows 单次可以拉起量级到数百个的子 agent 分头干活、互相配合。
管花销的办法:把 routine 派给更小更快的模型跑,只在需要判断的关键点上用最强的模型。
别让循环自己跑偏
一个循环的输出质量,取决于它周围那套系统。设计系统时,官方给了四条:
- 保持代码库本身干净
Claude 会照着你代码库里已有的模式和约定走,底子干净,它跟着走出来的东西才干净。
- 给 Claude 一个自查的手段
把「什么样才算好」用 skills 固化成你和团队的标准,让它能端到端检查自己。
- 让文档触手可及
框架和库的官方文档带着最新的最佳实践,别让它凭旧记忆瞎猜。
- 用第二个 agent 做代码审查
一个上下文全新的审查者偏见更少,不受主 agent 推理的影响。可以用内置的
/code-review,或接 GitHub 的 Code Review。
当某一次的结果不达标,别只停在修好这一次的问题。试着把它固化成规则,去改进整个系统,让后面每一轮迭代都受益。出错时该改的是系统规则,不是这一次的结果。
别让循环偷偷烧光你的 token
要管住 token,循环得有清晰的边界。原文给了六条可执行清单:
/usage 按 skills、subagents、MCP 拆解近期用量;/goal 无参数看已用轮数和 token;/workflows 看每个 agent 的用量并可随时停掉。四种循环怎么选,一张表说清
面对一个具体任务,你要想清楚三件事:交出去什么、什么时候用、用哪个功能。原文这张总表把四级循环并成一行行对照,点开每张卡片能看具体示例。
| 循环 | 你交出 | 什么时候用 | 用什么 |
|---|---|---|---|
| 回合制 | 「检查」 | 你在探索或做决定 | 自定义验证 skills |
| 目标制 | 「停止条件」 | 你清楚什么算完成 | /goal |
| 时间制 | 「触发」 | 工作在项目之外按时间表发生 | /loop、/schedule |
| 主动式 | 「提示词」 | 工作反复出现且定义清晰 | 以上全部 + dynamic workflows |
回合制 · 看示例
让 Claude 做个点赞按钮:它读代码、改文件、跑测试、交回一个它自认为能用的版本,你手动验收后再写下一条提示。
目标制 · 看示例
/goal get the homepage Lighthouse score to 90 or above, stop after 5 tries.
时间制 · 看示例
/loop 5m check my PR, address review comments, and fix failing CI
主动式 · 看示例
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.
看你已经在做的活儿,挑一个你是瓶颈的任务,问自己哪一块能交出去:
- 你能不能写出这件事的验收检查?
- 这件事的目标够不够清楚?
- 这活儿是不是按时间表来的?
有了想法就把循环跑起来,观察它在哪儿卡住、在哪儿越界,然后放手去迭代它。
我们把循环定义为:agent 反复执行一轮轮工作,直到满足某个停止条件。 Claude Code 团队,Getting started with loops,2026-06-30